shape_based_matching代码解读0422
写作本系列文章旨在就个人学习该论文及其开源项目做一个学习分享和交流。
原论文篇名:Gradient Response Maps for Real-TimeDetection of Textureless Objects
原论文地址:https://www.researchgate.net/publication/312945559_Gradient_Response_Maps_for_Real-Time_Detection_of_Textureless_Objects
原项目地址:https://github.com/meiqua/shape_based_matching
本人于VS2017+OpenCV3.4.16编译的工程项目:https://download.csdn.net/download/weixin_41864918/85189757
一、制作预响应表
1、论文分析
 根据像素方向的二进制表示可以知道当前像素位置中是否存在该梯度方向。
根据像素方向的二进制表示可以知道当前像素位置中是否存在该梯度方向。
比如图片中当前的二进制数为11010,五位分别代表着不同的梯度方向。
| 从左往右 | 梯度方向 |
|---|---|
| 1 | ← |
| 1 | ↖ |
| 0 | ↑ |
| 1 | ↗ |
| 0 | → |
为了在程序执行时,高效算出图像的相似度,采用查找表的方式。
制作查找表(以五个梯度方向举例):五位二进制可以计算得知有32个方向组合,每个方向制作一个预响应表,需要对每个方向同方向组合进行计算,那么需要制作一个大小为(32*5)的数组去枚举每一梯度方向的打分情况。

由此,制作一个分值响应表,可以高效的计算某一像素位置获取的分值,那么将输入图像的相似度量就可以用计算像素分值之和替代,分值高的即为相似度高的匹配项。
2、代码分析
了解了算法思路,去理解代码逻辑就相对简单一些。
先贴源码
static const unsigned char LUT3 = 3;
// 1,2-->0 3-->LUT3,
CV_DECL_ALIGNED(16)
static const unsigned char SIMILARITY_LUT[256] = {0, 4, LUT3, 4, 0, 4, LUT3, 4, 0, 4, LUT3, 4, 0, 4, LUT3, 4, 0, 0, 0, 0, 0, 0, 0, 0, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, 0, LUT3, 4, 4, LUT3, LUT3, 4, 4, 0, LUT3, 4, 4, LUT3, LUT3, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, LUT3, LUT3, 4, 4, 4, 4, LUT3, LUT3, LUT3, LUT3, 4, 4, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, LUT3, LUT3, LUT3, LUT3, 4, 4, 4, 4, 4, 4, 4, 4, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, 0, 0, 0, 0, 0, 0, 0, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, 0, 4, LUT3, 4, 0, 4, LUT3, 4, 0, 4, LUT3, 4, 0, 4, LUT3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, LUT3, 4, 4, LUT3, LUT3, 4, 4, 0, LUT3, 4, 4, LUT3, LUT3, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, LUT3, LUT3, 4, 4, 4, 4, LUT3, LUT3, LUT3, LUT3, 4, 4, 4, 4, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, 0, 0, 0, LUT3, LUT3, LUT3, LUT3, 4, 4, 4, 4, 4, 4, 4, 4};
static void computeResponseMaps(const Mat &src, std::vector<Mat> &response_maps)
{
CV_Assert((src.rows * src.cols) % 16 == 0);
// Allocate response maps
response_maps.resize(8);
for (int i = 0; i < 8; ++i)
response_maps[i].create(src.size(), CV_8U);
Mat lsb4(src.size(), CV_8U);
Mat msb4(src.size(), CV_8U);
for (int r = 0; r < src.rows; ++r)
{
const uchar *src_r = src.ptr(r);
uchar *lsb4_r = lsb4.ptr(r);
uchar *msb4_r = msb4.ptr(r);
for (int c = 0; c < src.cols; ++c)
{
// Least significant 4 bits of spread image pixel
lsb4_r[c] = src_r[c] & 15;
// Most significant 4 bits, right-shifted to be in [0, 16)
msb4_r[c] = (src_r[c] & 240) >> 4;
}
}
{
uchar *lsb4_data = lsb4.ptr<uchar>();
uchar *msb4_data = msb4.ptr<uchar>();
bool no_max = true;
bool no_shuff = true;
#ifdef has_max_int8_t
no_max = false;
#endif
#ifdef has_shuff_int8_t
no_shuff = false;
#endif
// LUT is designed for 128 bits SIMD, so quite triky for others
// For each of the 8 quantized orientations...
