无卷积结构(那就纯ransformer)的参考图像分割:ReSTR: Convolution-free Referring Image Segmentation Using Transformers
无卷积结构{那就纯Transformer}的参考图像分割:ReSTR: Convolution-free Referring Image Segmentation Using Transformers
- 一、Abstract
- 二、引言
- 三、相关工作
-
- 3.1 语义分割
- 3.2 参考图像分割
- 3.3 视觉 Transformer
- 四、方法
-
- 4.1 视觉语言特征提取
-
- 4.1.1 视觉编码器
- 4.1.2 语言编码器
- 4.2 多模态融合编码器
- 4.3 粗糙-细化 分割解码器
- 五、实验
-
- 5.1 实验设置
-
- 5.1.1 数据集
- 5.1.2 实施细节
- 5.2 与 SOTA 比较
- 5.3 不同融合编码器的变体分析
- 5.4 更进一步的分析
-
- 5.4.1 多模态融合编码器层数的分析
- 5.4.2 分割解码器的效果分析
- 5.4.3 权值共享的分析
- 5.4.4 定性分析
- 5.4.5 计算成本分析
- 六、结论
- 附录
-
- A 语言表达式长度的影响
- B 超参数敏感性
- C 更多的定量分析
写在前面
好久没写博客了,要么在撸代码,要么在构思 SCI ( ̄□ ̄||),
快速过一篇论文: ReSTR: Convolution-free Referring Image Segmentation Using Transformers,新颖的话也谈不上多新颖,目前的 Transformer 都快烂大街了,其中的一些结构可以借鉴下,说不定是涨点神器
- 论文地址:ReSTR: Convolution-free Referring Image Segmentation Using Transformers
- 收录于: CVPR 2022
- 代码链接:GitHub,截止本博文完成时间 22年7月1日,暂未放出。
一、Abstract
给出参考图像分割 Referring image segmentation (RIS) 的定义,指出采用卷积网络的不足:很难捕获实体之间的长距离依赖,两种模态间的交互不充分。为了解决上面的问题,本文提出第一个无卷积模型,ReSTR,实验表明效果很好。
二、引言

点出语义分割的缺陷,引出本文的主题参考图像分割,指出其优点与挑战及模型应该具备的能力。
第二段概述一下现有方法框架,CNN + RNN 送入多模态联合层或者注意力机制。
第三段总结下这些方法的缺陷:同摘要里面,无法解决长距离模态交互;无法有效建模复杂的交互关系。
第四段总结本文提出的方法,即图一所示。将图像 Patches 和 词 embedding 作为输入,送入 Transformer 中,此外,还有一个 Class 词作为另外一个输入送入 Transformer,输出为多模态特征和 Class 对应的 2 分类标签(有没有表达式中的目标),之后将多模态特征送入一系列上采样层和线性层得到 masks。
最后总结下本文贡献:
- 第一个无卷积的模型,能捕捉长距离模态交互,可以有效建模模态间复杂的交互关系;
- 利用类别 embedding 设计自适应的分类器;
- 性能牛批。
三、相关工作
3.1 语义分割
FCN → FCN的变体
3.2 参考图像分割
CNN + RNN → ConvLSTM → Attention,最后补下刀,表明本文提出的模型不同于这些方法。
3.3 视觉 Transformer
点出 Transformer 的引入,然后有 CNN + Transformer 的工作,指出一些其他的应用,如图像分类,目标检测,语义分割等。受到这些方法的启发,本文采用了一个自适应分类器作为可学习的类别序列。
四、方法

