经典卷积神经网络(二) Pytorch torchvision.models
接着上一篇 Google 阵营Tensorflow /Keras为我们提供了大量pre-trained经典卷积网络模型, 这一篇继续介绍Pytorch如何使用Pytorch torchvision.models中的经典模型进行快速迁移学习。
相比Tensorflow主要多了Facebook团队发布的 SqueezeNet、ShuffleNet、Wide ResNet、MNASNet模型。
torchvision.models
Pytorch一共提供29个经典卷积神经模型

Pytorch官网TORCHVISION.MODELS
迁移学习代码实现
迁移学习十分简单,直接使用torchvision.models.Xnet去掉最后一个modul便可以实现。
import torchvision
base_model=torchvision.models.alexnet(pretrained=False)
model = nn.Sequential(*list(trained_model.children())[:-1],
Flatten(),
nn.Linear(512, 5)
).to(device)
optimizer = optim.Adam(model.parameters(), lr=1e-3)
criteon = nn.CrossEntropyLoss()
另外,Pytorch十分方便的地方是所有模型的源代码可以直接从官网推荐中进行拷贝,比如,点击SOURCE,便可以得到Alexnet的源代码和预训练权重文件地址
torchvision.models网址

import torch
import torch.nn as nn
# load_state_dict_from_url加载地址替换为torch.hub
#from .utils import load_state_dict_from_url
try:
from torch.hub import load_state_dict_from_url
except ImportError:
from torch.utils.model_zoo import load_url as load_state_dict_from_url
__all__ = ['AlexNet', 'alexnet']
model_urls = {
'alexnet': 'https://download.pytorch.org/models/alexnet-owt-4df8aa71.pth',
}
class AlexNet(nn.Module):
def __init__(self, num_classes=1000):
super(AlexNet, self).__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 64, kernel_size=11, stride=4, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(64, 192, kernel_size=5, padding=2),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
nn.Conv2d(192, 384, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(384, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.Conv2d(256, 256, kernel_size=3, padding=1),
nn.ReLU(inplace=True),
nn.MaxPool2d(kernel_size=3, stride=2),
)
self.avgpool = nn.AdaptiveAvgPool2d((6, 6))
self.classifier = nn.Sequential(
nn.Dropout(),
nn.Linear(256 * 6 * 6, 4096),
nn.ReLU(inplace=True),
nn.Dropout(),
nn.Linear(4096, 4096),
nn.ReLU(inplace=True),
nn.Linear(4096, num_classes),
)
def forward(self, x):
x = self.features(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.classifier(x)
return x
[docs]def alexnet(pretrained=False, progress=True, **kwargs):
r"""AlexNet model architecture from the
`"One weird trick..." `_ paper.
Args:
pretrained (bool): If True, returns a model pre-trained on ImageNet
progress (bool): If True, displays a progress bar of the download to stderr
"""
model = AlexNet(**kwargs)
if pretrained:
state_dict = load_state_dict_from_url(model_urls['alexnet'],
progress=progress)
model.load_state_dict(state_dict)
return model
SqueezeNet
背景
SqueezeNet 由伯克利&斯坦福的研究人员合作发表于 ICLR-2017。从名字——SqueezeNet 就知道,本文的新意是 squeeze,squeeze 在 SqueezeNet 中表示一个 squeeze 层。论文的题目直接的表达了论文的结果,实现了与AlexNet相同精度,但只用了1/50的参数量。且模型的参数量最少可以压缩到0.5M,这是AlexNet的1/510的参数量。
对于一个给定的正确率,通常可以找到多种CNN架构来实现与之相近的正确率。其中,参数数量更少的CNN架构有如下优势:
(1)更高效的分布式训练
服务器间的通信是分布式CNN训练的重要限制因素。对于分布式 数据并行 训练方式,通信需求和模型参数数量正相关。小模型对通信需求更低。
(2)减小下载模型到客户端的额外开销
比如在自动驾驶中,经常需要更新客户端模型。更小的模型可以减少通信的额外开销,使得更新更加容易。
(3)便于FPGA和嵌入式硬件上的部署
常用的模型压缩技术有:
(1)奇异值分解(singular value decomposition (SVD))
(2)网络剪枝(Network Pruning):使用网络剪枝和稀疏矩阵
(3)深度压缩(Deep compression):使用网络剪枝,数字化和huffman编码
(4)硬件加速器(hardware accelerator)
网络结构
类似于inception思想 ,提出fire module。fire module包含两部分分:squeeze层+expand层。
使用以下三个策略来减少SqueezeNet设计参数:
(1)使用1∗1卷积代替3∗3 卷积:参数减少为原来的1/9
(2)减少输入通道数量:这一部分使用squeeze layers来实现
(3)将欠采样操作延后,可以给卷积层提供更大的激活图:更大的激活图保留了更多的信息,可以提供更高的分类准确率
其中,(1)和(2)可以显著减少参数数量,(3)可以在参数数量受限的情况下提高准确率。
SqueezeNet以卷积层(conv1)开始,接着使用8个Fire modules (fire2-9),最后以卷积层(conv10)结束。每个fire module中的filter数量逐渐增加,并且在conv1, fire4, fire8, 和 conv10这几层之后使用步长为2的max-pooling,即将池化层放在相对靠后的位置,这使用了以上的策略(3)


