3.Deep Neural Networks for YouTube Recommendations论文精细解读
一、总述
今天分享的是Deep Neural Networks for Y ouTube Recommendations这篇论文的一些核心,这篇论文被称为推荐系统工程实践领域的一篇神文,每一个细节都值得我们细致分析和思考。
二、摘要
YouTube是如今工业界最大、最复杂的推荐系统之一,作者提出了一种高效的基于深度学习的推荐系统。该系统和工业界经典的推荐流程一样,分为候选集生成( candidate generation也称为召回),排序(ranking)两个阶段。通过深度候选模型(candidate generation model)和深度排序模型(deep ranking model)搭建推荐系统,为YouTube用户推荐视频。
三、引言
在推荐系统领域,特别是YouTube的所在视频推荐领域,主要面临三个挑战:
- Scale(规模大):视频和用户数量巨大,很多现有的推荐算法能够在小的数据集上表现得很好,但在Youtube效果不佳。需要构建高度专业化的分布式学习算法和高效的服务系统来处理youtube庞大的用户和视频数量。
- Freshness(更新快):这体现在两方面,一方面视频更新频繁,需要在新发布视频和已有存量视频间进行balance;另一方面用户行为更新频繁,模型需要很好的追踪用户的实时行为。
- Noise(噪声):相较于庞大的视频库,用户的行为是十分稀疏的,同时,我们很少获得用户满意度的基本事实,基本上能获得的都是用户的隐式反馈信号。噪音另一个方面就是视频本身很多数据都是非结构化的。这两点对算法的鲁棒性提出了很高的挑战。
四、系统概述
在工业界工作的同学对下图的系统划分并不陌生。整个推荐系统分为candidate generation(淘宝称为Matching)和Ranking两个阶段。Matching阶段通过i2i/u2i/u2u/user profile等方式“粗糙”的召回候选商品,candidate generation阶段后的视频的数量是百级别了;Ranking阶段对Matching后的视频采用更精细的特征计算user-item之间的排序分,作为最终输出推荐结果的依据。

Candidate Generation Model:输入包括millions video corpus、user history and context ,旨在快速高效地筛选部分视频集合。
Ranking Model:输入包括hundreds video corpus、user history and context、other candidate sources、video features,旨在得到高精度的TOP N。
综上:
- 候选:用户的历史行为作为输入,从大量数据集中检索出部分(上百)子集,此部分可以通过协同过滤、粗糙的特征(如观看过的视频,搜索记录,用户画像等)进行检索
- 排序:利用上述候选模块筛选出来的候选集,结合更丰富的特征,对每个候选进行打分排序,依据得分从高到底进行推荐
评价指标:线下评价(precision,recall,ranking loss); 线上评价(A/B test,点击率、观看时间)
五、Candidate Generation Model(候选集生成模型)
5.1 问题建模
我们把推荐问题建模成一个“超大规模多分类”问题。即在时刻t tt,用户U UU(上下文信息C CC)会观看视频i ii的概率(每个具体的视频视为一个类别,i ii即为一个类别),用数学公式表达如下:

而这种超大规模分类问题上,至少要有几百万个类别,实际训练采用的是Negative Sampe,类似于word2vec的Skip-Gram方法。详细了解可以参考https://zhuanlan.zhihu.com/p/24339183?refer=deeplearning-surfing 中的item-embedding用的方法。
5.2 模型架构

