多智能体深度强化学习——MADDPG算法代码分析(tensorflow)
写这篇的目的主要是总结一下最近对MADDPG这篇文章的学习过程。其中对文章的实验部分理解还不够深刻,如果某些该领域的大神能看到这篇博客的话,诚挚希望您们提供一些建议和指导!
其中一个问题我已在github提出了个issue: https://github.com/openai/maddpg/issues/55
1. MADDPG(Multi-Agent Deep Deterministic Policy Gradient)算法介绍(主要参考论文)
MADDPG早在2017年OpenAI就已经提出了,详细讲MADDPG这个算法的博客也非常多,以下是我看过的一些相关文章,包括了这些文章里面的一些引用文章。
1.1 MADDPG相关的有用文章
- 算法对应的论文:《Multi-Agent Actor-Critic for Mixed Cooperative-Competitive Environments》
- github对应的代码:https://github.com/openai/maddpg
- 原文章翻译:https://blog.csdn.net/qiusuoxiaozi/article/details/79066612
- 探秘多智能体强化学习-MADDPG算法原理及简单实现:https://ask.hellobi.com/blog/wenwen/12283
- 深度解析OPENAI-MADDPG:https://blog.csdn.net/kysguqfxfr/article/details/100070584
1.2 算法简介
文章其实是先有个将DDPG算法应用到多智能体环境的一个baseline算法,再对此算法做了两种改进,改进的思路也就是不断放松之前智能体能获得其他智能体策略这一非常强的假设。
Baseline(基本方法)——对DDPG的改进
Baseline的算法就是将DDPG这一单智能体的深度强化学习actor-critic的方法进行扩展,使其适用于多智能体环境,基本思想依然是中心化训练和去中心化的执行(Centralized training and Decentralized execution),即在训练过程中每一个智能体的critic网路都会收集所有智能体的状态和动作信息,但在训练阶段,只由每个智能体的actor网络根据局部信息(即智能体自己的动作和状态)做出决策,该思想也是该算法的第一个特点。第二个特点就是该算法不要求环境是如何变化的信息(Environment Dynamics),也不要求智能体之间的通讯方法(differential communication channel)。
以下是我之前做的PPT里面的一张, MADDPG算法中神经网络数量较多,数量会随着智能体数量的增加而线性增长。

智能体actor网络的梯度公式可以之间跳到伪代码部分。
两种其他改进
推断其他智能体的策略(Inferring Policies of Other Agents)
思路就是将critic网络中的target value(该值是在每个智能体都知道其他智能体的策略的假设下计算得到的)换成一个由每个智能体的approximate policy计算出来的值,这个approximate policy又是最大化智能体的log probability得到的(引入entropy regularizer熵正则化项)

策略集成(Agents with Policy Ensembles)
思想是针对MARL中的环境非平稳的问题,在竞争环境中,智能体的策略可能对他们的竞争者的行为过拟合,因此当竞争者策略变化的时候,智能体的策略就可能无效。所以该方法关注如何提升智能体学到的策略的鲁棒性。
该方法基本内容就是训练K个不同策略的集合,目标函数也随之变化,文章里也给出了该损失函数的梯度计算公式。

(这一部分的代码可以在github的issue里找到,之后解决完baseline的一些实验问题之后学习一下这部分代码)
1.3 论文中的伪代码

伪代码中的要点已经用红框标出,下面总结一下:
- replay buffer存储的信息是所有智能体的状态,动作,奖赏和下一个状态。
- 与DDPG一样,用于更新critic网络参数的target value
y要用到target policy network输出的动作。 - 与DDPG,两类target network都是通过soft replacement方法更新。
1.4 论文中的实验部分(文中+附录)
基础实验部分
