
基于摄像头的车道线检测方法一览
车道线,重要的路上语义信息,检测车道线对L2-L3-L4级别的自动驾驶系统都是重要的。
基本方法也可以分成:一传统方法;二深度学习方法。
一般车道线检测系统多是基于单目图像,早期算法多是传统方法。基本上分成几个模块:图像清理(障碍物遮挡检测,阴影消除,曝光矫正),特征提取(道路/车道线检测),道路/车道线模型拟合(横向/纵向),时域整合(前后帧)和图像-物理空间(路面坐标系)的对应等。
"A Learning Approach Towards Detection and Tracking of Lane Markings"




“Real time Detection of Lane Markers in Urban Streets“






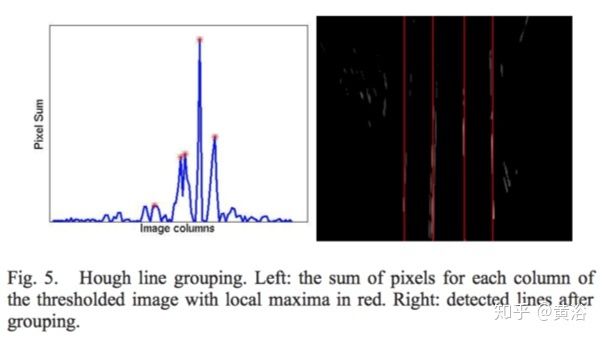





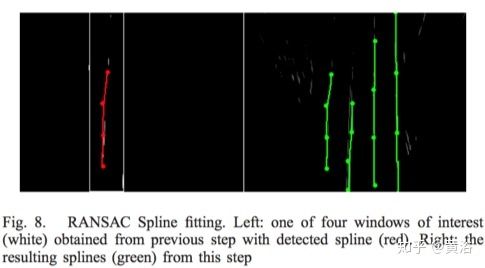





“New Lane Model and Distance Transform for Lane Detection and Tracking“
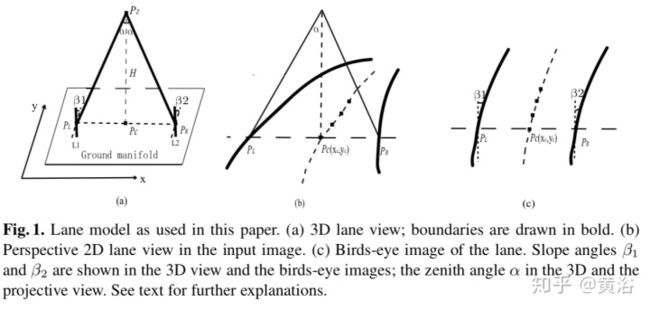







"Multiple Lane Detection Algorithm Based on Optimized Dense Disparity Map Estimation"
这里重点介绍采用立体视觉(即双目)的一个方法,其优点是可以利用视差信息。如图是其算法框架,双目特征点提取和匹配之后估计路面方程,计算视差(disparity)图以及消失点(平行线原理),之后再提取车道线。在提取视差的算法中,视差范围是一个敏感的指标,这里通过道路平面的估计可以得到一个合理的视差范围,随后再反馈到视差计算模块中,这样可以优化算法。


视差计算分两步,第一步是基于特征点匹配的稀疏视差,其中特征点采用SURF (Speeded-Up Robust Features) 和 SIFT (Scale Invariant Feature Transform);第二步基于动态规划(Dynamic Programming,DP)将稀疏视差内插变成致密视差图。
车道线的提取也是采用动态规划算法,只是利用的线索是消失点和图像提取的边缘。消失点估计的算法是基于动态规划方法,其中逐行(horizontal band)检测地平线(horizon line),利用的信息是路面视差和边缘,而消失点是车道法线和地平线的交点,然后全局优化得到最佳估计。车道线检测是来自于消失点,后者给出了车道线的方向和曲率,最后估计车道线的位置是通过估计其中心线的水平偏移(lateral offset)得到,为此,设计一个1D累加器,每行的提取边缘参与似然函数的计算。由于车道线“暗-亮-暗”变化特点,车道线投影会构成一个“加-减”峰值对。


