深度学习-自然语言处理-文本生成
实验内容
从一个含有酒店信息的excel文件生成酒店评价文字。
实验方法
seq2seq方法。运用的是lstm+attention
实验过程
1.数据预处理:首先,将所有文本进行分词,在参考例句的头尾加上’
2.搭建模型:模型采用seq2seq框架,编码器采用lstm,解码器采用lstm+attention,结构如下图所示。这里采用点乘形式的attention。并应用scale技巧。
3.训练模型并调参:尝试不同学习率,网络深度等参数,进行训练,保留效果最好的模型。
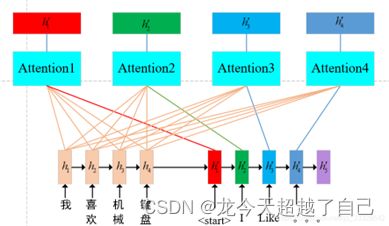
一看就懂的LSTM+Attention,此处用softmax求概率_难受啊!马飞...的博客-CSDN博客_attention-lstm
实验结果与分析
经过多次调参,模型最佳表现平均bleu得分为0.55~0.58 左右,实验发现加了scale 技巧的attention 效果差于没加scale 技巧的attention。猜测是因为维度不是很大,加了scale缩小了显著性。Attention关系图如下所示,虽然效果不明显,但是可以看出attention的权重在对应翻译位更大,比如译文里的Wrestlers 于原文中 Wrestlers 最相关。

得分情况

attention 图解

翻译效果
******************************************************************************************************
附代码
import csv
import tqdm
from torch.utils.data import Dataset
import torch
import torch.nn as nn
from torch.utils.data import DataLoader
from torch.nn.utils.rnn import pad_sequence
import numpy as np
import random
import math
import time
from tqdm import tqdm
import random
class E2EDataset(Dataset):
def __init__(self,path,w2i_dict):
self.path = path
self.w2i = w2i_dict
data = []
with open(path, 'r',encoding='utf-8') as f:
reader = csv.reader(f)
for row in tqdm(reader):
if len(row)>1:
x, y = row
x,y =x.split(),y.split()
index_x = [w2i_dict[x[i]] for i in range(len(x))]
index_y = [w2i_dict[y[i]] for i in range(len(y))]
data.append((index_x, index_y))
else:
x = row[0]
x = x.split()
index_x = [w2i_dict[x[i]] for i in range(len(x))]
data.append(index_x)
# data.append((x.split(' '),y.split(' ')))
# 转化为词向量
self.data = data
def batch_data_process(self,batch_datas):
global device
x_index,y_index=[],[]
x_len,y_len=[],[]
for x,y in batch_datas:
x_index.append(x)
y_index.append(y)
x_len.append(len(x))
y_len.append(len(y))
max_x_len=max(x_len)
max_y_len=max(y_len)
x_index = [i + [self.w2i['']]*(max_x_len-len(i)) for i in x_index]
y_index = [[self.w2i['']] + i + [self.w2i['']] + [self.w2i['']] * (max_y_len - len(i)) for i in y_index]
x_index = torch.tensor(x_index,device=device)
y_index = torch.tensor(y_index,device=device)
return x_index,y_index
def __len__(self):
return len(self.data)
def __getitem__(self, index):
x,y =self.data[index]
return x,y
class Encoder(nn.Module):
def __init__(self, encoder_embedding_num, encoder_hidden_num, en_corpus_len):
super().__init__()
self.embedding = nn.Embedding(en_corpus_len, encoder_embedding_num)
self.lstm = nn.LSTM(encoder_embedding_num, encoder_hidden_num, batch_first=True)
def forward(self, en_index):
en_embedding = self.embedding(en_index)
encoder_output, encoder_hidden = self.lstm(en_embedding)
return encoder_output,encoder_hidden
#
#
class Decoder(nn.Module):
def __init__(self,decoder_embedding_num,decoder_hidden_num,ch_corpus_len):
super().__init__()
self.embedding = nn.Embedding(ch_corpus_len,decoder_embedding_num)
self.lstm = nn.LSTM(decoder_embedding_num,decoder_hidden_num,batch_first=True)
self.softmax= nn.Softmax(dim=1)########
#encoder_output,decoder_input,decoder_hidden
def forward(self,encoder_output,decoder_input,hidden):#decoder_hidden是元组(h_n,c_n)
embedding = self.embedding(decoder_input)#decoder_input 进来的字或者字串
decoder_output,decoder_hidden= self.lstm(embedding,hidden)
(h_n, c_n) = decoder_hidden