(policy network结构:两层MLP,激活函数是ReLU, 智能体之间传递的信息是通过Gumbel-Softmax estimator计算的),超参数的设定(见程序)
具体实验细节:(按场景分类)
i. 第一个是合作通信cooperative communication场景(包括listener和speaker)
在该场景下,传统的DRL方法如DQN, AC, first-order TRPO, DDPG,REINFORCE算法都学不到正确表现。文章中指出这些方法失败的原因是缺少持续的梯度信号(the lack of a consistent gradient signal),作者观测的现象是:当listener的目标只是重构对speaker的observation时,传统方法可以work,另外如果智能体、Landmark的初始位置固定的时候,也可以work. 也就说明之前提出的MARL算法只能在short time horizons情况下工作。
文章的第一个实验结果是:在25000 episodes训练之后,各方法的平均回合奖赏,MADDPG算法最有优势。
第二个实验结果是在25000 episodes之后,对比各方法的policy learning success rate
第三个实验结果是统计不同算法下,智能体到达target landmark的episodes占比(这个指标并不等同于智能体的正确策略,因为即便学到了正确的策略,智能体也不一定完全占据目标,详细可以参考文章中的视频链接),还有到目标的平均距离 (percentage of targets reached)
ii. 三个场景:cooperative navigation, predator-prey, covert communication
a. cooperative navigation
实验结果1:MADDPG好于DDPG,MADDPG的每个智能体距离目标Landmark比DDPG近,智能体之间的碰撞次数几乎是DDPG算法的一半
实验结果2:每个episode的碰撞次数,智能体到目标的平均距离。并将智能体的数量从3个增加到6个(实验用的智能体网络模型是2层全连接,每层128各神经元)
b. predator-prey
实验结果:在两种场景下分别进行实验
第一种场景:prey的速度快30%,统计Predator抓到prey的次数(per episode)------Average number of prey touches by predator per episode
第二种场景:prey的速度快一倍100%, 统计Predator抓到prey的次数(per episode)
(实验用的智能体网络模型是2层全连接,每层128各神经元)
c. covert communication
实验结果1:统计量:agent Bob的成功率,adversary Eve的成功率,两者之间的差值(成功率指的是正确重构出speaker的messages)
最好的一种情况是MADDPG作为agent的算法,DDPG作为adversary的算法。
实验结果2:MADDPG算法的reward oscillation小于使用DDPG算法时的波动。
d. physical deception(智能体数量分别为:N=2, N=4)
实验结果:
统计量:agents的成功率,adversaries的成功率,两者之间的差值,值越大,效果越好,即一种算法好于另一种。
N=2时,达到最好效果的是MADDPG作为agent的算法,DDPG作为adversary的算法。
N=4时,达到最好效果的是MADDPG作为agent的算法,MADDPG作为adversary的算法。
将上述表格里的数据做归一化处理画出直方图,所用统计量是归一化的agent score。
验证对baseline算法的改进:
对比单一策略和策略集成(policy ensembles),3种策略集成在三种场景下进行实验:
- keep away, N=M=1
- physical deception, N=2
- predator-prey N=4,L=1
评估:
场景keep-away和physical deception下,统计adversary占据目标的average frames,对adversary来说,该值越大越好;场景predator-prey下,统计碰撞的次数,对adversary来说,该值越小越好
2. MADDPG代码分析与实验
这一部分是总结对openAi官方代码的分析,并做了一些简单的实验。
2.1 如何在MPE(Multi-Agent Particle Environment)环境中运行该算法?