如上图,左边为原始的SqueezeNet,中间为包含simple bypass的改进版本,最右侧为使用complex bypass的改进版本。在下表中给出了更多的细节。

结果

SVD方法能将预训练的AlexNet模型压缩为原先的1/5,top1正确率略微降低。网络剪枝的方法能将模型压缩到原来的1/9,top1和top5正确率几乎保持不变。深度压缩能将模型压缩到原先的1/35,正确率基本不变。SqeezeNet的压缩倍率可以达到50以上,并且正确率还能有 略微的提升。注意到几时使用未进行压缩的32位数值精度来表示模型,SqeezeNet也比压缩率最高的模型更小,同时表现也更好。
如果将深度压缩(Deep Compression)的方法用在SqeezeNet上,使用33%的稀疏表示和8位精度,会得到一个仅有0.66MB的模型。进一步,如果使用6位精度,会得到仅有0.47MB的模型,同时正确率不变。
此外,结果表明深度压缩不仅对包含庞大参数数量的CNN网络作用,对于较小的网络,比如SqueezeNet,也是有用的。将SqueezeNet的网络架构创新和深度压缩结合起来可以将原模型压缩到1/510。
讨论
以下是网络设计中的一些要点:
(1)为了使 1∗11∗1 和 3∗33∗3 filter输出的结果又相同的尺寸,在expand modules中,给3∗33∗3 filter的原始输入添加一个像素的边界(zero-padding)。
(2)squeeze 和 expand layers中都是用ReLU作为激活函数
(3)在fire9 module之后,使用Dropout,比例取50%
(4)注意到SqueezeNet中没有全连接层,这借鉴了Network in network的思想
(5)训练过程中,初始学习率设置为0.04,,在训练过程中线性降低学习率。更多的细节参见本项目在github中的配置文件。
(6)由于Caffee中不支持使用两个不同尺寸的filter,在expand layer中实际上是使用了两个单独的卷积层(1∗11∗1 filter 和 3∗33∗3 filter),最后将这两层的输出连接在一起,这在数值上等价于使用单层但是包含两个不同尺寸的filter。
参考
论文:SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size.
代码的github链接:https://github.com/rcmalli/keras-squeezenet
参考博文: https://blog.csdn.net/csdnldp/article/details/78648543
ShuffleNet
背景
ShuffleNet v1是由旷视科技在2017年底提出的轻量级可用于移动设备的卷积神经网络。
在近期的网络中,pointwise convolution的出现使得所需计算量极大的增多,于是作者提出了pointwise group convolution来降低计算量,但是group与group之间的几乎没有联系,影响了网络的准确率,于是作者又提出了channel shuffle来加强group之间的联系。在一定计算复杂度下,网络允许更多的通道数来保留更多的信息,这恰恰是轻量级网络所追求的。
从Fig.1(a)中我们可以看出组卷积会导致每个组的输出仅与组内特征相关,没有组间相互交流,会导致精度下降。(b)和©中的操作,是将组与组之间的信息进行重新排序,让各组之间信息混合,实际上©就是网络中的一个shuffle unit。

shuffleNet v1中的shuffle unit类似于ResNet中的bottleneck unit(Fig.2(a)),(b)为一个标准的shuffle unit,将1x1的pointwise group convolution后加入channel shuffle,再进行depthwise convolution,最后再进行一次pointwise group convolution,需要注意的是,在第二个pointwise group convolution后,不添加ReLu层,而是在Add之后才添加,我认为这是防止信息损失过量。©中为步长为2的shuffle unit,可用于降采样。 通过使用depthwise convolution以及pointwise group convolution,shuffleNet可以在一定计算资源限制得情况下,竟可能的增加通道信息,提高准确率。
论文中的实验结果显示,在其他网络中,准确率随着组数group增大而提高到一定程度后,准确率开始下降,这可以说明,组数过多导致组内信息太少,丢失精度。而对于shuffleNet来说,在小网络中,组数越多,反而相较其他网络来说,准确率越高。
目前大部分的模型加速和压缩文章在对比加速效果时用的指标都是FLOPs(float-point operations),这个指标主要衡量的就是卷积层的乘法操作。但是这篇文章通过一系列的实验发现FLOPs并不能完全衡量模型速度,比如在Figure1(c)(d)中,相同MFLOPs的网络实际速度差别却很大,因此以FLOPs作为衡量模型速度的指标是有问题的。
论文中提出了FLOPs不能作为衡量目标检测模型运行速度的标准,因为MAC(Memory access cost)也是影响模型运行速度的一大因素。

