信息流短视频时长多目标优化
转载连接:https://yq.aliyun.com/articles/627734/ ,仅做学习参考, 如侵犯权益,请原作者联系删除,其他人转载请备注原作者连接。
背景
信息流短视频排序目前使用的是基于CTR预估Wide&Deep排序模型。在此基础上继续一系列优化,通过引入相关性信号、体感信号、多场景的样本融合、高层排序模型取得了不错收益。
信息流短视频模型优化可分为两部分优化:
- 感知相关性优化——点击模型以优化(CTR/CLICK为目标)
- 真实相关性优化——时长多目标优化(停留时长RDTM/播放完成率PCR)
上述收益均基于点击模型的优化,模型能够很好地捕抓USER-ITEM之间感知相关性,感知权重占比较高,弱化真实相关性,这样可能导致用户兴趣收窄,长尾问题加剧;此外,停留时长,无论是信息流、竞品均作为重要优化目标,Youtube基于时长策略权重占比50%以上。在此前提下,我们排序模型迫切需要引入时长多目标优化,提升推荐的真实相关性,寻求在时长上取得突破。
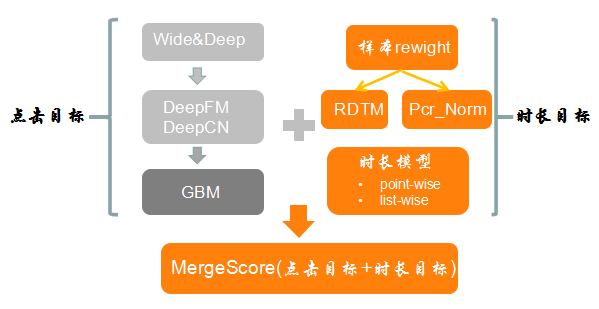
时长多目标的引入,排序模型不仅单纯地优化点击目标,同时也要兼顾时长目标,使得排序模型的感知相关性与真实相关性均得到较好的体现;目前业界点击+时长优化有多种方式包括:多目标优化(点击+时长)、联合建模(参考阿里联合预估算法JUMP)等。
这里我们通过样本rewight方式,相当于点击label不变情况下,时长作为较强的bias去影响时长目标,保证感知相关性前提,去优化真实相关性。目前我们正在调研更加自适应的时长建模方式括(point-wise、list-wise),后续为进一步介绍。上述是时长多目标优化简要介绍,而样本reweight优化取得不错的收益,下面简单介绍下。
RDTM REWEIGHTING
模型时长多目标样本加权方式,是我们参照weighted logistic regression方法,结合RecSys2016上Youtube提出的时长建模,在模型训练是通过停留时长去对正样本加权,负样本不加权,从而去影响正负样本的权重分布,使得停留时长越长的样本,在时长目标下得到充分训练。
加权逻辑回归方法在稀疏点击场景下可以很好使得时长逼近与期望值。假设 就是weighted logistic regression学到的期望,其中N是样本数量,K是正样本,Ti是停留时长,真实期望就近似逼近E(T)*(1-P),P是点击概率,E(T)是停留时长期望值,在P<<1情况下,真实期望值就逼近E(T),所以,通过加权逻辑回归方式做样本加权,切合我们点击稀疏的场景,通过样本加权方式使得模型学到item停留时长偏序关系。
就是weighted logistic regression学到的期望,其中N是样本数量,K是正样本,Ti是停留时长,真实期望就近似逼近E(T)*(1-P),P是点击概率,E(T)是停留时长期望值,在P<<1情况下,真实期望值就逼近E(T),所以,通过加权逻辑回归方式做样本加权,切合我们点击稀疏的场景,通过样本加权方式使得模型学到item停留时长偏序关系。
样本加权优化方式我们参照Youtube的时长建模,但具体做法上存在以下差异:
- Youtube以时长为label做优化,而我们还是基于点击label,这样是为了保证模型感知相关性(CTR/CLICK);
- Youtube是回归问题,通过指数函数拟合时长预测值,而我们则是分类问题,优化损失函数logloss;
- 停留时长加权方式上我们考虑停留时长与视频本身时长关系,采用多分段函数平滑停留时长和视频本身时长关系,而youtube则是观看时长加权;
上述差异主要从两个方面考虑:
- 保证CTR稳定的前提下(模型label依然是点击),通过样本reweight去优化时长目标。
- 分段函数平滑保证长短视频的下发量严重倾斜,尽可能去减少因为视频长短因素,而模型打分差距较大问题。
