【文献阅读】XVQA——一篇关于VQA的解释性研究(K. Alipour等人,ArXiv,2020)
一、背景
文章题目:《A Study on Multimodal and Interactive Explanations for Visual Question Answering》
文章下载链接:https://arxiv.org/pdf/2003.00431.pdf
文章引用格式:Kamran Alipour, Jurgen P. Schulze, Yi Yao, Avi Ziskind and Giedrius Burachas. "A Study on Multimodal and Interactive Explanations for Visual Question Answering". arXiv preprint, arXiv: 2003.00431, 2020.
项目地址:暂时没有
二、文章摘要
Explainability and interpretability of AI models is an essential factor affecting the safety of AI. While various explainable AI (XAI) approaches aim at mitigating the lack of transparency in deep networks, the evidence of the effectiveness of these approaches in improving usability, trust, and understanding of AI systems are still missing. We evaluate multimodal explanations in the setting of a Visual Question Answering (VQA) task, by asking users to predict the response accuracy of a VQA agent with and without explanations. We use between-subjects and within-subjects experiments to probe explanation effectiveness in terms of improving user prediction accuracy, confidence, and reliance, among other factors. The results indicate that the explanations help improve human prediction accuracy, especially in trials when the VQA system’s answer is inaccurate. Furthermore, we introduce active attention, a novel method for evaluating causal attentional effects through intervention by editing attention maps. User explanation ratings are strongly correlated with human prediction accuracy and suggest the efficacy of these explanations in human-machine AI collaboration tasks.
AI模型的可解释性一直是影响AI安全性的重要因素。虽然大部分可解释的AI方法都旨在减少深度网络中透明性的缺乏,但这些方法在提高可用性,信任度和理解AI系统中的有效证据仍然是没有的。在VQA任务的设定中,来我们通过要求用户预测有解释和没有解释的VQA的回答准确性来评估多模态的解释性。我们使用受试者之间和受试者内部的实验来探索解释的有效性,以提高用户预测的准确性,置信度和可信度,以及其他因素。结果表明,解释能够提高人们的预测结果,特别在实验中的VQA答案不准确的时候。此外,我们还引入一种活动注意力,即一种通过编辑注意图来干预评价因果注意效果的新方法。用户解释评分与人类预测准确度密切相关,并表明这些解释在人机AI协作任务中的有效性。
三、文章介绍
为了有效的使用AI系统,用户需要更好的理解AI系统的安全性。然而,现有的深度学习模型是不透明且难以解释的,它总是会出现一些非预期的错误模式,这使得其难以被信任。之前做的AI模型可解释性研究主要是输出中间特征层的重要性,或提供文本证据,但是这些研究都不能够帮助用户更好理解模型的推断过程,也不能帮助用户建立对AI系统的信任。之前研究的量化评估则采用收集用户评分,或核查是否与人的注意力对齐,但是这些都没有对可解释性类型的研究提供本质性的帮助。
为此,作者提出一种新的方法,提供模型操作的中间阶段的透明度,比如使用注意力掩膜(attentional masks),场景中所注意到的目标(detected/attended objects in the scene)。同时,作者也对生成答案提供了一段解释。此外,作者还提出了一种新的注意力机制,活动注意力(active attention)。
1. 相关工作
视觉问答(Visual Question Answering):视觉问答于2015年提出,现在主流的思路就是结合注意力机制来做。