整个模型架构是包含三个隐层的DNN结构。输入是用户浏览历史、搜索历史、人口统计学信息和其余上下文信息concat成的输入向量;输出分线上和离线训练两个部分。
我们自底而上看这个网络,最底层的输入是用户观看过的video的embedding向量,以及搜索词的embedding向量。至于这个embedding向量是怎么生成的,作者的原话是这样的 :Inspired by continuous bag of words language models, we learn high dimensional embeddings for each video in a xed vocabulary and feed these embeddings into a feedforward neural network。
简单来说就是分别利用word2vec对embedded video watches和embedded search tokens做了一个embedding,然后网络训练的时候直接查表就完事儿,具体在网络训练的时候可以fine-tuning(fine tuning的过程其实就是用训练好的参数(可以从已训练好的模型中获得)初始化自己的网络,然后用自己的数据接着训练,参数的调整方法与from scratch训练过程一样(梯度下降)。)也可以frozen,具体看哪个效果好了。那么这个word2vec是怎么训练的,其实就是把一个user观看过的video当作一句话,然后给word2vec训练就行,这里具体的应该叫他item2vec,与word2vec训练时预测上下文单词不同,item2vec中的训练集(即一个item序列)并没有时间窗口关系,所以这两个算法区别就是目标函数的区别,item2vec是每一个单词都对句子中其他item进行预测。除了作者提到的这种方法,还可以采用端到端的方式,即直接在模型中加入embedding一起训练,两种方法有各自不同的使用场景。
特征向量里面还包括了用户的地理位置的embedding,年龄,性别等。然后把所有这些特征concatenate起来,喂给上层的ReLU神经网络。
三层神经网络过后,我们看到了softmax函数。这里Youtube的同学们把这个问题看作为用户推荐next watch的问题,所以输出应该是一个在所有candidate video上的概率分布,自然是一个多分类问题。
好了,这一套深度学习的“基本操作”下来,就构成了Youtube的candidate generation网络,看似平淡无奇,其实还是隐藏着一些问题的,比如下面两个问题(答案来自某大神的观点)
(1)架构图的左上角,为什么在online serving的时候不直接用这套网络进行预测而要使用nearest neighbor search 的方法?
(2)多分类问题中,Youtube的candidate video有百万之巨,意味着有几百万个分类,这必然会影响训练效果和速度,如何改进?
answer1:这个问题的答案是一个经典的工程和学术做trade-off(权衡)的结果,在model serving过程中对几百万个候选集完整跑完模型最后一层softmax开销太大,因此在通过candidate generation model得到user 和 video的embedding之后,通过最近邻搜索的方法的效率高很多。我们甚至不用把任何model inference的过程搬上服务器,只需要把user embedding和video embedding存到redis或者内存中就好了。现在咱们来具体说一下video embedding是如何让生成的,假若模型最后relu输出的维度是Nx1的向量(这也就是所谓的user embedding),接下来的softmax层是一个MxN的矩阵,M是候选视频集合的数量,那么这里每个行向量就是对应的vedio embedding。这个embedding是在离线模型中训练好的,线上只用softmax之前的那些网络,每次推荐都会生成一个Nx1的user embedding,然后对离线训练好的MxN的video矩阵进行一个近邻搜索,看哪个视频向量和他的相似度最高,这里可以提升的原因是因为,可以利用LSH(局部敏感哈希,感兴趣的同学可以读读这篇论文 An Investigation of Practical Approximate Nearest Neighbor Algorithms的算法为用户提供最相关的N个视频)之类的方法提升匹配效率。
answer2:采用negtive sampling(负采样),并用importance weighting对采样进行校正,提高模型学习的效率。我认为这里的思路和word2vec中的差不多,采用这种负采样,降低了每次参数更新的复杂度。我们知道如果不负采样的话每次更新都会对所有的vedio向量进行更新,因为softmax层存在的缘故,采用负采样之后,直接利用极大似然法,最大化正样本出现的概率最小化负样本出现的概率,而不必进行softmax计算。
例如:在当前场景下的负采样:假设有一个样本,label=video_18,如果分类总共有100个,训练到这条样本的时候,由于最后是softmax,模型更新参数使video_18的softmax输出偏向1,剩余99个item的softmax输出偏向0。负采样指的是当总分类达到十万,正常softmax需要使得剩余99999个item的softmax输出偏向0,这样更新量很大,所以采用sample softmax,在更新这次样本时指定全集只有5001,屏蔽了剩余的94999个item,即负采样数目=5000,这样这次更新只会使得当前item输出偏向1,剩余5000个item的softmax输出偏向0。
5.3 主要特征
类似于word2vec的做法,每个视频都会被embedding到固定维度的向量中。用户的观看视频历史则是通过变长的视频序列表达,最终通过加权平均(可根据重要性和时间进行加权)得到固定维度的watch vector作为DNN的输入。
除历史观看视频外的其他signal:
其实熟悉Skip-Gram方法的同学很容易看出来,5.1把推荐问题定义为“超大规模多分类”问题的数学公式和word2vec的Skip-Gram方法的公式基本相同,所不同的是user_vec是通过DNN学习到的,而引入DNN的好处则是任意的连续特征和离散特征可以很容易添加到模型当中。同样的,推荐系统常用的矩阵分解方法虽然也能得到user_vec和item_vec,但同样是不能嵌入更多feature。
主要特征:

