读论文12——NeRF:Representing Scenes as Neural Radiance Fields for View Synthesis
目录
- Abstract
- Introduction
- Related Work
- Neural Radiance Field Scene Representation
- Volume Rendering with Radiance Fields
- Optimizing a Neural Radiance Field
-
- Positional encoding
- Hierachical volume sampling
- Implementation details
- Results
-
- Datasets
- Comparisons
- Discussion
- Ablation studies
- Conclusion
- Apendix
-
- Additional Implementation Details
- Additional Baseline Method Details
- NDC ray space derivation
- Additional Results
- Supplementary knowledge
- 之前用word做的一些笔记
- 手写的一些笔记
Abstract
将场景表示为视图结合的神经辐射场。
提出了一种方法,通过使用稀疏的输入视图集优化基础的连续体积场景函数,从而获得合成复杂场景的新视图的最新结果。
文中的算法提出了使用全连接深度网络的场景,网络的输入是5D坐标,输出是体积密度(透明度吧)和由视角决定的辐射亮度。然后,沿着摄影机方向查询5D坐标合成视图,并用经典的体积渲染技术将输出的颜色和透明度投影到图像中——这样就产生了一张渲染图。
体积渲染自然可微,所以用来优化性能的输入数据,仅仅是一些图片和拍摄这些图片的方向即可。
问题:
view synthesis: 视图合成 currently a study branch of Computer Science Research, aims to create new views of a specific subject staring from a number of pictures taken from given point of views.
Example problem 1: given a number of images of a specific subject, taken from specific points with specific camera setting and orientations, try to build a synthetic image as taken from a virtual camera placed in a different point and with given settings.
Introduction
本工作通过直接优化一个连续5D场景表示的参数来最小化渲染一组图像时带来的错误。
每一个点的透明度(density) 仅仅由它的位置决定,而颜色RGB由方向决定。为了渲染,作者的步骤:
- 照相机的一条光线通过场景可以得到一组采样点。然后我们是需要很多条射线得到很多组采样点。
- 将这些采样点的5D信息输入神经网络,输出每个点的颜色和透明度。(color and density)
- 使用经典的渲染技术将这些颜色、透明度积累到2D图像上,每条射线上的组个点对应图像上的一个像素。
- 利用观察到的图像和渲染生成的图像,使用它们的残差作为损失函数,去优化神经网络。
- 最终我们将得到对本场景有好的渲染能力的模型。
下图有一个很直观的解释:
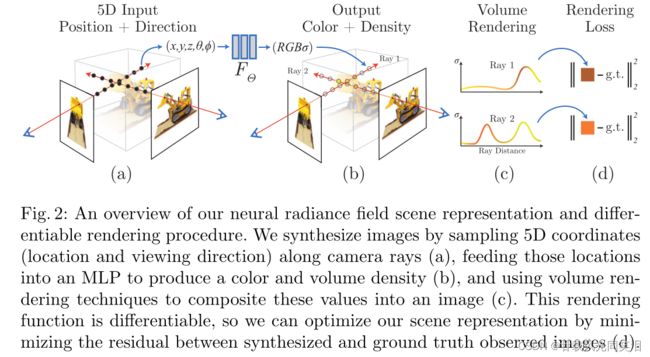
本文的主要技术贡献:
(1)对于有着复杂几何结构和材料的连续场景,提出了一种基于5D神经辐射场的方法进行渲染,用基础的MLP网络进行参数化。
(2)渲染过程是可微的。这是基于传统的体积渲染技术,不过本文做了一定的优化。包括使用分层采样策略来将MLP的容量分配给空间。
(3)使用位置编码技术,将5D坐标映射到高维空间(比如将5D映射到10D?),这样可以优化NeRF,使它能表示高频的场景内容。
Related Work
在计算机视觉领域,一个最新发展方向是使用MLP的权值将实物和场景进行编码。直接将3D空间位置映射到形体的隐式表现(implict representation)。当然,这种方法目前不能将具有复杂几何结构的场景以同样精确度重现。因为重现场景的技术还在使用三角形网格、体素网格这样离散的表示方法。
还有一种被使用到的技术,与MLP的方法类似,用于其他图像表现功能,比如images,textured materials,illumination values。
Neural 3D shape representation:最近的工作研究了将连续的3D形状隐式表现为水平集的方法,该方法通过将xyz坐标映射到符号距离函数来优化深层的神经网络。然而,由于这些模型需要访问地面上的真实几何物体而受限制。不过最近技术的发展放松了对这方面的要求,使用2D图片就可以了。Niemeyer将实物表面表示成3D occupancy fields, 使用数值方法来为每条射线找到和表面的交叉点,然后用隐式微分计算精确导数。每个光线相交位置都作为neural textured fields的输入,然后neural textured fields可以预测该点的漫反射颜色。