可解释的AI(Explainable AI):自动推理和解释在AI领域中可以追溯到药学,教育和机器人的应用。对于基于视觉的AI应用,大部分工作都是使用的注意力来定位关键特征区域,还有其他的使用不同的解释方法,比如layered attentions,bounding boxes和textual justifications。在本研究中,作者提出了multi-modal explanation system,用以判断模型在视觉,文本和语义格式的行为。与其他研究不同的是,其他可解释性的工作都是基于AI模型来做的,而本文则是结合了AI生成的解释和人类标注的解释以更好的解释机理。
人文研究(Human studies):之前的定量研究都是通过用户来评判的,或者是模型的精度是否有所提高。然而现有的方法并没有让受试者进行交互来生成正确的解释,而在本研究中,我们设计了用户可以交互的环境,来评估multi-modal explanation system是否可以帮助预测VQA模型的正确性。
2. VQA模型
VQA模型的结构如下所示:
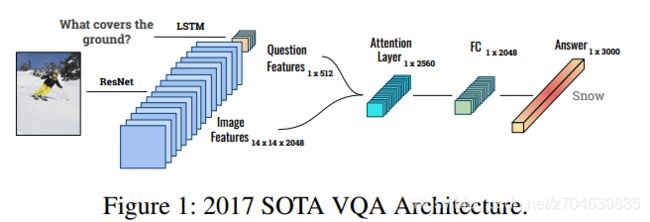
这里作者的VQA模型是2017 SOTA VQA model,提取图像特征用的是ResNet,提取文本特征用的是LSTM,候选答案设置为3000,注意力机制即使用文本去查询图像中的重要区域。此外,作者使用了Mask-RCNN来生成视觉解释。输入图像大小为224×224×3,问题最长为15个单词,首先使用GloVe对文本编码,然后输入LSTM生成512维的文本特征向量,然后将视觉注意力和文本特征向量进行连接,最后输入模型来预测答案。
3. 可解释方法
本文提出的XVQA目的在于对VQA的行为进行解释,方法则通过结合VQA生成的注意力特征和输入的有意义的文本标注。这些标注包括labels, descriptions, and bounding boxes以及它们之间的关联。XVQA不仅能够从内部的层进行可视化,也能够将该可视化信息与标注结合,来解释模型的内部工作。
(1)空间注意力(Spatial attention)
空间注意力使用的是question-guided注意力,来生成图像的注意力,模型结构如下:
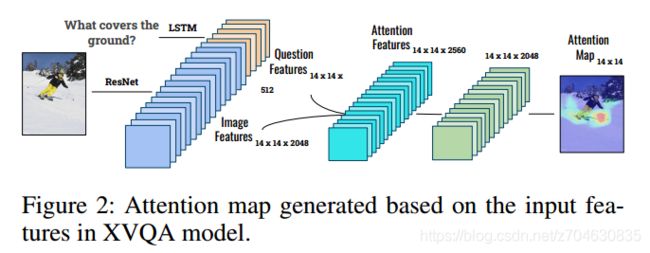
生成的注意力图如下所示:

(2)活动注意力(Active attention)
XVQA模型为用户在反馈环路中提供了一种解释方法,用户可以使用特征来改变注意力图,以此来操控注意力和答案的生成。在这个反馈环路中,用户首先看到注意力和生成的答案,然后他们改变注意力并产生不同的答案。
活动注意力有两步task需要完成。第一步与空间注意力相同,VQA模型根据空间注意力来生成预测答案,然后受试者来观察预测结果是否准确;第二步,受试者会再画一个新的注意力图,然后模型再根据这个新的注意力图来产生新的答案。
该过程的示意图如下所示:
