【论文阅读笔记】GPT三部曲
GPT三部曲(GPT、GTP2、GPT3)
引言
这是某次武汉大学三行情书的第一名的英文版(机翻凑合看)
The crab is peeling my shell, the notebook is writing me.
The sky is full of me falling on the snowflakes on the maple leaves.
And you are missing me.
原文
螃蟹在剥我的壳,笔记本在写我。
漫天的我落在枫叶上雪花上。
而你在想我。
这是一个基于GPT3的模型对其的一段续写
The rain is full of my pain and my blood. My poems are coming out of your ears,
The wind is full of my words.
And you are missing me.
看着还挺是那么回事的。还有配图

有兴趣的话可以去https://gpt3demo.com/,有很多玩出花来的GPT3的应用。
在自然语言处理领域,我们始终没有大的有标注的数据集,因此NLP也没办法像CV一样有ImageNet这个100W张标注好图片的数据集,通过预训练好的模型进行微调应用到别的任务中。另一个原因是句子本身包含有的信息比图片少很多,一张图片所包含的信息量大约等于是个句子,所以想要使用一个大数据集进行训练,也得要1000W个句子样本。
并且由于NLP下游的任务很复杂,所以每个任务都需要有自己的模型,Word2Vec训练出一个词嵌入模型,但是后面子任务的模型还是要自己构造来适应各个子任务,但GPT只需要改变输入的形式。
GPT
想要解决的问题
在使用没有标号的文本进行训练的时候有两个困难:
-
不知道用什么样的目标函数,即我有一堆文本,我的损失函数到底长成什么样子呢?
比如我有语言模型,机器翻译,文本一致性都可以用来做预训练,但是都没有发现某一个特别好。都是只专精于某一个任务。
-
如何把我学到的文本表示传递到下游的子任务上面,因为NLP的子任务差别还是比较大的,没有一种简单的统一的,有效的一种表示能一致的应用到所有的子任务上面
所以GPT这篇文章提出了一个半监督(semi-supervised)的方法,在没有标号的文本上训练出一个比较大的语言模型,再在有标注的数据集上进行微调。
模型
GPT是基于Transformer的,和RNN相比,Transformer在进行迁移学习的时候,学到的feature更加稳健一些,能够更好的抽取出句子层面和段落层面的语义信息,Attention就是牛!
解决目标函数的问题
预训练
无标注!
我们有一个文本,里面每个词表示成 u i u_i ui,整个文本就表示成$= {u_1,u_2…u_n} $
GPT使用一个标准的语言模型的目标函数来最大化下面这个似然函数
L 1 ( U ) = ∑ i l o g P ( u i ∣ u i − k , . . . , u i − 1 ; Θ ) L_1(U)= \sum_{i}logP(u_i|u_{i-k},...,u_{i-1};\Theta) L1(U)=i∑logP(ui∣ui−k,...,ui−1;Θ)
语言模型就是要预测下一个词出现的概率,即每次拿 u i u_i ui前面k个连续的词(k即为窗口大小),通过模型 Θ \Theta Θ去预测 u i u_i ui出现的概率,每一个词都做这样的预测,从1到n,那他们的联合概率,最后就是这段文本出现的概率,这里做sum是因为取了log
也就是说,我想要训练一个模型,使他能够最大概率的输出和输入文本长的一样的文本。k是一个超参数,越大说明能看到的信息越多。
GPT使用的是Transformer的的解码器,回忆一下,Transformer的编码器和解码器,一个很大的区别是编码器是能看到上下文的,而解码器是Masked的,有掩码,在计算Attention的时候是0,所以是看不到下文的。
再详细解释一下这个模型:
前面k个词记作 U = ( u _ k , . . . , u _ 1 ) U=(u_{\_k},...,u_{\_1}) U=(u_k,...,u_1)
h 0 = U W e + W p h l = t a r n s f o r m e r _ b l o c k ( h l − 1 ) P ( u ) = = s o f t m a x ( h n W e T ) h_0=UW_e+W_p \\ h_l=tarnsformer\_block(h_{l-1})\\ P(u)==softmax(h_nW_e^T) h0=UWe+Wphl=tarnsformer_block(hl−1)P(u)==softmax(hnWeT)
把 U U U映射到词嵌入矩阵,再加上位置编码,得到最初的输入
反复丢进transformer块,上一次的输出当作输入
最后再做一次映射,softmax输出
和Bert的差别:
Bert使用的并不是标准的语言模型,而是带掩码的语言模型去做完形填空(挖掉中间的,去预测)既能看到之前的词,也能看到之后的词,所以使用的是transformer的编码器,GPT的目标函数更难一些(预测未来和完形填空)。
微调
有标注!
P ( y ∣ x 1 , . . . , x m ) = s o f t m a x ( h l m W y ) P(y|x^1,...,x^m)=softmax(h_l^mW_y) P(y∣x1,...,xm)=softmax(hlmWy)
将一整句话 x 1 , . . . , x m x^1,...,x^m x1,...,xm丢到训练好的GPT模型中,得到transformer最后一个block的输出 h m h_m hm成一个输出层再做一个softmax
L 2 ( C ) = ∑ ( x , y ) l o g P ( y ∣ x 1 , . . . , x m ) L_2(C)=\sum_{(x,y)}logP(y|x^1,...,x^m) L2(C)=(x,y)∑logP(y∣x1,...,xm)
然后所有的序列对输入进去概率求和,一个标准的分类模型。
虽然我们在微调时关心的时 L 2 L_2 L2,但其实我们把 L 1 L_1 L1加进来也有很好的效果。
L 3 ( C ) = L 2 ( C ) + λ ∗ L 1 ( C ) L_3(C)=L_2(C)+\lambda*L_1(C) L3(C)=L2(C)+λ∗L1(C)
λ \lambda λ是超参数
即在微调时有两个目标函数:
L 1 L_1 L1:给定一段文本,去预测他的下一个词
L 2 L_2 L2:给定完整序列,去预测他的标号
那么怎样把输入表示成一个序列 x 1 , . . . , x m x^1,...,x^m x1,...,xm和一个标注 y y y呢?
解决输入表示的问题