for (int ori = 0; ori < 8; ++ori){
uchar *map_data = response_maps[ori].ptr<uchar>();
const uchar *lut_low = SIMILARITY_LUT + 32 * ori;
if(mipp::N<uint8_t>() == 1 || no_max || no_shuff){ // no SIMD
for (int i = 0; i < src.rows * src.cols; ++i)
map_data[i] = std::max(lut_low[lsb4_data[i]], lut_low[msb4_data[i] + 16]);
}
else if(mipp::N<uint8_t>() == 16){ // 128 SIMD, no add base
const uchar *lut_low = SIMILARITY_LUT + 32 * ori;
mipp::Reg<uint8_t> lut_low_v((uint8_t*)lut_low);
mipp::Reg<uint8_t> lut_high_v((uint8_t*)lut_low + 16);
for (int i = 0; i < src.rows * src.cols; i += mipp::N<uint8_t>()){
mipp::Reg<uint8_t> low_mask((uint8_t*)lsb4_data + i);
mipp::Reg<uint8_t> high_mask((uint8_t*)msb4_data + i);
mipp::Reg<uint8_t> low_res = mipp::shuff(lut_low_v, low_mask);
mipp::Reg<uint8_t> high_res = mipp::shuff(lut_high_v, high_mask);
mipp::Reg<uint8_t> result = mipp::max(low_res, high_res);
result.store((uint8_t*)map_data + i);
}
}
else if(mipp::N<uint8_t>() == 16 || mipp::N<uint8_t>() == 32
|| mipp::N<uint8_t>() == 64){ //128 256 512 SIMD
CV_Assert((src.rows * src.cols) % mipp::N<uint8_t>() == 0);
uint8_t lut_temp[mipp::N<uint8_t>()] = {0};
for(int slice=0; slice<mipp::N<uint8_t>()/16; slice++){
std::copy_n(lut_low, 16, lut_temp+slice*16);
}
mipp::Reg<uint8_t> lut_low_v(lut_temp);
uint8_t base_add_array[mipp::N<uint8_t>()] = {0};
for(uint8_t slice=0; slice<mipp::N<uint8_t>(); slice+=16){
std::copy_n(lut_low+16, 16, lut_temp+slice);
std::fill_n(base_add_array+slice, 16, slice);
}
mipp::Reg<uint8_t> base_add(base_add_array);
mipp::Reg<uint8_t> lut_high_v(lut_temp);
for (int i = 0; i < src.rows * src.cols; i += mipp::N<uint8_t>()){
mipp::Reg<uint8_t> mask_low_v((uint8_t*)lsb4_data+i);
mipp::Reg<uint8_t> mask_high_v((uint8_t*)msb4_data+i);
mask_low_v += base_add;
mask_high_v += base_add;
mipp::Reg<uint8_t> shuff_low_result = mipp::shuff(lut_low_v, mask_low_v);
mipp::Reg<uint8_t> shuff_high_result = mipp::shuff(lut_high_v, mask_high_v);
mipp::Reg<uint8_t> result = mipp::max(shuff_low_result, shuff_high_result);
result.store((uint8_t*)map_data + i);
}
}
else
{
for (int i = 0; i < src.rows * src.cols; ++i)
map_data[i] = std::max(lut_low[lsb4_data[i]], lut_low[msb4_data[i] + 16]);
}
}
}
}
1.1、制作快速查找表
static const unsigned char LUT3 = 3;
// 1,2-->0 3-->LUT3,
CV_DECL_ALIGNED(16)