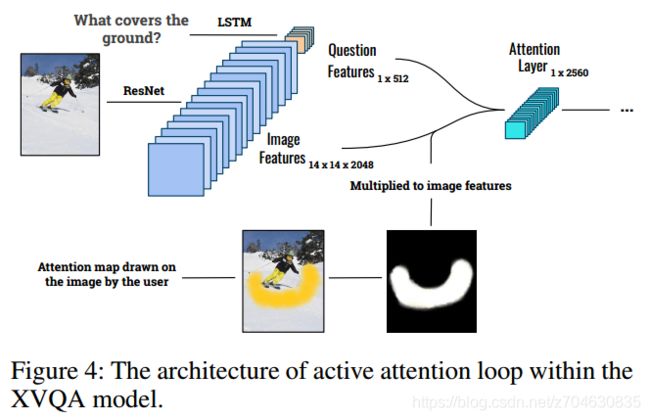
这一步的目的就是使得受试者能够参与到模型的交互当中,一旦模型对问题的回答不正确,那么受试者就可以改变注意力,使得模型回答出正确的答案。
(3)Bounding boxes
bounding boxes含有关于场景的重要信息,本研究中选取top 5个与答案最有关联的boxes。示意图如下所示:

(4)场景图(Scene graph)
为了表示目标之间的关系,这里引入了场景图。目标之间的属性或交互可用下面的法则描述:subject-predicate-object。所有目标标签的表示,都可以在VG数据集上训练得到。对于输入的问题,可以过滤掉其中的目标,且用户可以与之进行交互,如下图所示:
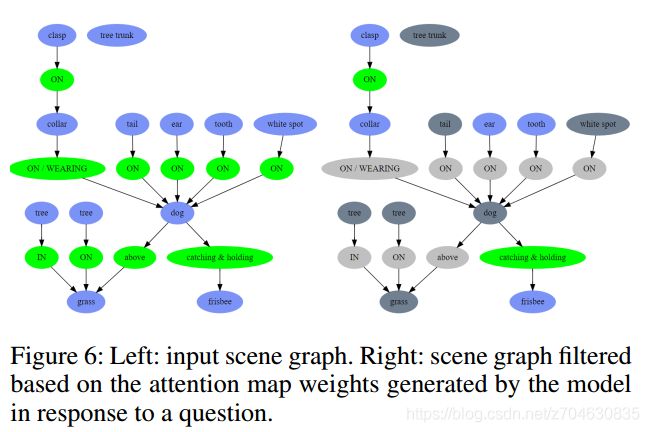
(5)目标注意力(Object attention)
灵感来源于之前的工作,作者使用了MASK-RCNN作为图像的编码器以产生目标级的解释。该编码器可以用在XVQA模型中,而VQA模型仍然使用ResNet产生答案。与空间注意力不同,目标注意力能够分割出确定的整体,以生成更多有意义的解释,效果如下图所示:

(6)文本解释(Textual explanation)
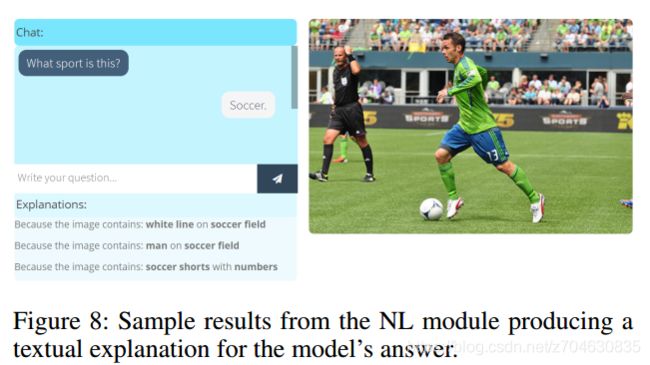
除了视觉解释,我们在XVQA中也整合了自然语言解释,灵感依旧来源于之前的工作,它使用了图像中的实体的标注(来源于场景图)。对于给定的问题-图像对,文本解释则是使用了图像注意力来判断与图像最相关的部分,然后再找出相应的bounding boxes。
模型最终基于图像和语言表示来找出和答案最相关的实体。而对最相关实体的区域描述,则构成了文本解释,该项技术如下图所示:
4. 实验设计
(1)用户任务(User task)
在每一个实验阶段,用户先给出他对于模型预测答案正确与否的判断,然后再给出该答案再Likert scale下的置信度。之后,这些受试者会看到ground truth,top-5的答案及他们的概率排序。另外为了减少疲劳效应,每个受试者的测试时间都被限制在了一个小时。
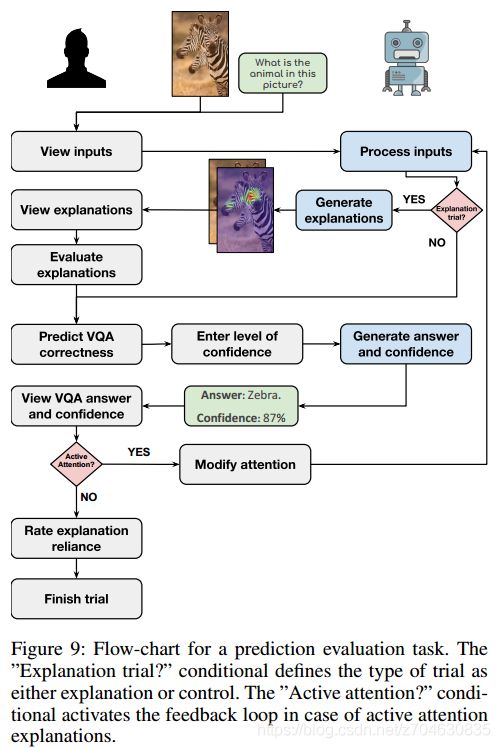
(2)实验(Trials)
环境中有两种类型的实验,即无解释的实验和有解释的实验。在无解释实验中,受试者基于输入的图像和问题来估算系统的准确度。在有解释的实验中,受试者首先会看到模型输入和解释,在评估模型预测答案的正确性之前,受试者会评估每个解释对于模型准确预测答案的帮助程度。在有解释实验的结束阶段,受试者还需要给出解释的可信度,该实验的具体流程如下图所示:
(3)研究组群(Study groups)
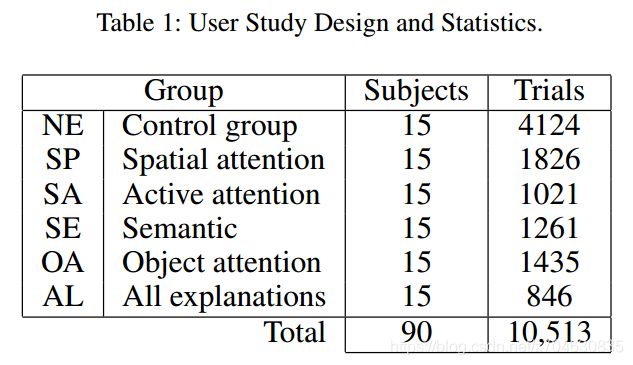