"Real-Time Stereo Vision-Based Lane Detection System"


(a) 道路平面估计(视差图像得到),绿色显示. (b) 图像(a)的 Bilateral filtering 结果. (c) 图像(a)的 Sobel 边缘检测结果. (d) 图像(b)的边缘检测结果. (e) median filtering 结果. (f) 路面上图像边缘结果。


“An Empirical Evaluation of Deep Learning on Highway Driving“











“Real-Time Lane Estimation using Deep Features and Extra Trees Regression“
这个工作利用学习的CNN模型预测图像中车道线位置,特别是在遮挡或者缺失情况下。其基本思路是通过CNN能够从道路图像中提取鲁棒特征,然后训练一个附加的树状回归模型 从特征直接估计车道线位置。这里左右车道线上的图像点,对应Bezier spline的控制点。
下图是模型训练的流程图。

 training
training
而这个图是模型测试的流程图。
为了提取道路相关的特征,CNN模型需要用新道路数据调整一下(即所谓的迁移学习),而最后的输出变成了一个二值分类器。树状回归网络是随机森林(random forest)模型的扩展。一些道路图像数据的例子见图5-194所示,其中(a-b) 曲线, (c) 阴影, (d) 阴影和缺失. (e-f) 部分遮挡, (g) 部分遮挡, 不同颜色的路面造成缺失, (h) 遮挡和缺失 (i-l) 缺失。

 testing
testing 



“Accurate and Robust Lane Detection based on Dual-View Convolutional Neutral Network“
该工作提出了一个双视角(前视和顶视)CNN模型做车道线检测,称为Dual-View Convolutional Neutral Network (DVCNN) 。前视图像能够剔除运动车辆,栅栏和路边界造成的误判,而顶视图像通过IPM得到,它能去除杆状的结构,如道路上箭头和字符。


DVCNN结构见下图所示,最后一步是一个全局优化,得到提取的车道线。


“DeepLanes: E2E Lane Position Estimation using Deep NNs“




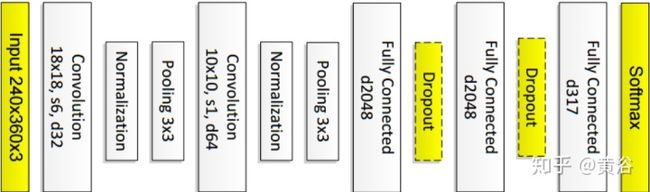

“Deep Neural Network for Structural Prediction and Lane Detection in Traffic Scene“



 Applying RNN detector on road surface image
Applying RNN detector on road surface image 

”End-to-End Ego Lane Estimation based on Sequential Transfer Learning for Self-Driving Cars“
这个方法采用串行的端到端(end-to-end)迁移学习直接估计和分离车道左右线。为此,搜集了一个包括多种道路状况的数据集训练CNN模型。下图是系统流程图,前部分是迁移学习带来的VGG预训练网络(训练数据ImageNet)串行地对称成为一个逆卷积网络(deconvolution network)直接做场景分割,其结果变成一个道路场景的理解;后部分是通过训练的调整网络将道路场景转换成车道的左右线输出。








”Deep Learning Lane Marker Segmentation From Automatically Generated Labels“


 pose vertices (blue),GPS edges (yellow),lane marker (green),lane map (thick solid black).
pose vertices (blue),GPS edges (yellow),lane marker (green),lane map (thick solid black). 
 projected map lane markers (blue) and the detected lane markers (green).
projected map lane markers (blue) and the detected lane markers (green).
”VPGNet: Vanishing Point Guided Network for Lane and Road Marking Detection and Recognition“
VPGNet是基于消失点原理的端到端训练出来的多任务神经网络,可以同时处理车道线和道路标记。为此作者建立一个道路和车道线标记数据库,包括各种交通条件,比如下雨/无雨/大雨/夜晚。