-
分类
如:给一段文本,判断其标注,比如对评论进行情感分析。
Start:开始符
Text:文本
Extract:抽取符,放在序列结尾,抽取整个文本的特征,包含整个句子的信息
将Extract抽取特征送进一个线性层Linear做softmax,有10类就输出10维向量。
-
蕴含
判断前面的Premise是否支持后面的Hypothesis
如:Premise:A送给B一束玫瑰
Hypothesis:A喜欢B
则Premise支持Hypothesis
Delim:分隔符
-
相似
Text1和Text2相似则Text2和Text1也相似,但在语言模型中先后顺序是有区别的,所以做了两个序列。
最后是一个是相似还是不相似的二分类问题
-
多选题
问一个问题,选答案,如果有n个问题就构造n个答案
以上过的输入的构造都是微调时的,有标注的,可以看到与训练好的Transformer模型是不需要发生变化的,这是GPT和之前工作的差别。
Start、Extract、Delim都是特殊字符,区别于文本中内容。
BookCorpus数据集,有7000篇没有被发表的书
12层Transformer解码器,每层维度768(Bert_base也是这么大)
GPT2
Zero_shot横空出世
时间线:
对一个任务收集一个数据集,训练模型做预测(泛化性差)
多任务学习:在不同的数据集上训练一个同模型,甚至采用多个损失函数达到一个模型能够在多个任务上使用(NLP用的很少)
GPT和Bert提出了在较大数据集上预训练模型,有标注微调。
但还是有问题:对每一个下游任务,还是得微调
还是要收集有标号的数据
所以在拓展到一个新任务上的时候还是有成本的。
所以GPT2,在处理下游任务时,使用Zero-Shot:不需要下游任务的标注信息,也不用重新训练我的模型。
GPT2和GPT的区别
我们在GPT预训练模型的时候,是在自然语言上进行训练的,在微调的时候,我们对输入进行了构造,有Start、Extract、Delim这些特殊符号,这些符号在之前预训练时是没有出现过的,所以模型也不认识这些。所以微调的时候模型会去重新认识这些符号,需要调整模型。所以我们在进行下游任务,构造输入时,不能引入这些没见过的符号,而是使输入长得和预训练模型时的输入一样,都接近自然语言。
如:对于一个翻译子任务
(translate to french, english text, french text)
构造一个这样的序列translate to french叫做prompt(提示)
如:对于一个阅读理解子任务
(answer the question, document, question, answer)
训练数据集
Common Crawl:爬虫抓取网页,但噪声很大,很多网页都是垃圾
GPT2用的:抓取Reddit上karma值大于3的(用户对帖子的评价)得到4500w个链接再把800w个文本抽取出来
GPT2总结:力大砖飞
GPT3
Language Models are Few-Shot Learners
从Zero-Shot又变回了Few-Shot,有样本,但是只有一点点
摘要
1750亿个可学习参数,但是由于模型太大了,所以在做子任务是不做任何模型的更新或者微调,就算是Few-Shot给了一些样本,但也不微调,因为微调就要算梯度,模型太大,成本太高。GPT3的效果很好。
评估:Zero-Shot,One-Shot,Few-Shot都做了
模型
首先他讲了一下传统的微调,注意并不是用在GPT3中的