有的工作使用了少量的直接neural 3D representation,简单地输出每个连续的3D坐标点的特征向量、RGB值,并且提出了一个可微分绘制(渲染)函数,该函数由一个递归神经网络组成。递归神经网络沿着每条射线行进以确定实物表面的位置。
这种方法有潜力去表现复杂、高分辨率的图像,但是现在还限制在简单的、低几何结构的图像上,结果就是产生了过于光滑的渲染图像。而本文的作者则提出了另一种解决方案,为5D radiance fields编码来优化神经网络,这样可以表现更高分辨率的几何结构和表面,以此为复杂场景渲染照片真实感的新图像。(render photorealistic novel views of complex scenes)。
View synthesis and image-based rendering:如果对一个视图进行密集采样,就可以通过差值的方法来还原真实场景。如果是稀疏采样,则需要通过技术上的预测来还原场景。
一类流行的方法是使用场景的网格表现。一方面,可微的光栅器和路径跟踪器,可以直接优化网格表现,从而利用梯度下降法产生一组新的输入图像。然而,基于图像重投影的gradient-based mesh optimization常常很困难,因为受到局部极小值和的影响。而且,这种策略需要拓扑结构不变的场景,现实生活中没有的。
另一类方法是使用体素表现(volumetric representations)。从而根据输入的一系列RGB图像来生成高质量的photorealistic view synthesis.
早期的体素方法使用oberved images直接绘制voxel girds。最近,有几种方法使用了大规模的、多场景的数据集来训练深层神经网络,利用一组输入图片来预测a sampled volumetric representation;然后在测试环节使用alpha-compositing、learnde compositing去渲染新视图。其他的工作则是优化一组CNN,并为每个场景采样体素网络,这样的话CNN能够补偿低分辨率带来的离散化伪影。
这些基于体素的技术尽管能达到impressive results for novel view synthesis,但是放缩到高分辨率的能力被时间复杂度和空间复杂度限制了。因为它们的采样技术是离散的——而高分辨率的渲染需要对3D空间进行更精细的采样。不过本文则通过在全连接神经网络中为continuous volume 编码来解决此问题, 不仅产生更高质量的渲染结果,而且降低了存储成本。
问题:
(1) implict representations of the shape?
(2) recurrent neural networks? 循环神经网络:输出又会在下一个周期作为输入。
(3) loss landscape:我觉得应该是损失函数的三维表示图,就像是一个景观图
(4) volumetric representations
Neural Radiance Field Scene Representation
就是整个全连接网络的设置。使用一个MLP网络![]()
然后利用每个输入的5D坐标和其对应的透明度和颜色来优化网络的的权重。
透明度 σ \sigma σ仅仅是三维位置的函数,所以鼓励多视角情况下 σ \sigma σ的一致性。而RGB颜色 c c c则是5D输入的函数。MLP结构如下:
先用8个全连接层(使用ReLU激活,每层256个通道)处理3D坐标x,然后输出 σ \sigma σ和一个
256维的特征向量。这个特征向量和照相机射线的视角方向串联起来,被输送到下一个全连接层中,最后的输出就是RGB color。
下面这张图显示了:从不同方向看同一个点,颜色是不一样的。
 下图表示,如果没有视角的两个维度,而只是用3D坐标作为输入,那么模型在输出镜面反射部分的图像时就会效果很差。如果没有位置编码,高频几何特征和纹理得不到体现,产生一个过于光滑的表面。
下图表示,如果没有视角的两个维度,而只是用3D坐标作为输入,那么模型在输出镜面反射部分的图像时就会效果很差。如果没有位置编码,高频几何特征和纹理得不到体现,产生一个过于光滑的表面。
Volume Rendering with Radiance Fields
见手写笔记,简而言之就是利用随机离散采样来计算一条射线的颜色——也就是渲染图像上一个像素点对应的颜色。
这里一个比较吸引我的方法是它的采样方法——在每个小的采样区间里均匀随机采样,从而保证了位置的连续性。
Optimizing a Neural Radiance Field
之前的准备不足以使得网络达到最好的效果。这里需要一点奇技淫巧。作者引入了两个重要的提升来表现高分辨率的复杂场景。第一个是对于输入坐标进行位置编码,帮助MLP逼近为高频函数。第二个是分层采样程序,使得我们可以在高频表现下有效率地采样。
Positional encoding
尽管说,神经网络理论上是可以逼近任意函数的,但是深度神经网络还是更倾向于学习lower-frequency functions.