”Spatial as Deep: Spatial CNN for Traffic Scene Understanding“
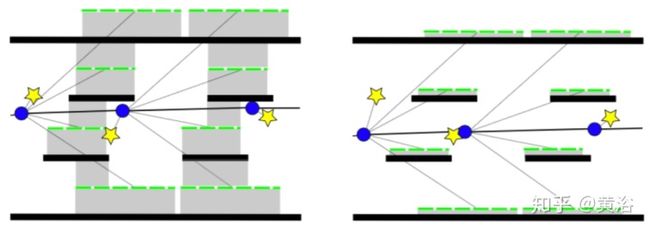
虽然CNN模型可以很容易提取像素中的语义信息,但像素在行和列的空间关系却没有完全挖掘出来。 为了学习带有强烈形状先验知识但薄弱的表观连贯性的语义目标,比如路面上遮挡的甚至缺失的交通车道线,空间CNN (SCNN)模型在特征图中扩展层结构(layer-by-layer)的卷积为片结构(slice-by- slice )卷积,这样像素之间信息传递(message passings)在每层的行-列进行。SCNN特别适合带有强空间关系但缺表观线索的长条连续形状结构或者大型目标,比如车道线,墙和杆子/柱子等目标。

 Comparison btw CNN and SCNN
Comparison btw CNN and SCNN 
 MRF/CRF &amp;amp;amp; SCNN
MRF/CRF &amp;amp;amp; SCNN 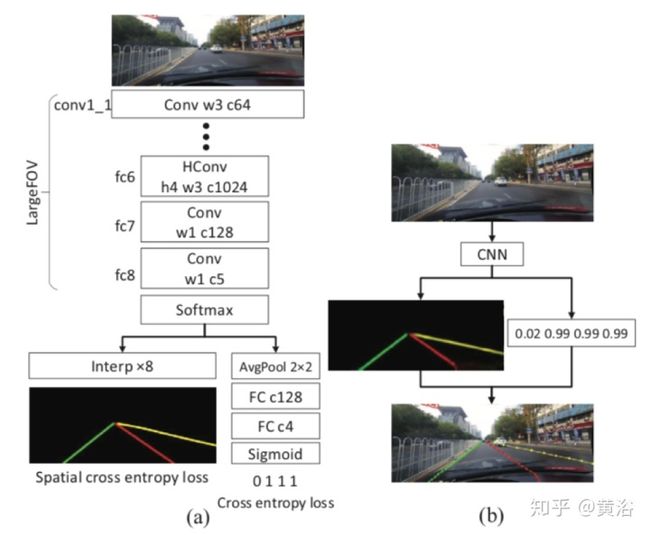
 Training model &amp;amp;amp; Lane prediction
Training model &amp;amp;amp; Lane prediction 
 baseline, ReNet, MRFNet, ResNet-101, and SCNN
baseline, ReNet, MRFNet, ResNet-101, and SCNN
”Towards End-to-End Lane Detection: an Instance Segmentation Approach“
这里提出一个实例分割方法处理车道线检测,这样每个车道构成各自的实例,模型可以端到端训练。 在车道拟合之前,为参数化分割的车道实例,采用一个从图像中学习的透视变换,对车道变化适应性强。
下图是系统流程图。输入图像,LaneNet 输出车道线实例图,标记车道线像素的车道#ID。然后车道像素通过一个透视转换矩阵(Homography)H-Net,最后每个车道拟合成3-阶多项式,然后再投影到图像上。


它采用了前面提到的LaneNet结构,基于一个基于编码器-解码器的网络结构ENet, 其修正为一个双分支神经网络,如下图所示:一是分割,输出二值的车道掩码;另一个 是流形嵌入分支(manifold embedding),每个车道像素产生一个N-维嵌入向量,这样同一车道的嵌入很接近,而不同车道的嵌入就远离。从分割分支出来的二值分割掩码掉背景,剩下的是像素车道嵌入,它们聚类在一起得到聚类中心,即检测的车道线。