static const unsigned char SIMILARITY_LUT[256] = {0, 4, LUT3, 4, 0, 4, LUT3, 4, 0, 4, LUT3, 4, 0, 4, LUT3, 4, 0, 0, 0, 0, 0, 0, 0, 0, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, 0, LUT3, 4, 4, LUT3, LUT3, 4, 4, 0, LUT3, 4, 4, LUT3, LUT3, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, LUT3, LUT3, 4, 4, 4, 4, LUT3, LUT3, LUT3, LUT3, 4, 4, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, LUT3, LUT3, LUT3, LUT3, 4, 4, 4, 4, 4, 4, 4, 4, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, 0, 0, 0, 0, 0, 0, 0, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, 0, 4, LUT3, 4, 0, 4, LUT3, 4, 0, 4, LUT3, 4, 0, 4, LUT3, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, LUT3, 4, 4, LUT3, LUT3, 4, 4, 0, LUT3, 4, 4, LUT3, LUT3, 4, 4, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, 0, LUT3, LUT3, 4, 4, 4, 4, LUT3, LUT3, LUT3, LUT3, 4, 4, 4, 4, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3, 0, 0, 0, 0, LUT3, LUT3, LUT3, LUT3, 4, 4, 4, 4, 4, 4, 4, 4};
此处制作了一个大小为256的快速查找表,元素代表8个不同方向在64个方向组合下打分情况:为了便于理解,梳理一下代码格式:
static const unsigned char LUT3 = 3;
// 1,2-->0,3-->LUT3
CV_DECL_ALIGNED(16)
static const unsigned char SIMILARITY_LUT[256] =
{
//梯度方向0在方向组合下的打分情况;下同
0, 4, LUT3, 4, 0, 4, LUT3, 4,
0, 4, LUT3, 4, 0, 4, LUT3, 4,
0, 0, 0, 0, 0, 0, 0, 0,
LUT3, LUT3, LUT3, LUT3,LUT3, LUT3, LUT3, LUT3,
//1
0, LUT3, 4, 4, LUT3, LUT3, 4, 4,
0, LUT3, 4, 4, LUT3, LUT3, 4, 4,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
//2
0, 0, LUT3, LUT3, 4, 4, 4, 4,
LUT3, LUT3, LUT3, LUT3, 4, 4, 4, 4,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
//3
0, 0, 0, 0, LUT3, LUT3, LUT3, LUT3,
4, 4, 4, 4, 4, 4, 4, 4,
0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3,
0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3,
//4
0, 0, 0, 0, 0, 0, 0, 0,
LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3, LUT3,
0, 4, LUT3, 4, 0, 4, LUT3, 4,
0, 4, LUT3, 4, 0, 4, LUT3, 4,
//5
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, LUT3, 4, 4, LUT3, LUT3, 4, 4,
0, LUT3, 4, 4, LUT3, LUT3, 4, 4,
//6
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, 0, 0, 0, 0, 0, 0,
0, 0, LUT3, LUT3, 4, 4, 4, 4,
LUT3, LUT3, LUT3, LUT3, 4, 4, 4, 4,
//7
0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3,
0, LUT3, 0, LUT3, 0, LUT3, 0, LUT3,
0, 0, 0, 0, LUT3, LUT3, LUT3, LUT3,
4, 4, 4, 4, 4, 4, 4, 4
};