作者这里将MLP函数 F Θ F_{\Theta} FΘ改写为: F Θ = F Θ ′ ∘ γ F_{\Theta}=F_{\Theta}^{'}\circ \gamma FΘ=FΘ′∘γ.前者是需要学习的,后者不需要。这样做大大提升了性能。这里 γ \gamma γ将一个实数映射到高维空间 R 2 L R^{2L} R2L.这里的编码函数:
![]()
函数 γ \gamma γ分别将x中的三个坐标值(已经先被归一化到[-1, 1]了)映射到L=10的高维,另外两个坐标映射到L=4的高维。
Hierachical volume sampling
由于有大量的空区域和大量被遮挡的区域,所以普通的采样效率很低,会获得大量没意义的点。作者这里提出了分层次体素采样点方法,通过按照采样点对最后渲染结果的影响期望值来采样(意思就是说某个区域的点很重要,那么这个区域就多采样)。
那么如何知道哪些点重要,哪些不重要呢?这里作者决定同时优化两个网络:coarse 和 fine。先按原来的方法取 N c N_c Nc个点,然后丢到coarse网络中训练,让coarse网络输出,我们就能知道一条射线的方向上,哪些区域的点比较重要。将上面那个求某条射线颜色的方程写成:

权重归一化:
然后按照w的权重,采样第二组点 N f N_f Nf个,利用两次采样的所有点来评估fine 网络。这个过程使得我们期待的区域能包含更多可见的信息。
Implementation details
在每一次优化迭代中,随机提取一个batch of camera rays, 然后利用分层提取策略提取每条射线对应的空间中的点,训练 coarse和fine网络。
然后主要就是分析了损失函数:
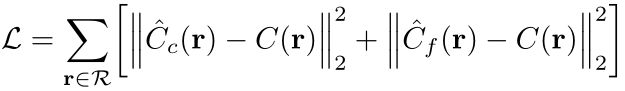
这里为什么还要把coarse网络对应的残差也加上呢?因为coarse网络的优化能帮助fine网络去决定采样哪些点,这点很有意义。
Results
Datasets
包括Synthetic renderings of objects 和Real images from complex scenes.从下表中可以看出,本文的方法在三种数据集上都会优于SRN、NV、LLFF这三种被用来比较的方法。
Comparisons
讲了三种被用来比较的方法。
Neural Volumes(NV):为一个完全躺在有边界的场景中的物体合成新的视图。然后NV是优化一个深度的3D CNN。用 12 8 3 128^3 1283个阳历来预测离散的 R G B α RGB\alpha RGBα体素网格。
Scene Representation Networks(SRN):将一个连续场景表现为不透明表面,隐式地使用MLP,将xyz坐标映射成特征向量。然后训练循环神经网络。
Local Light Field Fusion(LLFF):为精心采样的前向场景产生photorealistic novel views。使用训练好的3D CNN去直接为每个输入图像预测一个discretized frustum-sampled R G B α RGB\alpha RGBα网格。
Discussion
SRN产生的图像过于平滑(从下面的两张图可以看出,一团糊),表现能力受限。NV无法达到高的分辨率(也比较糊,比SRN好一点)。LLFF常常无法正确估计合成数据集的几何图形。这些方法都面临时间和空间的trade-off的问题。它们或者需要很长时间去训练,或者需要占用大量空间。
下面两张图是四种方法在实际场景、合成场景下的表现:


Ablation studies
烧蚀研究,去掉部分操作再看效果,就可以研究这些操作的效果。
 这张表说明了前面提到的位置编码、视角依赖、分层采样都很重要。图像集不能太小。位置编码升维的时候,L要选择合适。
这张表说明了前面提到的位置编码、视角依赖、分层采样都很重要。图像集不能太小。位置编码升维的时候,L要选择合适。
Conclusion
(我这里就翻译一下)
我们的工作直接解决了以前使用MLP将对象和场景表示为连续函数的工作的不足。我们证明,将场景表示为5D神经辐射场(一种输出体积密度和视情况而定的发射辐射作为3D位置和2D观察方向的函数的MLP)比以前主要的训练深度卷积网络以输出离散体素表示的方法产生更好的渲染效果。虽然我们已经提出了一种分层采样策略,以使渲染更有效(用于训练和测试),但在研究有效优化和渲染神经辐射场的技术方面仍有更多的进展。未来工作的另一个方向是可解释性:体素网格和网格等采样表示允许对渲染视图的预期质量和故障模式进行推理,但当我们使用深度神经网络的权重对场景进行编码时,尚不清楚如何分析这些问题。我们相信,这项工作在基于真实世界图像的图形管道方面取得了进展,其中复杂场景可以由从实际对象和场景的图像优化的神经辐射场组成。
Apendix
