MindSpore脑瘤诊断项目实战及原理解析
1.项目背景
本实践任务目标是对人脑的脑瘤进行分类,数据集分为no_tumor(无肿瘤)、glioma_tumor(胶质瘤)、meningioma_tumor(脑膜瘤)、pituitary_tumor(垂体瘤)四类,范例图片如下。

本项目用到的数据集:链接: https://pan.baidu.com/s/1xWLEAfx4yepcurakRneG7g 提取码: kmk8
2.算法原理介绍
随着深度学习的快速发展,越来越多的研究者尝试将深度学习技术引入到肿瘤的检测项目中,在此,我们主要介绍其中的卷积神经网络以及深度残差网络。
1.卷积神经网络(CNN)
卷积神经网络(CNN)是一种深度学习模型或类似于人工神经网络的多层感知器,常用来分析视觉图像。其在图像识别中达到了前所未有的准确度,有着广泛的应用。主要结构包括输入层、卷积层、池化层以及全连接层,模型结构如下图所示。
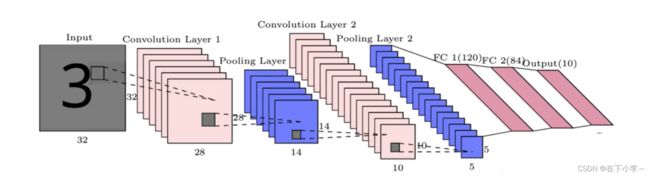
为什么要卷积?
如果没有卷积层,最终会得到大量需要训练的参数,而且大多数人都没有解决计算成本高昂任务的能力。此外,由于卷积神经网络具有的参数会更少,因此就可以避免出现过拟合现象。
为什么要池化?
池化层的核心目标之一是提供空间方差,这意味着CNN将能够识别对象的相应特征,即使它的外观以某种方式发生改变(例如出现噪点或人为的少量扰动),也就是说CNN受单一特征的影响较小。
2.深度残差网络(ResNet)
深度残差网络的提出是CNN图像史上的一件里程碑事件。ResNet刷新了CNN模型在ImageNet上的历史。
关于神经网络的退化问题:
假如你有一个浅层网络,你想通过向上堆积新层来建立深层网络。网络深度增加时,网络准确度出现饱和,甚至出现下降。这个现象就是退化问题(Degradation problem)。 网络越来越深,深层的层越来越难以学习到浅层特征图中的特征,导致网络精度降低
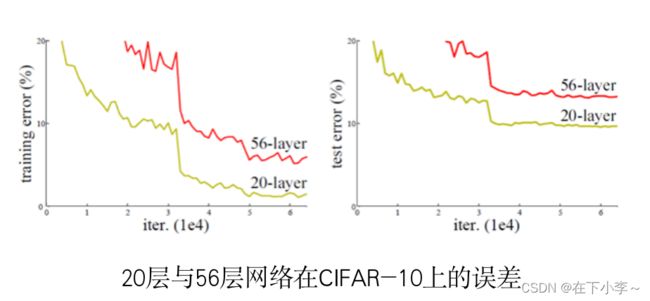
残差学习:
残差学习能解决退化问题,对于一个堆积层结构(几层堆积而成)当输入为 x 时其学习到的特征记为 H(x) ,现在我们希望其可以学习到残差 F(x) = H(x) - x ,这样其实原始的学习特征是 F(x) + x 当残差为0时,此时堆积层仅仅做了恒等映射,至少网络性能不会下降,实际上残差不会为0,这也会使得堆积层在输入特征基础上学习到新的特征,从而拥有更好的性能。