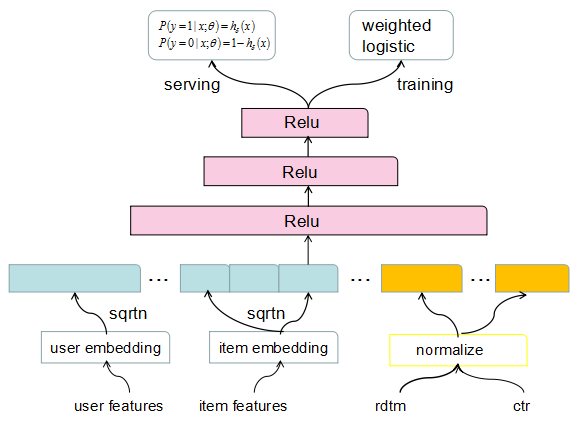
我们的模型网络结构与youtube差异不大,底层特征做embedding共享,离散归一化。训练是通过引入weighted logistic去优化时长目标,在线预测依然是0/1概率,而在0/1概率跟之前不同是的经过时长bias修正,使得模型排序考虑真实相关性。
离线评估指标
- AUC:AUC作为排序模型常用离线评估特别适用是0/1分类问题,目前我们模型label还是点击0/1问题,所以,AUC是一个基础离线指标。但是AUC很难准确地评估模型对于时长优化好坏,因此AUC只是作为模型准入的条件,保证AUC持平/正向情况下,我们需要时长指标衡量模型好坏。
- AVG_RDTM: (预测平均停留时长)——每一batch中选取模型打分topk正样本item,取这批停留时长均值作为AVG_RDTM, 通过AVG_RDTM的大小来离线评估模型在时长推荐的好坏。 通过AUC保证推荐感知相关性(CTR), 而AVG_RDTM则是在这批正样本Item内最大化停留时长的评估,在线时长指标趋势与AVG_RDTM趋势一致,涨幅上有diff。
PCR_NORM REWEIGHTING
一期在停留时长样本加权上取得不错的收益,二期是集中播放完成率上的优化。
二期优化来源于我们策略review结果,我们发现一大部分高播放完成率的视频,CTR较低,打分靠后,这批item中视频本身时长1min内占比较大。一期我们用时长分段函数来做样本加权,一定程度上平滑了视频本身时长对打分影响,而播放完成率体现用户对单item的注意力,更能反映推荐的真实相关性。短视频时长,播放完成率取得突破对于信息流规模化和口碑打造具有强推进剂作用。
针对以上较短,较长的优质视频打分靠后,下发量不足的问题,我们引入分位数播放完成率来做平滑加权。主要是以下两种方式:
- 时长目标优化从停留时长加权演变至播放完成率加权,更好的平滑长短视频之间的打分差异,使得模型打分更加注重于真实相关性。
- 视频时长分段,停留时长完成率分位数归一化+威尔逊置信区间平滑,使得各视频时长段播放完成率相对可比,避免出现打分因视频长度严重倾斜情况。
此外,较短或较长的视频在播放完成率上有天然的差距,我们按视频本身长度离散,停留时长做分位数处理,归一化长短视频播放完成率上的差异,使得各长度段的视频播放完成率可比。
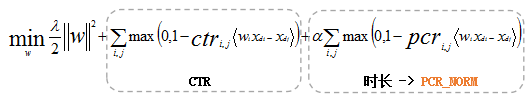
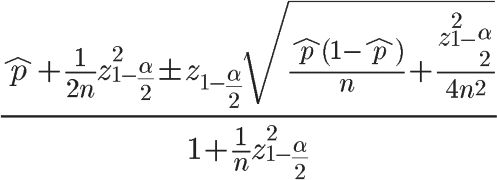
时长多目标优化从停留时长升级至PCR_Norm, 全局Item停留时长处在相对可比的状态,尽可能减少视频本身时长对打分影响,使得模型打分更加专注于User-Item真实相关性和视频质量,提升长尾优质的视频Item消费。
二期Pcr_norm优化基于一期时长加权基础上,离线评估与一期优化类似:AUC与AVG_RDTM,归一化的播放完成率更能反映用户对item的专注度,通过优化单次阅读时长,阅读完成率来提升整体的停留时长消费,拉升大盘指标。
优化收益
一期+二期离线AUC累积提升6%以上,在线人均时长累积提升10%以上。
结语
信息流短视频多目标优化目前处于探索阶段,初步探索出短视频多目标优化渐进路线,从样本reweight -> point-wise时长建模 -> list-wise时长建模 -> 多模态联合学习方向。此外,沉淀了一些策略review和数据分析方法论,为后续时长优化提供数据基础。
虽然现阶段时长多目标优化取得不错收益,但是优化规则性较多,后续我们将逐步转向自适应的时长建模,从point-wise到全局list-wise时长优化,由感知相关性优化转向真实相关性优化,力争在消费时长取得较大突破。而自适应的时长建模及点击目标与时长目标的权衡收益最大化,将是我们面临又一挑战。