我是在win10下,tensorflow 1.13(1.14也可以), python 3.6.8环境进行的。最关键的就是把MPE环境的multiagent文件夹拷贝到MADDPG工程目录下,也要保证gym是安装成功的。调参的话直接调整train.py中的parse_args()函数即可。
跑通之后,如果要切换环境的话需要把要把/tmp/policy文件夹删掉重新开始,否则会出现checkpoint不一致的问题。训练结束之后,可以手动创建learning_curves文件夹以存pickle文件,把下面这句话中的None改为任意str类。测试阶段也需要将benchmark_files文件夹添加到experiments下。
parser.add_argument("--exp-name", type=str, default='', help="name of the experiment")
2.2 一些代码分析
代码结构及各部分功能
./experiments/train.py contains code for training MADDPG on the MPE (用于在MPE环境中训练MADDPG算法的代码),里面还定义了网络结构,是全连接层MLP,隐藏层有64个单元。
./maddpg/trainer/maddpg.py: core code for the MADDPG algorithm(MADDPG算法的核心代码)
./maddpg/trainer/replay_buffer.py: replay buffer code for MADDPG(实现经验重放buffer的代码)
./maddpg/common/distributions.py: useful distributions used in maddpg.py(maddpg.py中要用到的分布)
./maddpg/common/tf_util.py: useful tensorflow functions used in maddpg.py(maddpg.py中要用到的tensorflow函数)
下面根据以上的代码结构一个个分析代码。
具体代码解析
maddpg.py
该文件中包含1个类,4个函数,该类中调用这4个函数以完成相应的功能函数。
4个函数:discount_with_dones; make_update_exp; p_train; q_train
1个类:MADDPGAgentTrainer(AgentTrainer)
详细分析:
p_train(make_obs_ph_n, act_space_n, p_index, p_func, q_func, optimizer, grad_norm_clipping=None, local_q_func=False, num_units=64, scope="trainer", reuse=None):
基本过程:
(p_train函数中相当于创建了placeholder并构建静态图,可以通过调用返回的信息来输出对应值)
创建policy network:
设定action的概率分布类型(pdtype),和概率的值
建立observation和actions的placeholder
并且定义policy网络结构(MLP), 并存储network的参数,并赋予这些参数概率分布
判断训练的算法是什么:
如果是DDPG,就将local_q_func标记为True,
并将该智能体的局部observation和actions传入给q网络
定义critic网络(传入Policy网络得到的输出动作,全局信息)
定义用于训练policy network的损失函数(q网络的均值),优化器
定义用于输出损失函数、输出动作具体值的callable function,之后的调用相当于feed_dict操作
创建target policy network:
定义target p网络的结构,并存储其网络中的参数
用软更新方式更新target policy网络参数
得到target p网络的输出,即动作值
返回的信息:act, train, update_target_p, {'p_values': p_values, 'target_act': target_act}
(train的输出是训练网络的loss)
这里再补充一些细节并总结:
-
首先第一步是设置placeholder(只不过这里的代码比较绕,本质上一样)
-
确定actor网络的输入:每个智能体自己的Observations, 但需要注意的是这些observation是否包括其他智能体的一些信息取决于环境中有关observation部分的设计。
-
如果使用的是连续动作空间,那么这里的actor network的输出属于Gaussian数据类型,action实际的输出维度是
2*action_space[agent_idx],将网络的输出分为了Mean和Logstd两个部分,最终action的输出的公式为: μ + exp ( log σ ) ⋅ N ( 0 , 1 ) \mu + \exp(\log\sigma) \cdot \mathcal N(0,1) μ+exp(logσ)⋅N(0,1),这里的的 μ \mu μ是维数为action_space[agent_idx]的向量,该表达式中的 N ( 0 , 1 ) \mathcal N(0,1) N(0,1) 的shape与 μ \mu μ一样。目前这里得到的只是placeholder,而之后的U.funtion用于tensorflow常用的feed_dict操作进行静态图激活。 比如连续动作空间的维度设定为[3,3,3,3],则p网络的参数为(以下为举例):
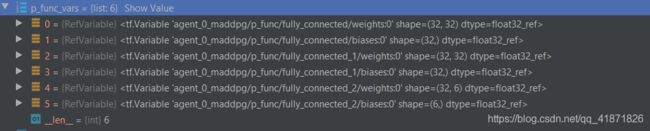
-