# attention = torch.bmm(torch.softmax(torch.bmm(decoder_output,encoder_output.permute(0,2,1)), dim=1),encoder_output )
attention = torch.bmm(torch.softmax(torch.bmm(decoder_output, encoder_output.permute(0, 2, 1)), dim=2),
encoder_output)
#第一个bbm乘下来是
return attention,(h_n, c_n)
# 1.forward()函数以对应的id作为第一个输入,t时刻的输入为
# t-1时刻的输出,解码出预测序列第t个token
# 2.解码过程迭代至预测出这一token,或者达到预设最大长度结束
# 3.如果采用Attention,需要在Decoder计算Attention Score
# '''
#
class Seq2Seq(nn.Module):
def __init__(self,encoder_embedding_num,encoder_hidden_num,en_corpus_len,decoder_embedding_num,decoder_hidden_num,ch_corpus_len):
super().__init__()
self.encoder = Encoder(encoder_embedding_num,encoder_hidden_num,en_corpus_len)
self.decoder = Decoder(decoder_embedding_num,decoder_hidden_num,ch_corpus_len)
self.classifier = nn.Linear(decoder_hidden_num,ch_corpus_len)#这里改进
self.cross_loss = nn.CrossEntropyLoss()
def forward(self,en_index,ch_index):#####这些只有两个维度是否中?
decoder_input = ch_index[:,:-1]#输入不含
label = ch_index[:,1:]#标签不含
encoder_output,encoder_hidden = self.encoder(en_index)#why tuple????????、
decoder_output,_ = self.decoder(encoder_output,decoder_input,encoder_hidden)
pre = self.classifier(decoder_output)
# for int(torch.argmax(pre,dim=-1))
# if random.random()<0.001:
# pre0=torch.argmax(pre[0:1,:],dim=-1)
# # print(torch.argmax(pre[0:1,:], dim=-1))
# for i in range(pre.shape[1]):
# print(i2w_dict[int(pre0[0,i])],end=' ')
# print('\n')
loss = self.cross_loss(pre.reshape(-1,pre.shape[-1]),label.reshape(-1))
return loss
def train(model,iterator,iteration=0):
model.train()
for i, (x_index,y_index) in enumerate(iterator):
loss = model(x_index, y_index)
loss.backward()
opt.step()
opt.zero_grad()
torch.save(model, filename+"loss" + str(round(float(loss), 3)) + ".pkl")
torch.save(model, filename+"latest.pkl")
print("{}----epoch:{} train_loss:{:.3f}".format(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())),iteration, loss))
# for x_index,y_index in train_loader:
# loss = model( x_index,y_index )
# loss.backward()
# opt.step()
# opt.zero_grad()
# print("epoch:{} loss:{:.3f}".format(e, loss))
#
def evaluate(model,iterator,iteration=0):
model.eval()
with torch.no_grad():
for i, (x_index, y_index) in enumerate(iterator):
loss = model(x_index, y_index)
translate(x_index[0:1,:])
print('eval',loss)
print("{}---valid_epoch:{} loss:{:.3f}".format(time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time())),iteration, loss))
def preprocess(path_list=[]):
name_list=['e2e_dataset/clean_train.csv','e2e_dataset/clean_dev.csv','e2e_dataset/clean_test.csv']
path_i=0
stop_word =['[',']']
for path in path_list:
head_line=1
with open(path, 'r', encoding='utf-8') as f:
with open(name_list[path_i], 'w', encoding='utf-8',newline='') as f1:
reader = csv.reader(f)
writer = csv.writer(f1)
for row in reader:
if head_line==1:
head_line=0
continue
if path_i!=2:
x, y = row
x1=x.split()
# x1[0] = 'name NameX'#取消无关项影响
x = ' '.join(x1)
for word in stop_word:
x=x.replace(word,' ',1000)
writer.writerow((x,y))
else:
x = row[0]
x1 = x.split()
# x1[0] = 'name NameX' # 取消无关项影响
x = ' '.join(x1)
for word in stop_word:
x = x.replace(word, ' ', 1000)
writer.writerow((x,))
# print(x)
path_i+=1
