一文掌握 MobileNetV3 在 TorchVision 中的实现细节
TorchVision v0.9 中新增了一系列移动端友好的模型,可用于处理分类、目标检测、语义分割等任务。
本文将深入探索这些模型的代码,分享值得注意的实现细节,解释这些模型的配置和训练原理,并解读模型优化过程中官方做出的重要权衡。
本文的目标是展示模型中没在原始论文和资料库中记载的技术细节。
网络架构
MobileNetV3 架构的实现严格遵守了原始论文中的设定,支持用户自定义,为构建分类、目标检测和语义分割 Backbone 提供了不同的配置。 它的结构设计与 MobileNetV2 类似,两者共用相同的构建模块。
开箱即用。 官方提供了两种变体:Large 和 Small。二者是用相同的代码构建的,唯一的区别是配置(模块的数量、大小、激活函数等)不同。
配置参数
尽管用户可以自定义 InvertedResidual 设置,并直接传递给 MobileNetV3 类,但对于大多数应用而言,开发者可以通过向模型构建方法传递参数,来调整已有配置。 一些关键的配置参数如下:
-
width_mult参数是一个乘数,决定模型管道的数量,默认值是 1,通过调节默认值可以改变卷积过滤器的数量,包括第一层和最后一层,实现时要确保过滤器的数量是 8 的倍数。这是一个硬件优化技巧,可以加快操作的向量化进程。 -
reduced_tail参数主要用于运行速度优化,它使得网络最后一个模块的管道数量减半。该版本常被用于目标检测和语义分割模型。根据 MobileNetV3 相关论文描述,使用 reduced_tail 参数可以在不影响准确性的前提下,减少 15% 的延迟。 -
dilated参数主要影响模型最后 3 个 InvertedResidual 模块,可以将这些模块的 Depthwise 卷积转换成 Atrous 卷积,用于控制模块的输出步长,并提高语义分割模型的准确性。
实现细节
MobileNetV3 类负责从提供的配置中构建一个网络,实现细节如下:
-
最后一个卷积模块将最后一个 InvertedResidual 模块的输出扩大了 6 倍。该实现方法可以适应不同的乘数参数。
-
与 MobileNetV2 模型类似,分类器最后一个 Linear 层之前,存在一个 Dropout 层。
InvertedResidual 类是该网络的主要构建模块,需要注意的实现细节如下:
-
如果输入管道和扩展管道相同,则无需 Expansion 步骤。这发生在网络的第一个卷积模块上。
-
即使 Expanded 管道与输出通道相同,也总是需要 Projection 步骤。
-
Depthwise 模块的激活优先于 Squeeze-and-Excite 层,可以在一定程度上提高准确率。
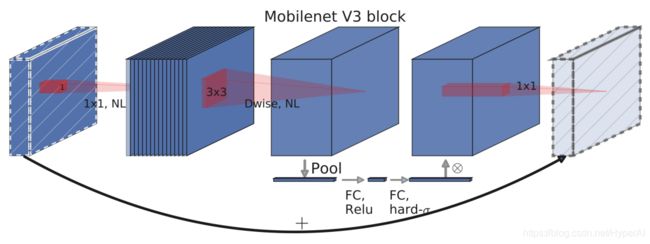
MobileNetV3 模块架构示意图
分类
此处将讲解预训练模型的基准及配置、训练和量化细节。
Benchmarks
初始化预训练模型:
large = torchvision.models.mobilenet_v3_large(pretrained=True, width_mult=1.0, reduced_tail=False, dilated=False)