action网络的目标函数是:q网络的输出(q网络的输入是所有的actions和Observations)+正则项(以action网络输出为基础),整个目标就是最小化
-q -
用Optimizer(这里使用的是Adam优化器)计算梯度的时候对其范围进行限制:
optimizer.minimize()本身分两步:
第一步是optimizer.compute_gradients(objective, var_list=variable list of one network),返回一个元组:(gradient of variable, variables included),并在这一步使用tf.clip_by_norm()对其进行clip操作; 第二步是optimizer.apply_gradients(gradients),将clip之后的梯度用于更新。
q_train(make_obs_ph_n, act_space_n, q_index, q_func, optimizer, grad_norm_clipping=None, local_q_func=False, scope="trainer", reuse=None, num_units=64):
(q_train函数中相当于创建了placeholder并构建静态图,需要通过调用返回的信息来输出对应值)
创建q network:
设定action的概率分布类型(pdtype),和概率的值
建立observation、actions和target q value的placeholder
判断训练的算法是什么:
如果是DDPG,就将local_q_func标记为True,
并将该智能体的局部observation和actions传入给q网络。
定义critic网络(传入Policy网络得到的输出动作),并获取网络参数(以便后续的软更新)
定义用于q网络更新的损失函数, 优化器
定义用于输出损失函数、输出动作具体值的callable function,用于之后调用喂数据。
创建target network:
定义target q网络的结构,并存储其网络中的参数
用软更新方式更新target q网络参数
得到target q网络的输出,即Q值
返回的信息:train, update_target_q, {'q_values': q_values, 'target_q_values': target_q_values}
(train的输出是训练网络的loss)
两个函数的唯一差异就是损失函数的设定。 代码中理解有困难的Python, tensorflow要点我放到了最后一部分。
a. 类初始化函数由两部分组成:
# 定义相关参数:智能体所用trainer的name, trainer的model,状态空间维度,agent的索引Index等
# 定义policy training network, critic training network (用p_train和q_train)
用到了tf_util.py中的Function函数
# 创建replay buffer
b. action:返回动作
def action(self, obs)
根据观测值进行动作选择(应该是神经网络的输入为状态,输出为动作)
c. experience: 将experience数据存到replay buffer中
def experience(self, obs, act, rew, new_obs, done, terminal)
experience的数据为:s, a, r, s_(现在的状态,动作,奖赏值,下一个状态)
d. preupdate
def preupdate(self)
e. update函数
def update(self, agents, t)
update函数的结构:
step 1. 不进行update的两个条件:
# replay buffer的长度小于最大长度,也就是replay_buffer的数据不够的时候不进行update操作
# 如果没到指定的循环次数,不更新。即每隔一定的循环更新一次
step 2. 获取每个智能体在Replay buffer中的数据:根据从batch_data中采样得来的数据,将这些数据分别以列表形式存储
step 3. 训练q网络:
用到q_train函数计算Q网络的输出值,以计算target q value
用获得的target q value计算q网络的loss
计算policy network的loss
更新target policy和target q network的参数(p_update,q_update)
核心类:MADDPGAgentTrainer(AgentTrainer)
train.py
5个函数:
parse_args()
该函数的目的就是定义训练所需要的参数,基本有以下几类:
- 环境相关参数
- 训练用的超参数定义
- checkpointing(用于存储数据和模型)
- 测试阶段的参数
mlp_model(input, num_outputs, scope, reuse=False, num_units=64, rnn_cell=None):
定义用于各个agent的网络结构,这里使用的是全连接层。
make_env(scenario_name, arglist, benchmark=False):
该函数用于调用MPE环境,详细环境的API可以参考MPE中的代码。
get_trainers(env, num_adversaries, obs_shape_n, arglist):
给环境中的每个智能体定义相关的,先给adversary定义trainer, 再给剩下的智能体定义
train(arglist):
用arglist的参数,定义整个的训练过程,训练的过程如下:
创建环境和每个智能体的训练网络、初始化所有变量
(如有必要,加载之前存储的模型参数)
主循环部分:
获取所有智能体的动作列表(每一个智能体)
环境根据所有智能体的actions, 进行step操作(以获取新的状态、奖赏、done、info)
收集experience,并将其存储到replay buffer中:
先存储每个训练器的experience
用step得到的新的状态信息更新原来的状态信息
累计reward值(一个是episode整个的reward,另一个是agent的reward)
如果一个episode结束,则重置环境,更新step=0,重新分别向episode reward,agent_reward列表中添加一个0
根据是否benchmark, display进行不同操作:
如果是benchmark==True,就对learned policy进行测试,然后存储数据
如果是display==True, 就对环境进行渲染env.render()
训练网络(更新网络参数)
每隔一些steps (save_rate),存储训练好的模型,并格式化输出损失、训练所消耗的时间等
存储最后一次训练的模型产生的数据(智能体、全局的奖赏)
具体代码参考openAI官方代码。
common/tf_util.py
重点看了下_Function类,该类的基本目的就是简化tf的feed_dict过程。
function函数和_Function类:
I. function函数的输入输出:
输入:将要输入数据的placeholders
输出:将要根据placeholders进行计算的表达式, 返回Lambda函数
(需要用到python中的lambda函数)
II. function函数的流程:
判断outputs的形式:是list, dict或者其他形式
如果是list: 返回_Function的对象,输出也是list
如果是dict, 返回_Function对象,输出是dict
其他情况,返回_Function对象的第一个元素
# _Function类:
初始化:
检查constructor中的inputs是否是TfInput的一个子类
(TfInput是PlacholderTfInput, BatchInput, Uint8Input的父类,后两者是PlacholderTfInput的子类)
对类内的变量进行赋值
_feed_input()
更新feed_dict的值,向其添加新的键值对
__call__(*args, *kwargs)函数:(让_Function的对象能被调用)
该函数的目的就是将给_Function()对象的输入,作为feed_dict传给Placeholder,最后输出激活placeholder之后的值。
replay_buffer.py
初始化__init__和长度__len__:
_storage
_maxsize
_next_idx
清除操作:
_storage清空;_next_idx清零
类内的函数method:
i. add
如果索引超过当前存储数据的长度,则添加这些数据
如果索引小于当前存储数据的长度,则替换该位置之前的数据
索引值自加1之后对storage maxsize求余,保证该数值不会超过最大存储长度
ii. _encode_sample
将每个智能体的数据汇总成一个更长的list,这些数据包括:obses_t, actions, rewards, obses_tp1, dones
iii. make_index
从存储器中随机抽取batch_size长度的数据
iv. make_latest_index:
先从当前Index倒叙排序,一直到maxsize,例如:[_next_idx-1, ..., 0, batch_size-1, ....next_idx]
将上述list打乱
v. sample
给定idxes,从storage中抽取这些数据
vi. collect
return sample(-1)
指的是收集这些数据的阶段
2.3 已测试的实验
这部分是我现在初步跑的一些实验,之后还需要继续分析MADDPG的这篇文章的实验部分。
改变训练adversary的算法,第一轮是使用DDPG训练adversary,并在四种场景下测试训练效果,四种场景分别是:physical deception, covert communication, keep-away, predator-prey,这四种场景下均包含了adversary。第二轮是用MADDPG训练adversary,并在以上四种场景下实验,下图是结果: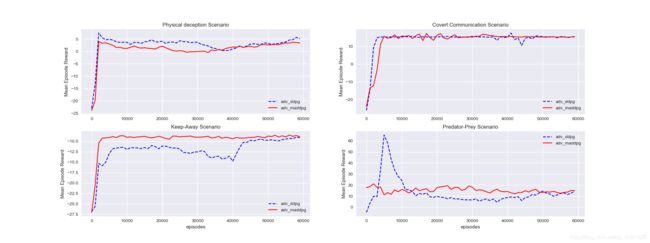
2.4 一些Python与tensorflow相关语法要点的记录
Python相关要点
函数形参实参前的*号
单星号(*)用于导入:agrs,将所有参数以元组(tuple)的形式导入
单星号()也可以用于解压参数列表
双星号(**):kwargs,双星号()将参数以字典的形式导入
lambda函数使用方法(匿名函数anonymous functions)
https://www.cnblogs.com/huangbiquan/p/8030298.html
lambda x,y : x+y
lambda之后的变量为该匿名函数的输入,冒号后面为该函数的输出,整个语句等同于def function,属于function
python中的pickle库:
https://docs.python.org/3/library/pickle.html
介绍:
The pickle module implements binary protocols for serializing and de-serializing a Python object structure.