上图可以看出,相同FLOPs的模型,速度上可能会差别很大。
由此,作者通过实验得出4个设计小模型的准则:
(1)卷积操作时,输入输出采用相同通道数可以降低MAC
(2)过多的组,会导致MAC增加
(3)分支数量过少,模型速度越快
(4)element-wise操作导致速度的消耗,远比FLOPs上体现的多
网络结构
根据以上四点准则,作者在shuffleNet V1的基础上提出了修改。

Fig.3 (a)(b)为shuffleNet V1中的结构,©(d)中为shuffleNet V2中的结构。
具体结构如下表:
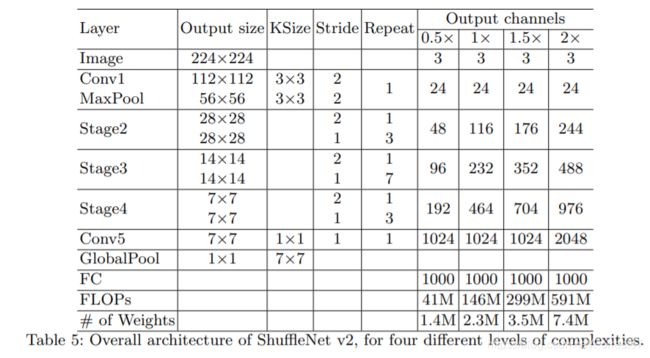
结果
Table8是关于一些模型在速度、精度、FLOPs上的详细对比。实验中不少结果都和前面几点发现吻合,比如MobileNet v1速度较快,很大一部分原因是因为简单的网络结构,没有太多复杂的支路结构;IGCV2和IGCV3因为group操作较多,所以整体速度较慢;Table8最后的几个通过自动搜索构建的网络结构,和前面的第3点发现对应,因为支路较多,所以速度较慢。
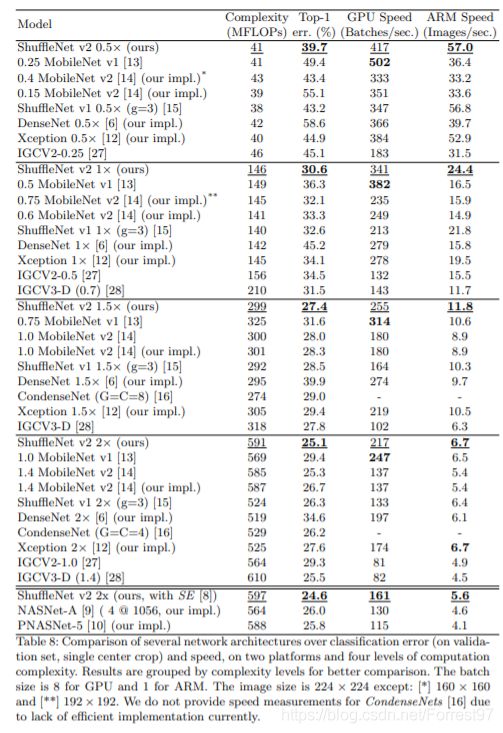
讨论
论文:ShuffleNet V2: Practical Guidelines for Efficient CNN Architecture Design.
代码的github链接:https://github.com/MG2033/ShuffleNet
参考博文: https://blog.csdn.net/huang_nansen/article/details/84075030
https://blog.csdn.net/u014380165/article/details/81322175
Wide ResNet
背景
网络结构
结果
讨论
论文:Very Deep Convolutional Networks for Large-Scale Image Recognition.
代码的github链接:https://github.com/liuzhuang13/DenseNet
参考博文: https://github.com/machrisaa/tensorflow-vgg
MNASNet
背景
网络结构
结果
讨论
论文:Very Deep Convolutional Networks for Large-Scale Image Recognition.
代码的github链接:https://github.com/liuzhuang13/DenseNet
参考博文: https://github.com/machrisaa/tensorflow-vgg