return name_list
def word2index(path_list=[],):#只是英文
path_i=0#为了控制测试集的特殊情况
word_set = set()
word_set.add('')#begin of sentence
word_set.add('')
word_set.add('')
for path in path_list:
with open(path, 'r', encoding='utf-8') as f:
reader = csv.reader(f)
for row in reader:
if path_i!=2:
x, y = row
for i in x.split()+y.split():
word_set.add(i)
else:
x = row[0]
for i in x.split():
word_set.add(i)
path_i += 1
word2index_dict ={}
for i in range(len(word_set)):
word2index_dict[word_set.pop()]=i
print('BOS {} EOS {} PAD {}'.format(word2index_dict[''],word2index_dict[''],word2index_dict['']))
return word2index_dict
def translate(sentence):
global w2i_dict,device,i2w_dict
# en_index = torch.tensor([[en_word_2_index[i] for i in sentence]],device=device)
origin_info=[]
for i in sentence[0,:]:
origin_info.append(i2w_dict[int(i.to('cpu'))])
print('原文:{}'.format(' '.join(origin_info)))
result = []
encoder_output,encoder_hidden = model.encoder(sentence)
decoder_input = torch.tensor([[w2i_dict[""]]],device=device)
decoder_hidden = encoder_hidden
while True:
# print('e_e', decoder_output[0, 0, 0], end='')
decoder_output,decoder_hidden = model.decoder(encoder_output,decoder_input,decoder_hidden)
#output,(h_n,h_c)
# print('d_e',decoder_output[0,0,0],end='')
pre = model.classifier(decoder_output)
w_index = int(torch.argmax(pre,dim=-1))
word = i2w_dict[w_index]
if word == "" or len(result) > 100:
break
result.append(word)
decoder_input = torch.tensor([[w_index]],device=device)
print("译文: "," ".join(result))
print("原文: ",sentence)
if __name__ == '__main__':
device = 'cuda:0' if torch.cuda.is_available() else 'cpu'
# 读取数据
filename= 'attention_checkpoint1/'
train_path='e2e_dataset/trainset.csv'
dev_path = 'e2e_dataset/devset.csv'
test_path = 'e2e_dataset/testset.csv'
batch_size = 32
clean_path_list = preprocess([train_path,dev_path,test_path])
w2i_dict=np.load(filename+'w2i.npy',allow_pickle=True).item()
i2w_dict = np.load(filename+'i2w.npy',allow_pickle=True).item()
# w2i_dict = word2index(clean_path_list)
# i2w_dict=dict()
# for k, v in w2i_dict.items():
# i2w_dict[v] = k
print('first word',i2w_dict[0])
# np.save(filename+'w2i.npy',w2i_dict)
# np.save(filename+'i2w.npy', i2w_dict)
train_set = E2EDataset(clean_path_list[0],w2i_dict)
dev_set = E2EDataset(clean_path_list[1],w2i_dict)
test_set = E2EDataset(clean_path_list[2],w2i_dict)
train_loader = DataLoader(train_set,collate_fn=train_set.batch_data_process,batch_size=batch_size,shuffle=True)
dev_loader = DataLoader(dev_set,collate_fn=train_set.batch_data_process,batch_size=batch_size,shuffle=True)
#
# # 初始化batch大小,epoch数,损失函数,优化器等
encoder_embedding_num = 50
encoder_hidden_num = 100
decoder_embedding_num = 107
decoder_hidden_num = 100
lr = 0.0001
epoch = 100
x_corpus_len=len(w2i_dict)
y_corpus_len= x_corpus_len
model =torch.load('attention_checkpoint1/latest.pkl')
# model = Seq2Seq(encoder_embedding_num,encoder_hidden_num,x_corpus_len,decoder_embedding_num,decoder_hidden_num,y_corpus_len)
# model = model.to(device)
opt = torch.optim.Adam(model.parameters(), lr=lr)
for e in range(epoch):
train(model, train_loader, e)
# evaluate(model, dev_loader, e)
if e % 10 == 0:
evaluate(model, dev_loader, e)