医疗影像分割
1.U-Net
看了好几个帖子这个讲的比较贴!!
介绍内容:医学影像常用图像格式:
(1)DICOM
(2)MHD/RAW
(3)NRRD
1.1 U-Net的架构
U-Net的U形结构如下图所示。网络是一个经典的全卷积网络(即网络中没有全连接操作)。属于FCN的改进型。从某种意义上来说U-Net整体的流程是编码和解码(encoder-decoder)的过程,信息的压缩就是编码,信息的提取就是解码,比如图像,文本,视频的压缩与解压。
网络的输入是一张 572x572 的边缘经过镜像操作的图片(input image tile)
网络路径分为两个部分:
(1) 压缩路径(contracting path)
网络的左侧(红色虚线)是由卷积和Max Pooling构成的一系列降采样操作,论文中将这一部分叫做压缩路径(contracting path)。
压缩路径由4个block组成,每个block使用了3个有效卷积和1个Max Pooling降采样,每次降采样之后Feature Map的个数乘2,因此有了图中所示的Feature Map尺寸变化。最终得到了尺寸为 16x16 的Feature Map。
(2) 扩展路径(expansive path)
扩展路径旨在提高输出的分辨率。对于定位,采样输出与整个模型的高分辨率特征相结合。然后,序列卷积层旨在基于该信息产生更精确的输出。
网络的右侧部分(绿色虚线)在论文中叫做扩展路径(expansive path)。同样由4个block组成,每个block开始之前通过反卷积将Feature Map的尺寸乘2,同时将其个数减半(最后一层略有不同),然后和左侧对称的压缩路径的Feature Map合并,由于左侧压缩路径和右侧扩展路径的Feature Map的尺寸不一样,U-Net是通过将压缩路径的Feature Map裁剪到和扩展路径相同尺寸的Feature Map进行归一化的(即下图中左侧虚线部分)。扩展路径的卷积操作依旧使用的是有效卷积操作,最终得到的Feature Map的尺寸是 388x388 。由于该任务是一个二分类任务,所以网络有两个输出Feature Map。

1.2 预处理(增加对比度、去噪)
在U-Net当中用的图像预处理的去噪方式是基于曲率驱动的图像去噪
在图像去噪领域,由于高斯低通滤波对图像所有高频成分不加区别地减弱,从而在去噪的同时也使边缘模糊化。
自然图像中的物体所形成的等照度线 (包括边缘)应该是足够光顺的曲线 ,即这些等照度线的曲率的绝对值应该足够小.当图像受到噪音污染后 ,图像的局部灰度值发生随机起伏导致等照度线的不规则振荡,形成局部曲率很大的等照度线,因此顺应曲率变化对图像所有高频成分加以区别地减弱,从而达到图像去噪的效果会很好。根据这一原理,可以进行图像去噪。
1.2 卷积块模型

1.3 目标函数-Dice系数
Dice距离用于度量两个集合的相似性,因为可以把字符串理解为一种集合,因此Dice距离可用于计算两个字符串的相似度和图形掩码区域的差异。
Dice系数定义如下:
 Dice 系数的取值范围为0到1。在形式上,Dice 系数和Jaccard指数(A交B除以A并B)没多大区别,可以相互之间进行转换。
Dice 系数的取值范围为0到1。在形式上,Dice 系数和Jaccard指数(A交B除以A并B)没多大区别,可以相互之间进行转换。
有关损失函数:同样的在U-NET里面用到损失函数和FCN类似都是带边界权值的损失函数,不过结合了 Dice 损失计算,即标准二进制交叉熵和 Dice 损失计算的函数:

1.4 图像增强的方法
原始数据集仅有几十例,远不足以训练7层U-Net这样具有5000W+个参数的深层次网络。在这里用到了keras自带的图像数据增强技术,对原始数据做平移、旋转、扭曲等操作(包括对应的标注数据) 。