Example Age” (视频上传时间)特征:
视频网络的时效性是很重要的,每秒YouTube上都有大量新视频被上传,而对用户来讲,哪怕牺牲相关性代价,用户还是更倾向于更新的视频。当然我们不会单纯的因为一个视频新就直接推荐给用户。
因为机器学习系统在训练阶段都是利用过去的行为预估未来,因此通常对过去的行为有个隐式的bias。视频网站视频的分布是高度非静态(non-stationary)的,但我们的推荐系统产生的视频集合在视频的分布,基本上反映的是训练所取时间段的平均的观看喜好的视频。为了拟合用户对fresh content的bias,模型引入了“Example Age”这个特征,sample log距离当前的时间作为example age(文章并没有定义)。例如24小时前,用户观看该视频,会产生日志,这个example age就是24。而在线上服务阶段,该特征被赋予0值甚至是一个比较小的负数。这样的做法类似于在广告排序中消除position bias。
文章也验证了,example age这个feature能够很好的把视频的freshness的程度对popularity的影响引入模型中。从下面的图中我们也可以看到,在引入“Example Age”这个feature后,模型的预测效力更接近经验分布;而不引入Example Age的蓝线,模型在所有时间节点上的预测趋近于平均,这显然是不符合客观实际的。

5.4 样本和上下文选择(label and context selection)
在有监督学习问题中,最重要的选择是label了,因为label决定了你做什么,决定了你的上限,而feature和model都是在逼近label。在这里,正样本是用户所有完整观看过的视频,其余可以视作负样本。其余的几个设计如下:
- 使用更广的数据源:训练样本是从Youtube所有的用户观看记录里产生的,而并非只是通过推荐系统产生的。不仅仅使用推荐场景的数据进行训练,其他场景比如搜索等的数据也要用到,这样也能为推荐场景提供一些explore。
- 为每个用户生成固定数量训练样本:我们在实际中发现的一个practical lessons,如果为每个用户固定样本数量上限,平等的对待每个用户,避免loss被少数active用户domanate,能明显提升线上效果。
- 无序化处理:Youtube并没有选择时序模型,而是完全摒弃了序列关系,采用求平均的方式对历史记录进行了处理(对过去观看视频/历史搜索query的embedding向量进行加权平均)。这是因为考虑时序关系,用户的推荐结果将过多受最近观看或搜索的一个视频的影响。文章中给出一个例子,如果用户刚搜索过“taylorswift”,你就把用户主页的推荐结果大部分变成taylorswift有关的视频,这其实是非常差的体验。为了综合考虑之前多次搜索和观看的信息,YouTube丢掉了时序信息,讲用户近期的历史纪录等同看待。但是上述仅是YouTube工程师的经验之谈。这点其实违反直觉,可能原因是模型对负反馈没有很好的建模。
- 上下文选择:用户观看视频时,遵循的是一种非对称的共同浏览模式(asymmetric co-watch),在初始的观看序列中,范围会比较广泛,在后期的观看中,范围会逐渐集中。而大部分协同过滤算法,在推荐时往往利用的是用户的全量观看历史。所以,作者的改进在于从用户的观看历史序列中,只截取held-out watch之前的观看序列。
下图所示图(a)是hled-out方式,利用上下文信息预估中间的一个视频;图(b)是predicting next watch的方式,则是利用上文信息,预估下一次浏览的视频。我们发现图(b)的方式在线上A/B test中表现更佳(只留最后一次观看行为做测试集主要是为了避免引入future information,产生与事实不符的数据穿越。)。而实际上,传统的协同过滤类的算法,都是隐含的采用图(a)的held-out方式,忽略了不对称的浏览模式。

5.5 不同网络深度和特征的实验
这里采用的是经典的“tower”模式搭建网络,基本同5.2所示的网络架构,所有的视频和search token都embedded到256维的向量中,开始input层直接全连接到256维的softmax层,依次增加网络深度(+512–>+1024–>+2048–> …)。

评估输入特征以及网络层数对于实验效果的影响,评价指标是MAP(Mean Average Precision)。下图反映了不同网络深度(横坐标)下不同特征组合情况下的holdout-MAP(纵坐标)。可以很明显看出,增加了观看历史之外的特征很明显的提升了预测得准确率;从网络深度看,随着网络深度加大,预测准确率在提升,但继续增加第四层网络已经收益不大了。