同时,代码中为了解决在待匹配图像在出现遮挡误匹配的情况,代码对原始打分为1和2的情况进行降值为0操作。
快速查找表的分值为什么是这些,见下一小节。
1.2、制作预响应表
8个梯度方向制作8个预响应表,在理论上方向组合会有2^8=256,这样在制作快速查找表的大小应为2048的大小。源码为了减小查找表的大小和提高查找效率,将8为二进制高4位和低4位分开进行打分,通过获取它们打分的最大值确定该像素位置的响应分值。
对8位二进制进行高低4位拆分
CV_Assert((src.rows * src.cols) % 16 == 0);
// Allocate response maps
response_maps.resize(8);
for (int i = 0; i < 8; ++i)
response_maps[i].create(src.size(), CV_8U);
Mat lsb4(src.size(), CV_8U);
Mat msb4(src.size(), CV_8U);
for (int r = 0; r < src.rows; ++r)
{
const uchar *src_r = src.ptr(r);
uchar *lsb4_r = lsb4.ptr(r);
uchar *msb4_r = msb4.ptr(r);
for (int c = 0; c < src.cols; ++c)
{
// Least significant 4 bits of spread image pixel
lsb4_r[c] = src_r[c] & 15;
// Most significant 4 bits, right-shifted to be in [0, 16)
msb4_r[c] = (src_r[c] & 240) >> 4;
}
}
还是就梯度方向方向0情况进行简单分析:
//梯度方向0在方向组合下的打分情况;下同
0, 4, LUT3, 4, 0, 4, LUT3, 4,
0, 4, LUT3, 4, 0, 4, LUT3, 4,
0, 0, 0, 0, 0, 0, 0, 0,
LUT3, LUT3, LUT3, LUT3,LUT3, LUT3, LUT3, LUT3,
代码前两列是低4位的打分情况,后两列是高四位的打分情况。
首先明确一点在将360度量化成16个方向时,每个方向间的角度差值为22.5度,因为是论文求取相似性度量是通过计算梯度方向间的最大余弦值,所以量化的16个梯度方向在数学意义上只有8个梯度方向(同一条直线上的方向相对的梯度方向视为一个方向)。
360度量化成8个方向结果如下图所示:
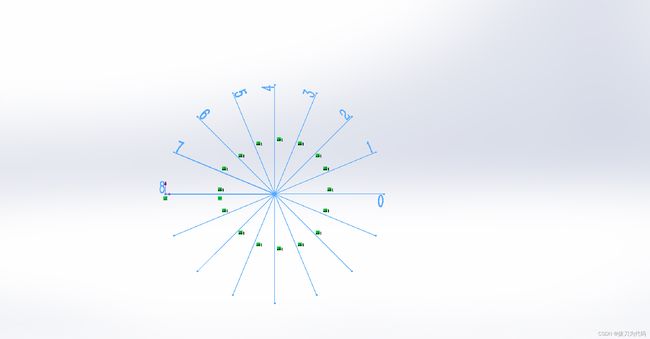
首先梯度方向0在低四位二进制方向组合中,因此,方向角度差值范围为:0度、22.5度、45度、67.5度,对应的最大余弦值分别为:1、0.93、0.7、0.38,依次给这几个余弦值打分为:4、3、2、1。
具体的256个查找表成员的分值可根据下面表格获得。

for (int ori = 0; ori < 8; ++ori)
{
uchar *map_data = response_maps[ori].ptr<uchar>();
const uchar *lut_low = SIMILARITY_LUT + 32 * ori;
if(mipp::N<uint8_t>() == 1 || no_max || no_shuff)
{ // no SIMD
for (int i = 0; i < src.rows * src.cols; ++i)
map_data[i] = std::max(lut_low[lsb4_data[i]], lut_low[msb4_data[i] + 16]);
}
else if(mipp::N<uint8_t>() == 16)
{ // 128 SIMD, no add base
const uchar *lut_low = SIMILARITY_LUT + 32 * ori;
mipp::Reg<uint8_t> lut_low_v((uint8_t*)lut_low);
mipp::Reg<uint8_t> lut_high_v((uint8_t*)lut_low + 16);
for (int i = 0; i < src.rows * src.cols; i += mipp::N<uint8_t>())
{
mipp::Reg<uint8_t> low_mask((uint8_t*)lsb4_data + i);
mipp::Reg<uint8_t> high_mask((uint8_t*)msb4_data + i);
mipp::Reg<uint8_t> low_res = mipp::shuff(lut_low_v, low_mask);
mipp::Reg<uint8_t> high_res = mipp::shuff(lut_high_v, high_mask);
mipp::Reg<uint8_t> result = mipp::max(low_res, high_res);
result.store((uint8_t*)map_data + i);
}
}
else if(mipp::N<uint8_t>() == 16 || mipp::N<uint8_t>() == 32|| mipp::N<uint8_t>() == 64)