其中对于平移和旋转主要用到的是仿射变换。
对于扭曲操作,比较重要的一个方式就是弹性形变(介绍贴):
弹性形变:
在原有点阵上,叠加正负向随机距离形成“插值位置”矩阵,然后计算每个插值位置上的灰度,形成新的点阵[Simard,2003],以实现图像内部的扭曲变形。具体理论步骤可以看介绍贴。

1.5 U-net问题遗留
(1)组织器官的顶层截面和底层截面与中部截面差异过大而不易识别;(2)不同扫描影像之间有较大的外观变异而不易识别;
(3)磁场不均匀性引起的伪影和畸变,导致不易识别。
2. 3D U-Net
为什么需要3D U-net?
生物医学影像(biomedical images)很多时候都是块状的,也就是说是由很多个切片(slice)构成一整张图的存在。如果是用2D的图像处理模型(U- Net)去处理3D本身不是不可以,但是会存在一个问题,就是不得不将生物医学影像的图片一个slice一个slice成组的(包含训练数据和标注好的数据)的送进去设计的模型进行训练,而以逐片方式对大量3维影像进行注释是繁琐的而低效的,因为相邻的切片显示几乎相同的信息。而且在这种情况下会存在一个效率问题,因而很多时候处理块状图的时候会很复杂,并且数据预处理的方式也相对比较繁琐(tedious)。
所以3D -Net模型就是为了解决效率的问题,并且对于块状图的切割只要求数据中部分切片被标注即可。
3D U-net的两种方法:
具体有两种方法:
(1)一个是半自动设置,在一个稀疏标注的数据集上训练并在此数据集上预测其他未标注的地方;
(2)在多个稀疏标注的数据集上训练,然后泛化到新的数据。
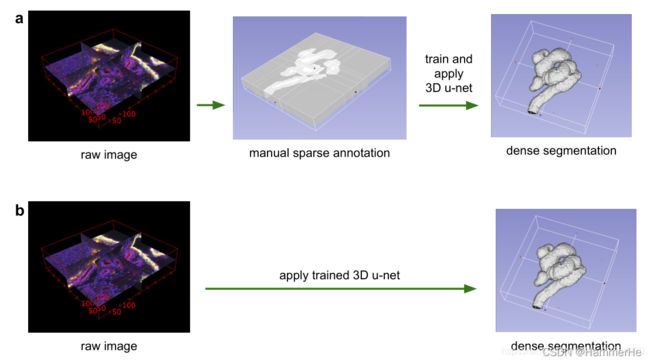 上图很好地表达了论文中的两种方法:
上图很好地表达了论文中的两种方法:
(a)利用少部分切片做完整的密集预测(立体分割);
(b)在标注的数据集上训练模型,再应用到新的无标注数据上直接做密集预测。
2.1 3D U-Net网络结构
3D Unet网络的结构和2D Unet网络十分相似,只不过是把所有的2D操作全部替换成了3D操作。即3D U-NET网络以3D数据作为输入,并用相应的操作来处理数据,包括3D卷积、3D最大池和3D向上卷积层。
假设输入数据的大小为 a1 × a2 × a3,通道数为 c,过滤器大小为f,即过滤器维度为 f × f × f × c,过滤器数量为 n。则三维卷积最终的输出为 ( a1 - f + 1 ) × ( a2 - f + 1 ) × ( a3 - f + 1 ) × n 。
 除此以外的区别在于通道数翻倍的时机和反卷积操作。在2D Unet中,通道数翻倍的时机在下采样后的第一次卷积时;而在3D Unet中,通道数翻倍发生在下采样或上采样前的卷积中。对于反卷积操作,区别在于通道数是否减半,2D Unet中通道数减半,而3D Unet中通道数不变。
除此以外的区别在于通道数翻倍的时机和反卷积操作。在2D Unet中,通道数翻倍的时机在下采样后的第一次卷积时;而在3D Unet中,通道数翻倍发生在下采样或上采样前的卷积中。对于反卷积操作,区别在于通道数是否减半,2D Unet中通道数减半,而3D Unet中通道数不变。
此外,3D Unet还使用batch normalization来加快收敛和避免网络结构的瓶颈。
3D U-net的具体结构即细节:
与二维的U-NET一样,它具有压缩路径(分析路径)和扩展路径(合成路径),该架构总共有19069955个参数
 下面对细节进行介绍:
下面对细节进行介绍:
(1)在压缩路径中,每一层包含两个3×3×3个卷积,每一个都跟随一个(Relu),然后在每个维度上有2×2×2最大池合并两个步长。
 (2)在扩展路径中,每个层由2×2×2的上卷积组成,每个维度上步长均为2,接着是两个3×3×3个卷积,然后是Relu。
(2)在扩展路径中,每个层由2×2×2的上卷积组成,每个维度上步长均为2,接着是两个3×3×3个卷积,然后是Relu。
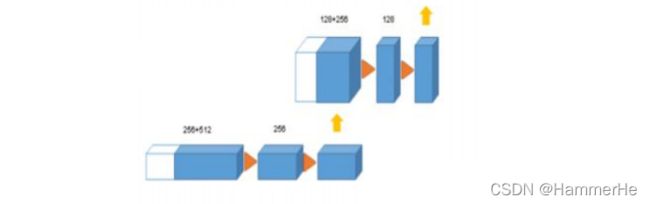 (3)在压缩路径中从相等分辨率层的shortcut连接提供了扩展路径的基本高分辨率特征。
(3)在压缩路径中从相等分辨率层的shortcut连接提供了扩展路径的基本高分辨率特征。
 (4)在最后一层中,1×1×1卷积减少了输出通道的数量,标签的数量是3。
(4)在最后一层中,1×1×1卷积减少了输出通道的数量,标签的数量是3。