研究组群被分为了6组,具体如下图所示:

控制组(NE)是不看解释的;SA组是有互动过程,该组首先是看空间注意力解释,然后在反馈环路中修改注意力;每个有解释的组都专注于一种解释模式,除了SE组,它是结合了bounding box,场景图和文本解释。
该研究有90个参与者,进行了超过10000次实验,总计涉及3969组image-question pairs,这里的二值性问题是被排除的,具体研究参与的情况如下表所示:
5. 实验结果
(1)对user-machine任务性能的影响
首先评估的是,用户预测机器正确性的准确度,以及这是否受到解释的影响。结果表明,在有解释的群组中,准确度明显要比无解释的群组表现更好,实验统计结果如下图所示:
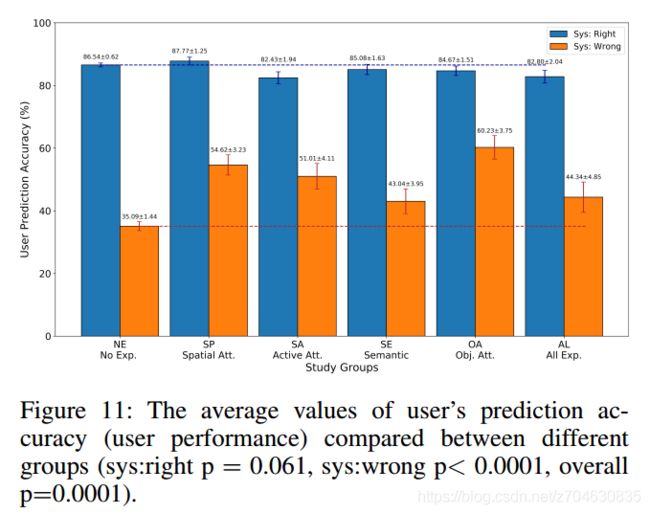
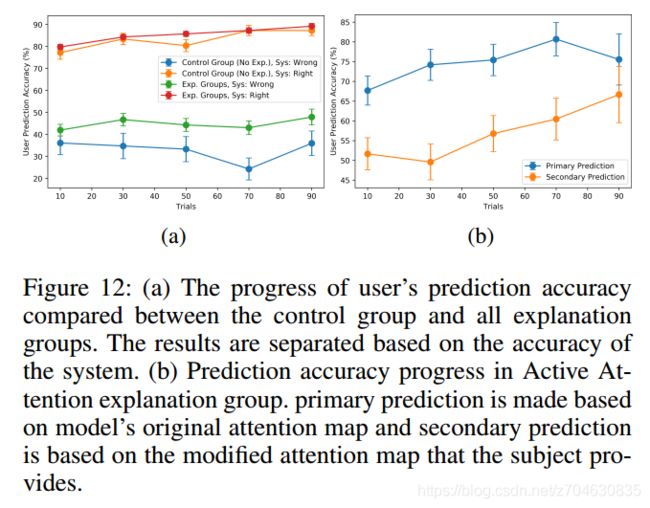
预测准确度的提高,也是衡量研究对象在理解和预测系统行为方面的进步的又一指标。结果如下表所示,即受试者在有解释的群组中表现出了更为稳定的准确度提高:
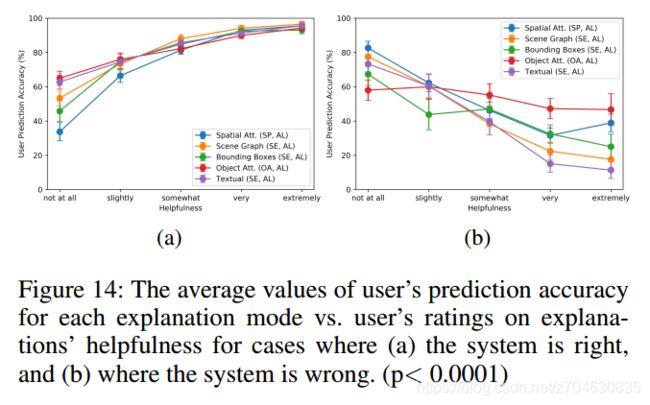
(2)用户解释的帮助度评估(User explanation helpfulness ratings)
实验表明,用户发觉解释是有帮助的时候,他们会在预测任务中做的更好,这也表明了解释对于用户决策是非常重要的,结果如下表所示:
(3)活动注意力解释(Active Attention explanation)
结果可以看Fig 12b,结论就是说活动注意力也能帮助提高模型的预测(they also substantially improve in predicting system when working with their modified attention (secondary prediction).)
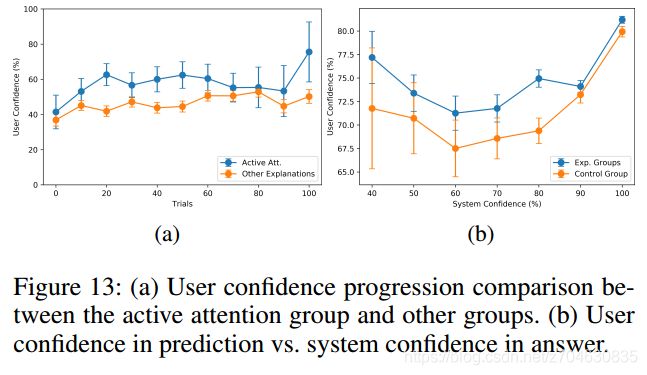
(4)活动注意力对用户置信度的影响(Impact of Active Attention on user confidence)
实验结果表明,与其他有解释的群组相比,用户在活动注意力群组中,对模型的首次预测往往有着更高的平均置信度,结果如下图所示:
(5)对于可信度的影响(Impact on trust and reliance)
比较用户可信度和模型效果,结果表明,用户可信度和模型预测错误情况下的用户准确度高度相关,如下图所示:
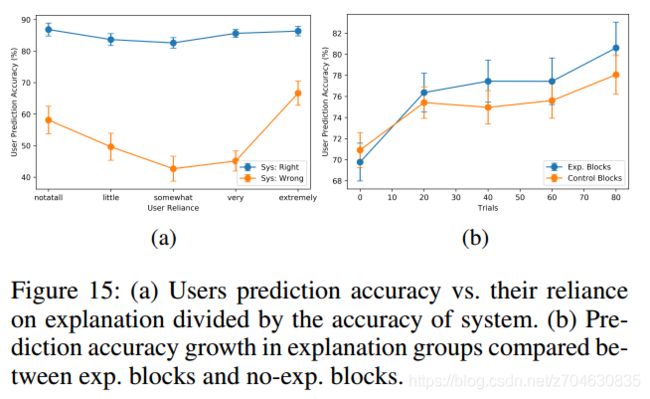
(6)良好解释的影响(Impact of explanation goodness)
如Fig 15b所示,结果表明,有着良好解释的情况下,用户可以帮助建立更为智能的模型,并且能够更好的理解模型生成的答案。