small = torchvision.models.mobilenet_v3_small(pretrained=True)
quantized = torchvision.models.quantization.mobilenet_v3_large(pretrained=True)
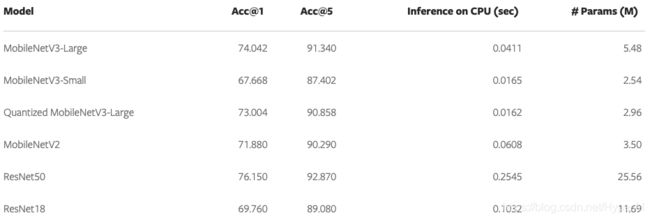
新旧模型详细 benchmark 对比
如图所示,如果用户愿意牺牲一点准确性,来换取大约 6 倍的速度增加,则 MobileNetV3-Large 可以成为 ResNet50 的替代品。
注意,此处的推理时长是在 CPU 上测量得出的。
训练过程
将所有预训练模型都配置为宽度乘数为 1、具有 full tails 的 non-dilated 模型,并在 ImageNet 上拟合。Large 和 Small 变体都是用相同的超参和脚本训练的。
快速和稳定的模型训练
正确配置 RMSProp 对于加快训练过程和保证数值稳定性至关重要。论文作者在实验中用的是 TensorFlow,运行过程中使用了与默认值相比,相当高的 rmsprop_epsilon。
通常情况下,这个超参数是用来避免零分母出现的,因此它的值很小,但在这个特定模型中,选择正确的数值对避免损失中的数值不稳定很重要。
另一个重要细节是,尽管 PyTorch 和 TensorFlow 的 RMSProp 实现通常表现相似,但在此处的设置中,需要注意两个框架在处理 epsilon 超参数时的区别。
具体来说,PyTorch 在平方根计算之外添加了epsilon,而 TensorFlow 是在里面添加了 epsilon。这使得用户在移植本文的超参数时,需要调整 epsilon 值,可以用公式 PyTorch_eps=sqrt(TF_eps) 来计算合理近似值。
通过调整超参数和改进训练过程,来提高模型准确度
配置优化器,实现快速和稳定的训练后,就可以着手于优化模型的准确性了。有一些技术可以帮助用户实现这一目标。
首先,为了避免过拟合,可以使用 AutoAugment 和 RandomErasing 来增强数据。此外,用交叉验证法来调整权值衰减等参数,训练结束后对不同 epoch 检查点进行权重平均,也意义重大。最后,用 Label Smoothing、随机深度和 LR noise injection 等方法,也能使总体准确率提高至少 1.5%。
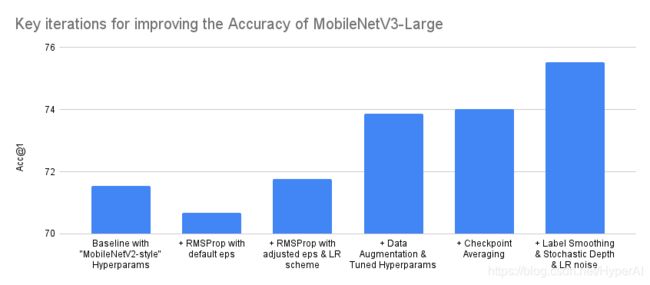
提高 MobileNetV3-Large 准确率的关键迭代
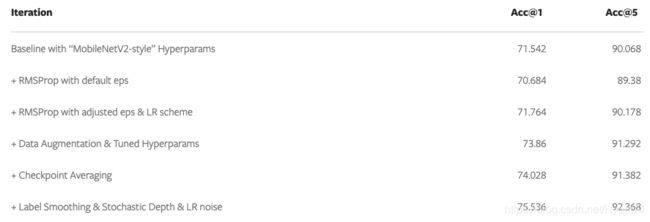
MobileNetV2-style 超参基线
注意,一旦达到设定的准确度,将在验证集上验证模型性能。这个过程有助于检测过拟合。
量化
为 MobileNetV3-Large 变体的 QNNPACK 后端提供了量化权重,使得运行速度提高了 2.5 倍。为了量化模型,这里使用了量化感知训练 (QAT)。
注意,QAT 允许对量化的影响进行建模,并调整权重,以便提高模型准确度。与简单训练的模型量化结果相比,准确度提高了 1.8%:

目标检测
本部分将先提供已发布模型的基准,然后讨论 MobileNetV3-Large Backbone 是如何与 FasterRCNN 检测器一起被用于 Feature Pyramid Network,从而进行目标检测的。
此外还将解释该网络是如何训练和调整的,以及必须要权衡利弊的地方(本部分内容不涉及如何与 SSDlite 一起使用的细节)。
Benchmarks
初始化模型:
high_res = torchvision.models.detection.fasterrcnn_mobilenet_v3_large_fpn(pretrained=True)
low_res = torchvision.models.detection.fasterrcnn_mobilenet_v3_large_320_fpn(pretrained=True)

新旧模型之间的 benchmark 对比
可以看到,如果用户愿意为了 5 倍快的训练速度,牺牲一点精度的话,带有 MobileNetV3-Large FPN backbone 的高分辨率 Faster R-CNN,可以替代同等 ResNet50 模型。
实现细节
检测器用的是 FPN-style backbone,它可以从 MobileNetV3 模型的不同卷积中提取特征。 默认情况下,预训练模型使用的是第 13 个 InvertedResidual 模块的输出,和池化层之前的卷积的输出。该实现也支持使用更多阶段的输出。
所有从网络中提取的特征图,都由 FPN 模块将其输出投射到 256 个管道,这可以极大提高网络速度。 这些由 FPN backbone 提供的特征图,将被FasterRCNN 检测器用来提供不同规模的 box 和 class 预测。
训练和调优过程
目前官方提供了两种预训练模型,能在不同分辨率下进行目标检测。这两个模型都是在 COCO 数据集上,用相同的超参数和脚本进行训练的。
高分辨率检测器是用 800-1333px 的图像进行训练的,而移动端友好的低分辨率检测器,则是用 320-640px 的图像进行训练的。
提供两套独立预训练权重的原因是,直接在较小的图像上训练检测器,与将小图像传递给预训练的高分辨率模型相比,会导致精度增加 5 mAP。
两个 backbone 初始化用的都是 ImageNet 上的权重,训练过程中还对其权重的最后三个阶段进行了微调。
通过调整 RPN NMS 的阈值,可以对移动端友好的模型进行额外的速度优化。 牺牲 0.2 mAP 的精度,就能够将模型的 CPU 速度提高约 45%。优化细节如下:


Faster R-CNN MobileNetV3-Large FPN 模型的预测示意图
语义分割
本部分先提供了一些已公布的预训练模型基准,然后将讨论 MobileNetV3-Large backbone 是如何与 LR-ASPP、DeepLabV3 和 FCN 等分割 head 结合,进行语义分割的。
此外还将解释网络的训练过程,并为速度关键应用提出一些备选优化技术。
Benchmarks
初始化预训练模型:
lraspp = torchvision.models.segmentation.lraspp_mobilenet_v3_large(pretrained=True)
deeplabv3 = torchvision.models.segmentation.deeplabv3_mobilenet_v3_large(pretrained=True)

新旧模型之间的详细基准对比
如图可知,在大多数应用中,带有 MobileNetV3-Large backbone 的 DeepLabV3 是 FCN 与 ResNet50的可行替代品,**在保证类似准确度的前提下,运行速度提升 8.5 倍。**此外 LR-ASPP 网络在所有指标上的表现,都超过了同等条件下的 FCN。
实现细节
本部分将讨论已测试的分割 head 的重要实现细节。注意,本节中描述的所有模型都使用扩张 MobileNetV3-Large backbone。
LR-ASPP
LR-ASPP 是 MobileNetV3 论文作者提出的 Reduced Atrous Spatial Pyramid Pooling 模型的精简版本。与 TorchVision 中的其他分割模型不同,它不使用辅助损失,而是使用低级和高级特征,输出步长分别为 8 和 16。
与论文中使用的 49x49 的 AveragePooling 层和可变步长不同,此处是用 AdaptiveAvgPool2d 层来处理全局特征。
这可以为用户提供一个通用的实现方法,在多个数据集上跑通。 最后在返回输出之前,总会产生一个双线性插值,以确保输入和输出图像的尺寸完全匹配。
DeepLabV3 & FCN
MobileNetV3 与 DeepLabV3 和 FCN 的组合与其他模型的组合非常相似,这些方法的阶段评估与 LR-ASPP 相同。
需要注意的是,这里没有使用高级和低级特征,而是在输出跨度为 16 的特征图上附加正常损失,在输出跨度为 8 的特征图上附加辅助损失。
FCN 在速度和准确度方面都不及 LR-ASPP,因此这里不作考量。预训练权重仍然可用,只需对代码稍做修改。
训练和调优过程
这里提供了两个可用于语义分割的 MobileNetV3 预训练模型:LR-ASPP 和 DeepLabV3。 这些模型的 backbone 是用 ImageNet 权重进行初始化的,并进行了端到端训练。
两个架构都是在 COCO 数据集上使用相同脚本和类似超参进行训练的。
通常情况下,在推理过程中,图像的大小会被调整为 520 像素。一个可选的速度优化方案是,用高分辨率预训练权重,来构建低分辨率的模型配置,并将推理大小减少到 320 像素。这会让 CPU 的执行时间提高约 60%,同时牺牲几个 mIoU point。

优化后的详细数字

LR-ASPP MobileNetV3-Large 模型预测示例
以上就是本期汇总的 MobileNetV3 实现细节,希望这些能让你对该模型有进一步的了解和认识。
参考:
MobileNetV3 论文
PyTorch Blog