{ //128 256 512 SIMD
CV_Assert((src.rows * src.cols) % mipp::N<uint8_t>() == 0);
uint8_t lut_temp[mipp::N<uint8_t>()] = {0};
for(int slice=0; slice<mipp::N<uint8_t>()/16; slice++)
{
std::copy_n(lut_low, 16, lut_temp+slice*16);
}
mipp::Reg<uint8_t> lut_low_v(lut_temp);
uint8_t base_add_array[mipp::N<uint8_t>()] = {0};
for(uint8_t slice=0; slice<mipp::N<uint8_t>(); slice+=16)
{
std::copy_n(lut_low+16, 16, lut_temp+slice);
std::fill_n(base_add_array+slice, 16, slice);
}
mipp::Reg<uint8_t> base_add(base_add_array);
mipp::Reg<uint8_t> lut_high_v(lut_temp);
for (int i = 0; i < src.rows * src.cols; i += mipp::N<uint8_t>())
{
mipp::Reg<uint8_t> mask_low_v((uint8_t*)lsb4_data+i);
mipp::Reg<uint8_t> mask_high_v((uint8_t*)msb4_data+i);
mask_low_v += base_add;
mask_high_v += base_add;
mipp::Reg<uint8_t> shuff_low_result = mipp::shuff(lut_low_v, mask_low_v);
mipp::Reg<uint8_t> shuff_high_result = mipp::shuff(lut_high_v, mask_high_v);
mipp::Reg<uint8_t> result = mipp::max(shuff_low_result, shuff_high_result);
result.store((uint8_t*)map_data + i);
}
}
else
{
for (int i = 0; i < src.rows * src.cols; ++i)
map_data[i] = std::max(lut_low[lsb4_data[i]], lut_low[msb4_data[i] + 16]);
}
}
此段代码是利用查找表对输入图像的每像素进行制作响应表。
代码中if函数的多重嵌套目的是在各种编译环境下尽量使用指令集提高程序制作响应表的速度。
二、响应表内存线性化
1、论文分析

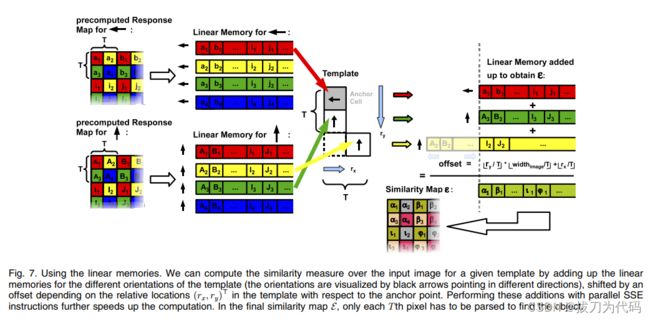
文献里面提到为了提高模板同输入图片的处理速度对响应表进行线性化。作者提出了根据计算机数据处理的特点将响应表按照数据处理逻辑重修编排结构,即按照等间距的将响应表中数据线性排列。
2、代码分析
static void linearize(const Mat &response_map, Mat &linearized, int T)
{
CV_Assert(response_map.rows % T == 0);
CV_Assert(response_map.cols % T == 0);
// linearized has T^2 rows, where each row is a linear memory
int mem_width = response_map.cols / T;
int mem_height = response_map.rows / T;
linearized.create(T * T, mem_width * mem_height, CV_8U);
// Outer two for loops iterate over top-left T^2 starting pixels
int index = 0;
for (int r_start = 0; r_start < T; ++r_start)
{
for (int c_start = 0; c_start < T; ++c_start)
{
uchar *memory = linearized.ptr(index);
++index;
// Inner two loops copy every T-th pixel into the linear memory
for (int r = r_start; r < response_map.rows; r += T)
{
const uchar *response_data = response_map.ptr(r);
for (int c = c_start; c < response_map.cols; c += T)
*memory++ = response_data[c];
}
}
}
}
响应表重新排列时,需要制作一个新的表可以容纳原表所有元素,代码中根据提取间隔T的大小,将原来widthheight的表格设计成(TT)(width/T)(height/T)的表格。