3.代码实践
1.导入依赖
from resnet import resnet50
from mindspore import nn, Model, context
import mindspore.dataset as ds
import mindspore.dataset.vision.c_transforms as c_trans
import mindspore.dataset.transforms.c_transforms as C2
from mindspore.train.callback import ModelCheckpoint, CheckpointConfig, LossMonitor, TimeMonitor, SummaryCollector
from mindspore.nn import SoftmaxCrossEntropyWithLogits
from mindspore.nn import Momentum, Accuracy
import matplotlib.pyplot as plt
import mindspore.common.dtype as mstype
from mindspore.train.callback import Callback2.定义变量和使用GPU
def main():
train_path = './data/Training'
test_path = './data/Testing'
ckpt_path = './CheckPoint'
summary_path = '/root/summary/DeepTumor'
label_list = {
'no_tumor': 0,
'glioma_tumor': 1,
'meningioma_tumor': 2,
'pituitary_tumor': 3
}
context.set_context(mode=context.GRAPH_MODE, device_target="GPU")
Training_size = 2870 # 训练集大小
batch_size = 32 # 每批次大小
eval_per_epoch = 2 # 检查精度的轮次间隔
epoch_size = 100 # 轮次数量3.用ds.ImageFolderDataset类从文件夹导入训练集和测试集
dataset1 = ds.ImageFolderDataset(dataset_dir=train_path, class_indexing=label_list, shuffle=True) # class_indexing=label_list ?
eval1 = ds.ImageFolderDataset(dataset_dir=test_path, class_indexing=label_list, shuffle=True)
4.数据增强
transforms_list = [c_trans.Decode(),
c_trans.Resize(size=[224, 224]),
# c_trans.Rescale(1.0 / 255.0, 0.0),
c_trans.HWC2CHW()]
dataset2 = dataset1.map(operations=transforms_list, input_columns=["image"])
eval2 = eval1.map(operations=transforms_list, input_columns=["image"])5.转换图像的数据类型(符合resNet50的要求)
type_cast_op = C2.TypeCast(mstype.float32)
dataset3 = dataset2.map(operations=type_cast_op, input_columns=["image"])
eval3 = eval2.map(operations=type_cast_op, input_columns=["image"])
6.构建resNet50网络
network = resnet50(class_num=4)7.设置loss和优化器
ls = SoftmaxCrossEntropyWithLogits(sparse=True, reduction="mean")
# optimization definition 优化器:Momentum
opt = Momentum(filter(lambda x: x.requires_grad, network.get_parameters()), learning_rate=0.001, momentum=0.9)
8.模型确定!
model = Model(network, loss_fn=ls, optimizer=opt, metrics={"Accuracy": Accuracy()})9.设置回调
# CheckPoint CallBack definition 使用回调函数保存模型
# save_checkpoint_steps:每执行多少step保存一次(每2个epoch保存一次)
config_ck = CheckpointConfig(save_checkpoint_steps=int(Training_size / batch_size) * eval_per_epoch,
keep_checkpoint_max=50)
ckpoint_cb = ModelCheckpoint(prefix="train_resnet_Tumor", directory=ckpt_path, config=config_ck)
# LossMonitor 用于打印loss(每执行多少step打印一次)
loss_cb = LossMonitor(int(Training_size / batch_size))
# TimeMonitor 用于打印耗时(每个epoch打印一次)
Time_cb = TimeMonitor(int(Training_size / batch_size))
10.设置数据集batch大小
dataset3 = dataset3.batch(batch_size=batch_size, drop_remainder=True)
eval3 = eval3.batch(batch_size=394, drop_remainder=True)
11.训练中验证模型精度
epoch_per_eval = {"epoch": [], "acc": []} # 方便最后打印精度曲线
eval_cb = EvalCallBack(model, eval3, eval_per_epoch, epoch_per_eval)
定义验证精度的回调函数类
class EvalCallBack(Callback):
def __init__(self, model, eval_dataset, eval_per_epoch, epoch_per_eval):
self.model = model
self.eval_dataset = eval_dataset
self.eval_per_epoch = eval_per_epoch
self.epoch_per_eval = epoch_per_eval
def epoch_end(self, run_context):
cb_param = run_context.original_args()
cur_epoch = cb_param.cur_epoch_num
if cur_epoch % self.eval_per_epoch == 0:
acc = self.model.eval(self.eval_dataset, dataset_sink_mode=False)
self.epoch_per_eval["epoch"].append(cur_epoch)
self.epoch_per_eval["acc"].append(acc["Accuracy"])
print(acc)
12.设置MindInsight训练可视化(非必要)
summary_collector = SummaryCollector(summary_dir=summary_path, collect_freq=1)
13.开始训练
model.train(epoch_size, dataset3, callbacks=[ckpoint_cb, loss_cb, Time_cb, summary_collector, eval_cb],
dataset_sink_mode=False)
eval_show(epoch_per_eval)
14.定义绘制精度曲线的方法
def eval_show(epoch_per_eval):
plt.xlabel("epoch number")
plt.ylabel("Model accuracy")
plt.title("Model accuracy variation chart")
plt.plot(epoch_per_eval["epoch"], epoch_per_eval["acc"], "red")
plt.savefig('./acc.png')
plt.show()
15.根据精度曲线选择最优模型 (保存的ckpt文件)

4.总结
读者可基于上述给到的baseline模型做进一步的改进和完善,主要有两个大方向,一是做数据增强,二是对现有模型进行进一步的改进。上述链接给到的原始数据集中的训练集图片仅2800多张,而且无脑瘤和各类脑瘤的训练集数量有明显的区别;并且各类脑瘤对于非专业的医学人士也很难分辨出来,任务本身难度很高。所以可以基于扩充无肿瘤的数据集以及采用较大规模的数据集这两点思想,对数据集进行增强,以期获得更好的效果。
5.参考文献
图像处理与增强 — MindSpore master documentation
https://arxiv.org/pdf/1512.03385.pdf
Model基本使用 — MindSpore master documentation
训练时验证模型 — MindSpore master documentation
收集Summary数据 — MindSpore master documentation
linux增加swap空间_shilei123456789666的博客-CSDN博客_linux 添加swap