Additional Implementation Details
Additional Baseline Method Details
NDC ray space derivation
Additional Results
Supplementary knowledge
之前用word做的一些笔记
NeRF是用来做计算机渲染的。
渲染:用计算机模拟照相机拍照,它们的结果都是生成一张照片。
拍照的对象:自然界中的物体。形成照片的机制主要就是光经过镜头到传感器被记录下来。
渲染的拍照对象是已存在的某种三维场景表示(3D representation of the scene),形成照片的机制是图形学研究人员精心设计的算法。
隐式场景表示(implicit scene representation)
基于深度学习的渲染的先驱是使用神经网络隐式表示三维场景。 许多3D-aware的图像生成方法使用体素、网格、点云等形式表示三维场景,通常基于卷积架构。 但在 CVPR 2019 上,开始出现使用神经网络拟合标量函数来表示三维场景的工作。
NeRF是一种隐式的三维场景表示,所以不能直接像点云一样看见一个三维模型。




3D视觉:
我们生活在三维空间中,如何智能地感知和探索外部环境一直是个热点课题。2D 视觉技术借助强大的计算机视觉和深度学习算法取得了超越人类认知的成就,而 3D 视觉则因为算法建模和环境依赖等问题,一直处于正在研究的前沿,而三维信息才真正能够反映物体和环境的状态,也更接近人类的感知模式。
随着技术的不断进步,三维视觉领域也取得了快速进步,例如 3D+AI 识别功能,扫描人脸三维结构完成手机解锁;自动驾驶领域通过分析 3D 人脸信息,判断司机驾驶时的情绪状态;SLAM 通过重建周边环境,完成建图与感知;
与二维图像类似,三维图像是在二维彩色图像的基础上又多了一个维度,即深度(Depth,D),可用一个很直观的公式表示为:三维图像 = 普通的 RGB 三通道彩色图像 + Depth Map。
深度图是三维图像特有的,是指存储每个像素所用的位数,也用于度量图像的色彩分辨率。确定彩色图像每个像素可能有的颜色数,或者确定灰度图像每个像素可能有的灰度级数。它决定了彩色图像中可出现的最多颜色数,或灰度图像中的最大灰度等级。其数值是规整的,适合直接用于现存的图像处理框架。
关于深度图的解释,例如,一幅彩色图像的每个像素用 R、G、B 三个分量表示,若每个分量用 8 位,那么一个像素共用 24 位表示,那么像素的深度为 24,则每个像素可以是 16777216(224) 种颜色中的一种。因此,可以把像素深度理解成是深度图像距离值。表示一个像素的位数越多,它能表达的颜色数目就越多,而它的深度就越深。
3D 目标检测多模态融合算法
3D 人脸检测基本流程
人脸识别技术在国家安全、军事安全、金融安全、共同安全等领域具有广泛的应用前景。人的大脑具备天生的人脸识别能力,可以轻易地分辨出不同的人。但是计算机自动识别人脸技术却面临着巨大的挑战。由于二维人脸识别不可避免地受到光照、姿态和表情的影响,这些因素已成为二维人脸识别技术向前发展的最大障碍。
随着结构光和立体视觉等三维成像技术的日益成熟,越来越多的人脸识别研究人员将目光投向了三维人脸识别技术领域。
目前 3D 人脸识别技术的主要技术流程如下:
• (1) 3D 人脸数据获取;
• (2) 3D 人脸数据的预处理,包括人脸的检测、切割、去噪等;
• (3) 3D 人脸数据的特征提取;
• (4) 构建适合的分类器对人脸数据进行判别。
面部 3D 重建
人脸重建是计算机视觉领域中一个比较热门的方向,3D 人脸相关应用也是近年来短视频领域的新玩法。不管是 Facebook 收购的 MSQRD,还是 Apple 研发的 Animoji,底层技术都与三维人脸重建有关。

体积渲染技术:
参考文献:
https://zhuanlan.zhihu.com/p/390848839
(NeRF的介绍)
[1] https://mp.weixin.qq.com/s?__biz=MzA3MzI4MjgzMw==&mid=2650803376&idx=3&sn=7d7cca1f447aaee307c1b8aa2e2f6e9f&chksm=84e5c8ceb39241d8b5a7f4e76f1fbc9a7d5284fcce4a6963f82fef6590baff39ab5c6bced5db&scene=21#wechat_redirect
(计算机如何看这个三维世界)
[2] 3D视觉:一张图像如何看出3D效果?
https://zhuanlan.zhihu.com/p/315772436
[3] https://zhuanlan.zhihu.com/p/360365941
(【NeRF论文笔记】用于视图合成的神经辐射场技术)
手写的一些笔记