”LaneNet: Real-Time Lane Detection Networks for Autonomous Driving“
这篇文章提出了一个神经网络LaneNet,车道线检测被分成两个步骤,而图5-207是两个步骤的神经网络结构:车道边缘提议(lane edge proposal )网络,实际是一个编码器-解码器(编码器是卷积层构建,解码器由逆卷积层Deconvolution layers构成,并采用跳线Skip Connections)网络;车道线定位(lane line localization)网络也是编码器-解码器结构,利用前一个网络输出的车道线边缘作为输入,一组1-D卷积编码后通过一组LSTM(Long Short Term Memory)解码器逐步得到车道线参数作为结果。




第一步输入是通过变换Inverse Perspective Mapping (IPM)的图像,输出是像素级车道边缘分类,通过一个高分辨率的特征图产生像素级边缘概率图作为车道线的可信度。第二步基于车道边缘提议检测出车道线作为输出。困难的地方是如何减少路上类似车道线的标记比如箭头和字符等造成的误检。该方法无需假设车道线的种类数,而且计算量小,速度快。图5-208是实验结果例子。


“3D-LaneNet: E2E 3D multiple lane detection“
这个方法比较特别,网络直接从单目图像的道路场景中输出3-D车道线。3D-LaneNet, 利用了两个概念:网络内inverse-perspective mapping (IPM) ,基于锚(anchor)的车道线表示;前者方便一种双重表示,即前视和顶视的信息流;后者的逐列输出促使端到端方法。最后输出的是每个纵向路片(longitudinal road slice),车道线通过该路片的可信度及其3-D曲线坐标。这样的结果,类似基于锚的单步目标检测方法,如SSD和YOLO。优点是,它明确地处理好车道线合并和分离的情况。




下图是一个双重上下文(dual context)模块:架构中主要的积木是投影变换层(projective transformation layer),一种空间变换(spatial transformer)模块的变型。输入的特征图可微分采样,空间上对应前视图像平面,输出的是空间上对应“虚拟”顶视图的特征图(注:可微分采样的实现通过一个网格法)。这个双重上下文模块,利用投影变换层来建立高度描述性的特征图,其中两个多通道特征图的信息流分别对应前视和顶视图像。

 The dual context module.
The dual context module.
下面是3D-LaneNet的结构图:两个平行信息流,前视和顶视,即双路核心。前视流会处理和保持图像的信息,而顶视流提供平移不变性的特征并预测3-D车道线检测的输出。前者基于VGG16 ,后者类似。信息从前视流向顶视靠的是4个转换层,其中加一个降维层 (1×1 convolution) 在除了第一个的所以双重上下文模块里。前视图像流网络的第一个中间输出是“道路投影平面(road projection plane)”。端到端方法的核心是基于锚的车道表示,图5-216是输出的结果表示:每个锚,网络输出3种车道描述 (可信度和几何), t头两个(c1, c2) 表示车道中心线,第三个 (d) 是车道分割线。每个锚指定两个可能的中心线,而车道分割符(lane delimiters)与中心线相比要复杂的多。图5-217是一些合成图像的实验结果例子。

 3D-LaneNet network architecture.
3D-LaneNet network architecture. 
 Output representation
Output representation 

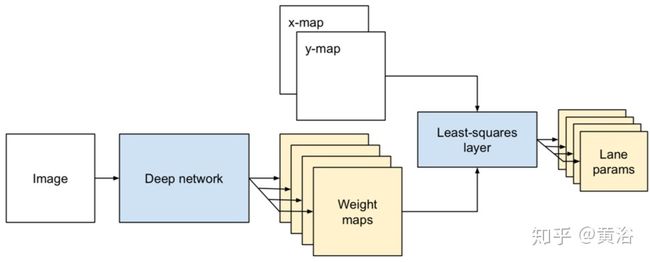
”End-to-end Lane Detection through Differentiable Least-Squares Fitting“
这里的方法是一种端到端训练的方法,直接回归车道线参数,其结构包括两个组件:一个网络预测每个车道线类似分割的权值图,一个可差分最小二乘拟合模块给每个权值图返回一个加权最小二乘最佳曲线拟合的参数。