六、Ranking(精排模型)
Ranking阶段的最重要任务就是精准的预估用户对视频的喜好程度(对候选集做进一步细粒度的排序,可以参考更多维度的特征)。不同于Candidate Generation Model阶段面临的是百万级的候选视频集,Ranking阶段面对的只是百级别的商品集,因此我们可以使用更多更精细的feature来刻画视频(item)以及用户与视频(user-item)的关系。比如用户可能很喜欢某个视频,但如果list页的用的“缩略图”选择不当,用户也许不会点击,等等。
此外,排序阶段还涉及到对多个不同召回源进行有效集成,不同召回源的打分有时候并没有可比性,所以排序阶段也需要解决此类问题。(如果召回阶段采用多路召回,每一路召回因为采取的策略或者模型不同,所以各自的召回模型得分不可比较,比如利用协同过滤召回找到的候选Item得分,与基于兴趣标签这一路召回找到的候选Item得分,完全是不可比较的。)。
在目标的设定方面,单纯CTR指标是有迷惑性的,有些靠关键词吸引用户高点击的视频未必能够被播放。因此设定的目标基本与期望的观看时长相关,具体的目标调整则根据线上的A/B进行调整。
6.1 模型架构
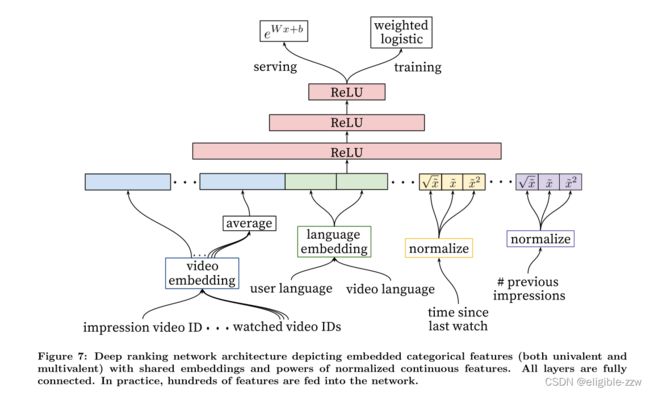
其实粗排模型(Candidate Generation Model)和精排模型(Ranking Model)区别就在于更细致的特征工程,作者的原话是:During ranking, we have access to many more features describing the video and the user’s relationship to the video because only a few hundred videos are being scored rather than the millions scored in candidate generation.
具体一点,从左至右的特征依次是
- impression video ID embedding: 当前要计算的video的embedding
- watched video IDs average embedding: 用户观看过的最后N个视频embedding的average pooling
- language embedding: 用户语言的embedding和当前视频语言的embedding
- time since last watch: 自上次观看同channel视频的时间
- #previous impressions: 该视频已经被曝光给该用户的次数
第四个特征是来反应用户看同类视频的间隔时间。有一点attention的意味。第五个特征可以避免同一个视频对用户进行反复的曝光。
6.2 特征表达
(1) Feature Engineering:
尽管深度学习在图像、语音和NLP等场景都能实现end-to-end的训练,没有了人工特征工程工作。然而在搜索和推荐场景,我们的很难把原始数据直接作为DNN的输入,特征工程仍然很重要。而特征工程中最难的是如何建模用户时序行为(temporal sequence of user actions),并且关联这些行为和要rank的item。
我们发现最重要的Signal是描述用户与商品本身或相似商品之间交互的Signal,这与Facebook在14年提出LR+GBDT模型的paper(Practical Lessons from Predicting Clicks on Ads at Facebook)中得到的结论是一致的。比如我们要度量用户对视频的喜欢,可以考虑用户与视频所在频道间的关系:

这两个连续特征的最大好处是具备非常强的泛化能力。另外除了这两个偏正向的特征,用户对于视频所在频道的一些PV(Page View页面浏览)但不点击的行为,即负反馈Signal同样非常重要。另外,我们还发现,把Candidate Generation阶段的信息传播到Ranking阶段同样能很好的提升效果,比如推荐来源和所在来源的分数。
在进行video embedding的时候,只保留用户最常点击的N个视频的embedding,剩余的长尾视频的embedding直接用0向量代替。
可能的解释主要有两点,一是从模型角度讲,出现次数较少的视频的embedding没法被充分训练。二是为了节省online serving中宝贵的内存资源。
(2) Embedding Categorical Features
NN更适合处理连续特征,因此稀疏的特别是高基数空间的离散特征需要embedding到稠密的向量中。每个维度(比如query/user_id)都有独立的embedding空间,一般来说空间的维度基本与log(去重后值的数量)相当。实际并非为所有的id进行embedding,比如视频id,只需要按照点击排序,选择top N视频进行embedding,其余置为0向量。而对于像“过去点击的视频”这种multivalent特征,与Candidate Generation阶段的处理相同,进行加权平均即可。
另外一个值得注意的是,同维度不同feature采用的相同ID的embedding是共享的,即对于相同域的特征可以共享embedding,比如用户点击过的视频ID,用户观看过的视频ID,用户收藏过的视频ID等等,这些公用一套embedding可以使其更充分的学习,同时减少模型的大小,加速模型的训练,但显然输入层仍要分别填充。
(3) Normalizing Continuous Features
NN对输入特征的尺度和分布都是非常敏感的,实际上基本上除了Tree-Based的模型(比如GBDT/RF),机器学习的大多算法都如此。我们发现归一化方法对收敛很关键,推荐一种排序分位归一到[0,1]区间的方法,如下图(归一化还可以加速模型的收敛)

除此之外,我们还把归一化后的的根号和平方作为网络输入,以期能使网络能够更容易得到特征的次线性(sub-linear)和(super-linear)超线性函数。(引入了特征的非线性)
6.3 建模期望观看时长

注意:上图中公式是E[T] (1+P),是相乘关系不是相除关系(这里参考一位知乎大佬的总结,但是它这块写错了)
下面对上面进行详细讲解:
在训练阶段,Youtube没有把问题当作一个CTR预估问题,而是通过weighted logistic 建模了用户的期望观看时间。
这里主要有两个问题:

对于传统的深度学习架构,输出层往往采用LR或者Softmax,在线上预测过程中,也是原封不动的照搬LR或者softmax的经典形式来计算点击率(广义地说,应该是正样本概率)。但是,YouTube这一模型的输出层没有使用LR,而是采用了weighted logistic regression。


为什么Youtube要预测的是用户观看时长,线上serving却是odds?
这就要提到YouTube采用的独特的训练方式Weighted LR,这里的Weight,对于正样本i来说就是观看时长Ti, 对于负样本来说,则指定了单位权重1。Weighted LR的特点是,正样本权重w 的加入会让正样本发生的几率变成原来的w倍。严格的说,Weighted LR中的单个样本的weight,并不是让这个样本发生的概率变成了weight倍,而是让这个样本,对预估的影响(也就是loss)提升了weight倍。因为观看时长的几率 的公式为: 非wieght的odds可以直接看成N+/N-,因为wieghted的lr中,N+变成了weight倍,N-没变,还是1倍,所以直接可得后来的odds是之前odds的weight倍。
非wieght的odds可以直接看成N+/N-,因为wieghted的lr中,N+变成了weight倍,N-没变,还是1倍,所以直接可得后来的odds是之前odds的weight倍。

模型采用了expected watch time per impression作为优化目标,所以如果简单使用LR就无法引入正样本的watch time信息。因此采用weighted LR,将watch time作为正样本的weight,在线上serving中使用![]() 做预测可以直接得到expected watch time的近似。
做预测可以直接得到expected watch time的近似。
6.4 不同隐层的实验

上图是离线利用hold-out一天数据在不同NN网络结构下的结果。如果用户对模型预估高分的反而没有观看,我们认为是预测错误的观看时长。weighted, per-user loss就是预测错误观看时长占总观看时长的比例。
我们对网络结构中隐层的宽度和深度方面都做了测试,从上图结果看增加隐层网络宽度和深度都能提升模型效果。而对于1024→512→256这个网络,测试的不包含归一化后根号和方式的版本,loss增加了0.2%。而如果把weighted LR替换成LR,效果下降达到4.1%。
七、总结
这篇论文被称为推荐系统领域的神文,相对于普通的学术论文,这篇重要的是提供一些新的点子。而对于类似google这种工业界发布的paper,特别是带有practical lessons的paper,很值得精读。下面一篇博客我可能会接着这篇文章写一下王喆大佬针对这篇paper提出的十个需要深度思考的问题(当然这篇文章中有几个问题已经提到)。