简述一下模型的结构,也就是上图的 a、b、c 三个部分。
4.1 视觉语言特征提取
首先介绍下 Tranformer 的结构,老套路了,MSA + LN + MLP
z ‾ i + 1 = MSA ( LN ( z i ) ) + z i z i + 1 = MLP ( LN ( z ‾ i + 1 ) ) + z ‾ i + 1 MSA ( z ) = [ S A 1 ( z ) , S A 1 ( z ) , ⋯ , S A k ( z ) ] W M S A SA ( z ) = A v A = softmax ( q k ⊤ / D h ) \begin{array}{c} \overline{\mathbf{z}}_{i+1}=\operatorname{MSA}\left(\operatorname{LN}\left(\mathbf{z}_{i}\right)\right)+\mathbf{z}_{i} \\ \\ \mathbf{z}_{i+1}=\operatorname{MLP}\left(\operatorname{LN}\left(\overline{\mathbf{z}}_{i+1}\right)\right)+\overline{\mathbf{z}}_{i+1}\\ \\ \operatorname{MSA}(\mathbf{z})=\left[\mathrm{SA}_{1}(\mathbf{z}), \mathrm{SA}_{1}(\mathbf{z}), \cdots, \mathrm{SA}_{k}(\mathbf{z})\right] \mathbf{W}_{\mathrm{MSA}} \\ \\ \operatorname{SA}(\mathbf{z})=A \mathbf{v} \\ \\ A=\operatorname{softmax}\left(\mathbf{q k}^{\top} / \sqrt{D_{h}}\right) \end{array} zi+1=MSA(LN(zi))+zizi+1=MLP(LN(zi+1))+zi+1MSA(z)=[SA1(z),SA1(z),⋯,SAk(z)]WMSASA(z)=AvA=softmax(qk⊤/Dh)
都是 Transformer 里面常见的东西,只不过这里给换了马甲,运算意义相同。
4.1.1 视觉编码器
先分割成 Patch, 然后送入全连接层,最后加入 1维位置特征,送入 Tranformers。
z v = Transformers ( z 0 v ; θ v ) \mathbf{z}_{v}=\operatorname{Transformers}\left(\mathbf{z}_{0}^{v} ; \boldsymbol{\theta}_{v}\right) zv=Transformers(z0v;θv)
4.1.2 语言编码器
先转为词 embedding 向量,然后添加 1 维位置编码,同视觉编码器一样送入语言编码器得到输出。
4.2 多模态融合编码器
由两个Transformer 编码器组成,第一个编码器输入为 视觉 + 语言 编码器输出的拼接特征: [ z v ′ , z l ′ ] = Transformers ( [ z v , z l ] ; θ v l ) \left[\mathbf{z}_{v}^{\prime}, \mathbf{z}_{l}^{\prime}\right]=\operatorname{Transformers}\left(\left[\mathbf{z}_{v}, \mathbf{z}_{l}\right] ; \boldsymbol{\theta}_{v l}\right) [zv′,zl′]=Transformers([zv,zl];θvl),其中 z v ′ \mathbf{z}_{v}^{\prime} zv′ 是输出的多模态特征, z l ′ \mathbf{z}_{l}^{\prime} zl′ 是视觉参与的语言特征。之后将 z l ′ \mathbf{z}_{l}^{\prime} zl′ 送入到第二个编码器:语言-种子编码器, e s ′ = Transformers ( [ z l ′ , e s ] ; θ l s ) \mathbf{e}_{s}^{\prime}=\operatorname{Transformers}\left(\left[\mathbf{z}_{l}^{\prime}, \mathbf{e}_{s}\right] ; \boldsymbol{\theta}_{l s}\right) es′=Transformers([zl′,es];θls),输出 e s ′ ∈ R 1 × D \mathbf{e}_{s}^{\prime}\in\mathbb{R}^{1\times{D}} es′∈R1×D 为自适应的两分类器。
4.3 粗糙-细化 分割解码器
这一块是本文的精髓所在,需要仔细看看(涨点技巧)。
在多模态特征 z v ′ \mathbf{z}_{v}^{\prime} zv′ 和 自适应分类器 e s ′ ⊤ \mathbf{e}_{s}^{\prime \top} es′⊤ 之间采用点乘的方式得到 Patch 层级上的预测特征 y ^ p \hat{\mathbf{y}}_{p} y^p。
y ^ p = σ ( z v ′ e s ′ ⊤ D ) \hat{\mathbf{y}}_{p}=\sigma\left(\frac{\mathbf{z}_{v}^{\prime} \mathbf{e}_{s}^{\prime \top}}{\sqrt{D}}\right) y^p=σ(Dzv′es′⊤)其中, σ \sigma σ 为 sigmoid 函数, D \sqrt{D} D 是归一化因子。
然后另外一个分支产生掩码特征:
Z masked = z v ′ ⊗ y ^ p \mathbf{Z}_{\text {masked }}=\mathbf{z}_{v}^{\prime} \otimes \hat{\mathbf{y}}_{p} Zmasked =zv′⊗y^p
其中 ⊗ \otimes ⊗ 表示对位乘积。
之后对 Z v \mathbf{Z}_{\text {v}} Zv、 Z masked \mathbf{Z}_{\text {masked }} Zmasked 拼接送入分割解码器,其中分割解码器采用 K K K 个序列块组成。每个块包含采样因子为 2 的上采样层和线性全连接层(将输入通道变为原来的二分之一),其中 K = log P K = \log P K=logP, P P P 为 Patch 的尺寸。最后的特征送入 Logit 层输出 mask: Y ^ m ∈ R H × W × 1 \hat{Y}_{m}\in{\mathbb{R}}^{H\times{W}\times{1}} Y^m∈RH×W×1。
输出有了,那么标签 y p i ∈ R N v × 1 {y}^{i}_{p}\in{\mathbb{R}}^{N_{v}\times{1}} ypi∈RNv×1 的构造:
y p i = { 1 , if h ( p i j ) > τ 0 , otherwise \mathbf{y}_{p}^{i}=\left\{\begin{array}{ll} 1, & \text { if } h\left(p_{i j}\right)>\tau \\ 0, & \text { otherwise } \end{array}\right. ypi={1,0, if h(pij)>τ otherwise 其中, h h h 表示在空间维度上的平均池化, τ \tau τ 为阈值超参数。
训练损失: BCE 损失
L ( y ^ p , y p , Y ^ m , Y m ) = λ L b ( y ^ p , y p ) + L b ( Y ^ m , Y m ) \mathcal{L}\left(\hat{\mathbf{y}}_{p}, \mathbf{y}_{p}, \hat{Y}_{m}, Y_{m}\right)=\lambda \mathcal{L}_{b}\left(\hat{\mathbf{y}}_{p}, \mathbf{y}_{p}\right)+\mathcal{L}_{b}\left(\hat{Y}_{m}, Y_{m}\right) L(y^p,yp,Y^m,Ym)=λLb(y^p,yp)+Lb(Y^m,Ym)其中 λ \lambda λ 为平衡系数。
五、实验
5.1 实验设置
5.1.1 数据集
ReferIt、UNC、UNC+、Gredf
5.1.2 实施细节
ViT-B-16 在 ImageNet-21K 数据集上训练好的模型作为视觉编码器,12层,16个 patch, 768 维度,12 个头、3072维度 MLP,数据量太夸张。
Glove 300d 作为词嵌入向量进行编码,句子长度为 20,其他参数同视觉编码器。
分割解码器的数量为 4,patch 为16,AdamW 优化器,权重衰减 5 e − 4 5e-4 5e−4,初始学习率 1 e − 5 1e-5 1e−5,batch 8, 40 0000 此迭代,4 0000 热身训练,输入图像尺寸 480x480, τ \tau τ 和 λ \lambda λ 分别为 0.8、0.1。
评估指标 IOU 0.5、0.6、0.7,0.8,0.9。
5.2 与 SOTA 比较


