yolov4、yolov5学习笔记(up, 霹雳吧)
YOLOV4
一、网络结构
1.Backbone:cspDarknet53
CSPDarknet53采用cspdensenet结构,resblock依旧像yolov3一样

2.Neck:SPP, PAN
spp多尺度融合, 分别将短接, 5x5最大池化, 9x9最大池化, 13x13最大池化concat拼接
PAN,先下采样,再上采样,经过yolo曾输出

3.Head:YOLOv3
二、优化策略
1.消除graid敏感度, 计算下,x,y,w,h
当GT box 中心落到grid cell边界上的时候,tx需要接近无穷,这时候容易发生数值爆炸,计算困难。所以通过缩放sigmoid函数的范围,使函数值更容易取到0.
同时它的区间也缩放到了【-0.5, 1.5】之间。

增加了搜索范围,将距离边界距离gt box中心小于1.5的grid cell,列入搜索范围,只是上下左右搜寻。如果该grid cell中的anchor, iou满足超参数要求,则列为正样本,增加了样本的均衡,有利于训练。
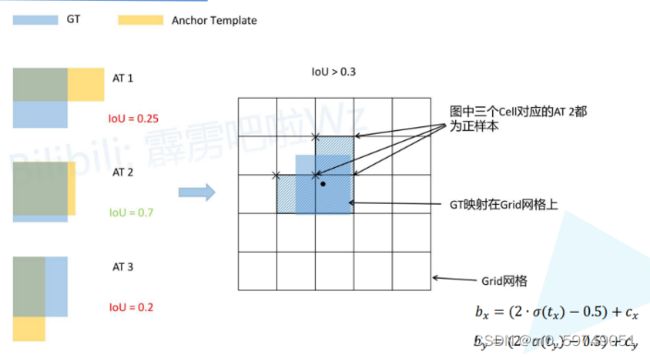
2.更新了anchors模板参数

但是yolov5中依旧使用了yolov3中的anchors模板
YOLOV5
一、网络结构
1.Backbone: New CSP-Darknet53
2.Neck: SPPF, New CSP-PAN
SPPF,将之前并行运算改成了串联, 减少了运算参数,提升了一倍的运算速度。
两个5x5卷积核替代一个9x9卷积核
三个5x5卷积核替代13x13卷积核

3.Head: YOLOv3 Head
二、数据增强
1.Mosaic
将四张图片拼在一起

2.cope paste
将实例分割的图像粘贴到别的背景中。

3.random affine
旋转, 平移, 缩放, 剪切sheer
4.mix up
将两张图片一一定透明度混合

5.Albumentations
传统视觉方法, 如果有这个库,则训练的时候开启,如果没有,默认关闭。requirments.txt文件中,默认注释掉了。
滤波、直方图均衡化以及改变图片质量等等
6.Augment HSV (Hue, Saturation, Value)
色度, 饱和度, 亮度
7.- Random horizontal fli
水平翻转
三、训练策略
Multi-scale training(0.5~1.5x) 多尺度训练
AutoAnchor(For training custom data)
自己数据集, 图片尺寸, 长宽比差距大, 可以通过聚合自动生成新的anchor
Warmup and Cosine LR scheduler
学习率, 先慢慢增长到预设的学习率, 然后再以cos函数衰减
EMA(Exponential Moving Average)
Mixed precision 混合精度训练, 可以提升训练速度,.half()
Evolve hyper-parameters 超参数,默认用人家的
四、损失计算
1.损失主要包括三个部分
分类损失
object损失(ciou)
定位损失
2.平衡不同尺度损失
小尺度物体难以监测, 所以损失比例因子大, 同理大尺度小

3.消除grid敏感度问题同yolov4