”Robust Lane Detection from Continuous Driving Scenes Using Deep Neural Networks“
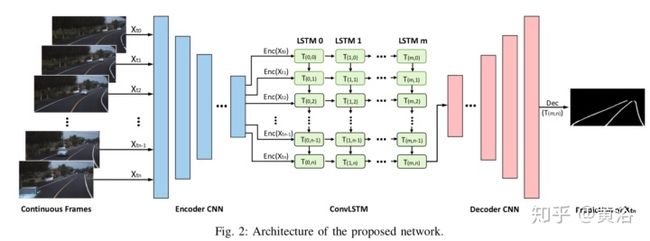







”End to End Video Segmentation for Driving : Lane Detection For Autonomous Car“
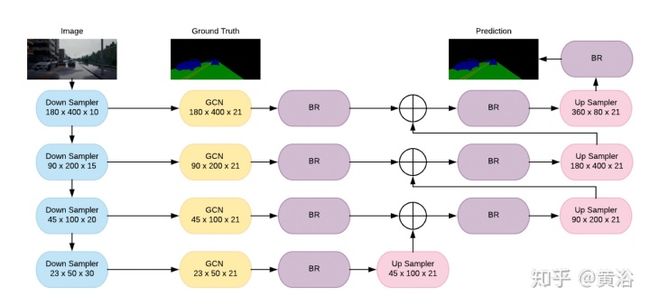

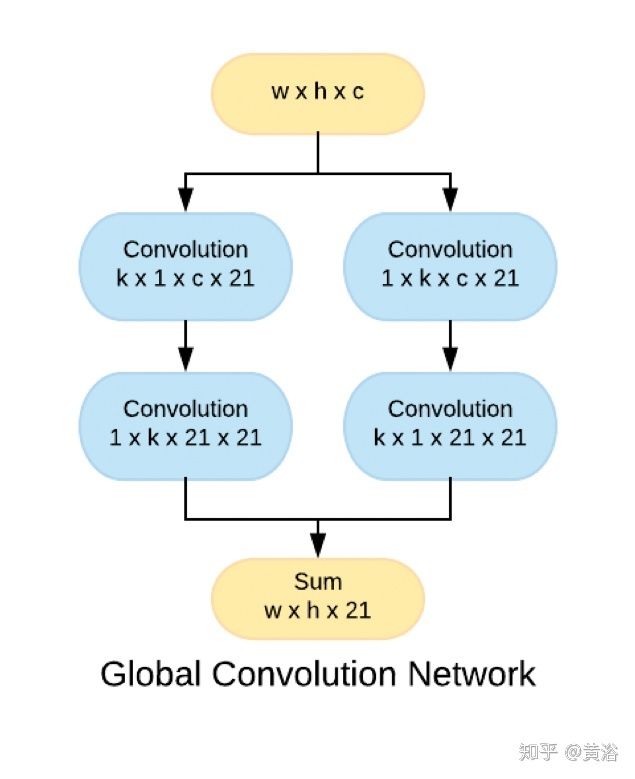





”Efficient Road Lane Marking Detection with Deep Learning“
车道线检测器 (LMD) ,其流程图如图5-220,定义了一个浅细的CNN模型减少计算量,并用来提取车道特征,后处理包括聚类和拟合。聚类方法分两步:1. 聚类同一个车道线段(lane segment)的临近像素 形成超标记(supermarking);2. 连接属于同一个车道线标记的超标记。拟合包括直线段和曲线,三阶多项式模型拟合弯曲的车道。