5.3 不同融合编码器的变体分析

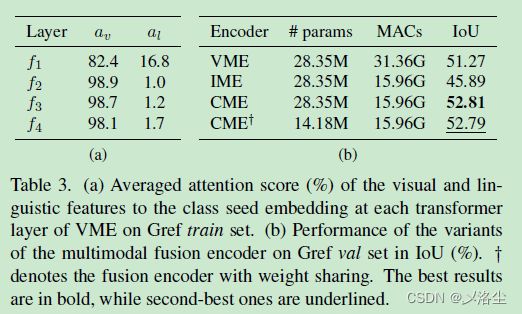
5.4 更进一步的分析
5.4.1 多模态融合编码器层数的分析

5.4.2 分割解码器的效果分析
同上图。
5.4.3 权值共享的分析
同上图。
5.4.4 定性分析
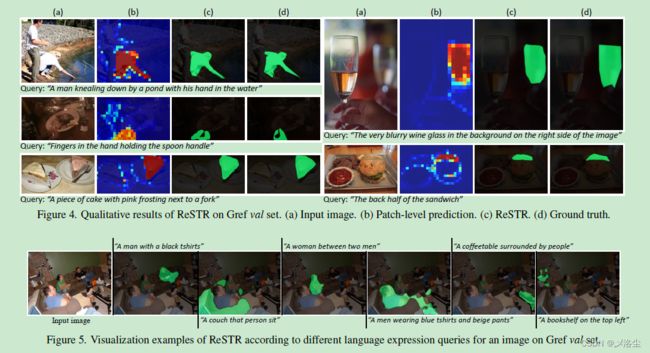
5.4.5 计算成本分析

(PS:这计算量也是恐怖的一批)
六、结论
继续吹一下第一个无卷积的模型,实验效果很好,缺陷是随着 Patch 块的增加,计算成本呈平方增加,留待后续工作。
附录
A 语言表达式长度的影响

B 超参数敏感性

C 更多的定量分析


写在后面:
这篇工作难度不大,其中最主要的是那个自适应分类器的设计比较巧妙,估计是个涨点的技巧~~