然后他讲了GPT3中的Zero-Shot,One-Shot,Few-Shot
Zero-Shot
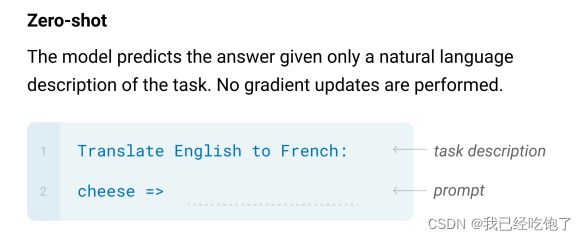
和GPT2类似
One-Shot

这里注意虽然有一个样本,但是这个样本只是用来做预测的,并不是做训练进行调参的。样本的意义是在前向推理的时候,通过Attention机制抓取到一些信息,用来做预测。
Few-Shot

GPT3和GPT2的模型基本相同,有一点改变是把Sparse Transformer(之后学)的改动拿了过来(一篇63页的论文,模型架构就写了半页),设计了8个不同大小的模型

n p a r a m s n_{params} nparams:可训练参数大小
n l a y e r s n_{layers} nlayers:层数
d m o d e l d_{model} dmodel:每一层向量的维度
n h e a d s n_{heads} nheads:多头注意力机制头的个数
d h e a d d_{head} dhead:每个头的维度的大小
B a t c h S i z e Batch Size BatchSize:训练时小批量大小
L e a r n i n g R a t e Learning Rate LearningRate:学习率
计算复杂度和层数是线性关系,和宽度是平方关系,所以GPT3这个模型还是比较扁的
训练数据集
对Common Crawl做一个过滤:
- 把Common Crawl中的部分当作负类,GPT2用的数据集当作正类,做一个二分类,选出Common Crawl有用的网页。
- 去重,lsh算法(判断集合和另一个大集合的相似度,一篇文章就是一堆词的集合)
另外加了一些高质量数据集
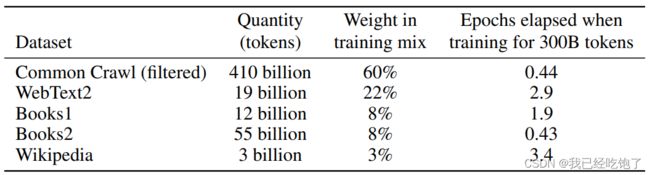
训练过程文章没细说。。。接下来是各种实验和其他模型的对比。
局限性
很长的文本生成(如小说)很难
解码器只能向前看
语言模型分不清重点,比如很多虚词根本不重要,训练慢
无法解释
之后是GPT3的一些社会影响,和一些求生欲(性别,种族,宗教相关)
彩蛋
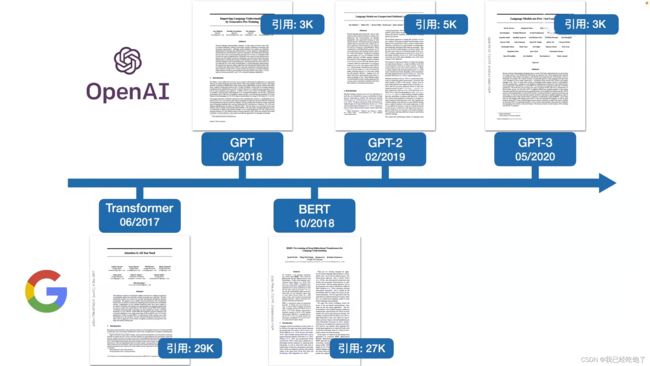
BERT与GPT的恩怨情仇
在Google的Transformer横空出世之后,OpenAI采用Transformer的解码器构建了GPT,几乎是在同期Google采用编码器构建了Bert并且取得了比GPT更好的效果,但相传Bert是其一作偶然间有了一个想法,几个月这篇文章就问世了,且从模型大小上Bert-Base就是对标了GPT,有点挑衅的意思了。于是,已经站队了解码器的OpenAI团队只能继续做大自己的模型。在更大的模型上训练,GPT2诞生了,再后来,又发动钞能力做出了GPT3。说实话,我还挺佩服OpenAI的,一直是致力于强人工智能的探索方向,包括一些目标函数的选择也更难一些,Google只是在一些小任务上寻求突破,期待后续的军备竞赛。