“Pickling” is the process whereby a Python object hierarchy is converted into a byte stream, and “unpickling” is the
inverse operation, whereby a byte stream (from a binary file or bytes-like object) is converted back into an object hierarchy.
python内置all函数
all() 函数用于判断给定的可迭代参数 iterable 中的所有元素是否都为 TRUE,如果是返回 True,否则返回 False
all([0,1,1]) # False
all([1,1,1]) # True
collections库相关
collections.OrderedDict
会按照输入的键值对顺序来排序,而python本身的字典是不考虑顺序的
Python object中的__call__函数:
https://www.cnblogs.com/xinglejun/p/10129823.html
所有的函数都是可调用对象。一个类实例也可以变成一个可调用对象,只需要实现一个特殊方法__call__,该对象(注意是对象, 不是类)可被当成函数调用
类的实例化对象(即object)可以充当函数使用.
示例程序:
class X(object):
def __init__(self,a,b):
self.a = a
self.b = b
print(self.a, self.b, ' this is initialization of class X')
def __call__(self, *args, **kwargs):
self.a = args
self.b = kwargs
print(self.a, self.b, ' this is calling class X')
xInstance = X(1,2)
xInstance(1,2,3,c=1,d=2)
Python中字典中的update方法——Dict.update()
把字典dict2的键/值对更新到dict里:
dict.update(dict2)
例子程序:
a = {'a':1, 'b':1}
b = {'c':2}
a.update(b) # {'a': 1, 'b': 1, 'c': 2}
Tensorflow相关要点
tf.train.Saver相关: (tf 1.13)
https://github.com/tensorflow/docs/blob/r1.13/site/en/api_docs/python/tf/train/Saver.md
介绍:
The Saver class adds ops to save and restore variables to and from checkpoints. It also provides convenience methods
to run these ops.
Checkpoints are binary files in a proprietary format which map variable names to tensor values.
Constructor:
__init__(
var_list=None, # variables that will be saved and restored, can be passed as a dict or a list
reshape=False, # if true, restore a variable from a save file where the variable had a different shape, but the same number of elements and type
sharded=False, # if true, instructs the saver to shard checkpoints, one per device
max_to_keep=5, # maximum number of recent checkpoint files to keep, as new files are created, older files are deleted
keep_checkpoint_every_n_hours=10000.0, # How often to keep checkpoints.
name=None, # Optional name to use as a prefix when adding operations
restore_sequentially=False, # restore different variables
saver_def=None,
builder=None,
defer_build=False, # If True, defer adding the save and restore ops to the build() call.
# In that case build() should be called before finalizing the graph or using the saver.
allow_empty=False, # If False (default) raise an error if there are no variables in the graph
write_version=tf.train.SaverDef.V2,
pad_step_number=False,
save_relative_paths=False,
filename=None
)
程序中用到的Methods:
save (tf.train.Saver.save)
e.g.:
saver.save(sess, 'my-model', global_step=0) ==> filename: 'my-model-0'
save(
sess, # A Session to use to save the variables.
save_path, # Prefix of filenames created for the checkpoint.
global_step=None, # If provided the global step number is appended to save_path to create the checkpoint filenames
latest_filename=None,
meta_graph_suffix='meta', # Suffix for MetaGraphDef file. Defaults to 'meta'
write_meta_graph=True, # Boolean indicating whether or not to write the meta graph file.
write_state=True, # indicating whether or not to write the CheckpointStateProto
strip_default_attrs=False
)
restore (tf.train.Saver.restore)
介绍:
Restores previously saved variables. The variables to restore do not have to have been initialized, as restoring is
itself a way to initialize variables.
restore(
sess, # A Session to use to restore the parameters. None in eager mode.
save_path # Path where parameters were previously saved.
)
- 存储的文件格式:
.data-00000-of-00001
保存了当前参数名和值
.index
保存了辅助索引信息
.meta
保存了当前图结构.
checkpoint
记录了模型文件的路径信息列表
tf.get_default_session:
返回Innermost的session,
tf.group:
函数原型:
tf.group(
*inputs,
**kwargs
)
Create an op that groups multiple operations. 组合多个运算
When this op finishes, all ops in inputs have finished. This op has no output.