 Flowchart of the proposed LMD system.
Flowchart of the proposed LMD system. 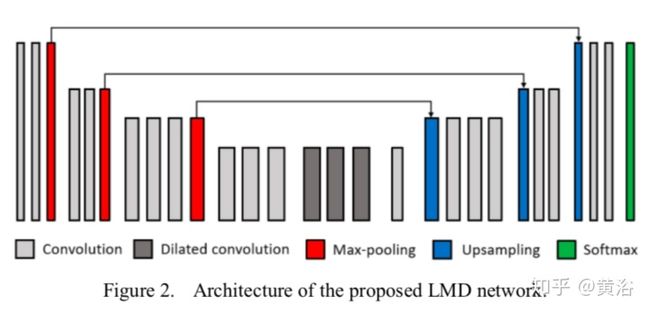



”LineNet: a Zoomable CNN for Crowdsourced High Definition Maps Modeling in Urban Environments“





 Different branches’ outputs of the LP layer, with two samples.
Different branches’ outputs of the LP layer, with two samples. 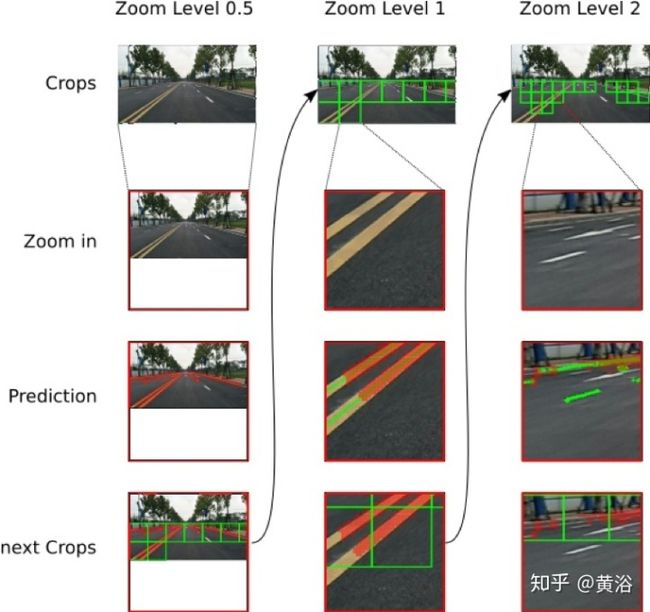
 zooming process
zooming process 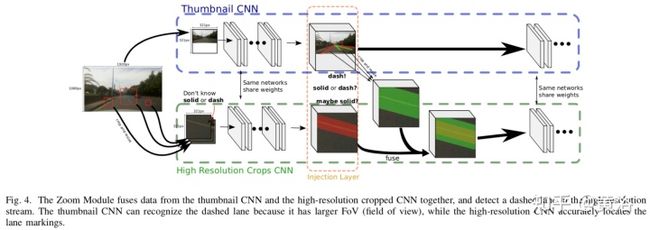


 Line points are gradually clustered together from near to far.
Line points are gradually clustered together from near to far.
"Lane Marking Quality Assessment for Autonomous Driving"








"A Dataset for Lane Instance Segmentation in Urban Environments"
























"Semantic Classification of Road Markings from Geometric Primitives"














。。。待续。。。



40 条评论
和评论区一些回答有同感,paper很多,能用的很少。
太厉害了
那实际上的工业应用该是如何的,设计特有的算法吗,我认识的包括网上所有的文章都是相似的套路(二值化(阈值+边缘),ROI,曲线/直线拟合),传统图像处理算法就那几种,处理流程套路相似,那学生与开发人员的差别在哪里?希望得到答复,多谢多谢
检测的效果咋样呢?
cool
感谢分享!论文这么多,哪个效果最好,或者有能达到实时检测的吗,有大神告知下?
自己研究了大半年车道线,感觉车道线的相关论文脱离工业界太远(国外的mobile-eye,国内的极目效果都是不错的,超出这些论文不知道多少倍),论文基本没有能实用的,三星的VPGNET给出的视频感觉不错,但是在titanX上也只有25-30fps左右。本人开发了一款车道线检测算法,https://youtu.be/bvgiqE4VOIQ,速度在RK3399上面能达到100fps/s,供大家欣赏吧
可以了解一下 https://www.youtube.com/watch?v=MdZrCuoGJSA
https://arxiv.org/pdf/1807.05696.pdf