可以看到整体结构和细节与U-Net基本类似,这里主要强调一下几点:
(1)与U-Net输入相比,这里输入是立体图像(132×132×116),并且是3个channel。
(2)ReLU之前加了BN层,来加快收敛和避免网络结构的瓶颈。
(3)通过在最大池化之前加倍doubling通道数量channels来避免bottlenecks。
3. V-Net
Vnet是也针对3D图像提出来的模型。V-Net 就是对U-net的一个变形。此时的数据集可以直接用3D数据集。最后输出的也是单通道的3D数据。它可以很好地处理前景和背景体素数量之间存在严重不平衡的情况
网络结构细节和创新点:
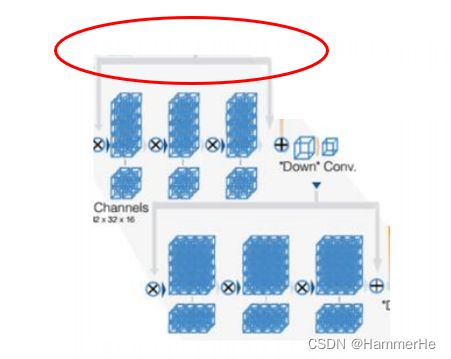
1.引入残差
这里需要特别说明的,也是Vnet和Unet最大的不同,就是在每个stage中,Vnet采用了ResNet的短路连接方式(灰色路线),。相当于在Unet中引入ResBlock。这是Vnet最大的改进之处。类似于使用了跃层连接。
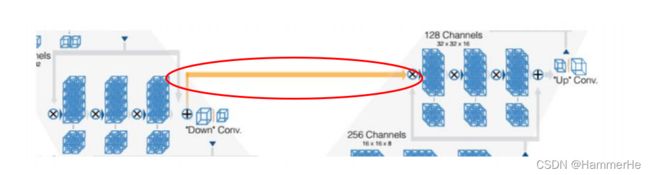
而在水平方向的残差链接还是借用了Unet从压缩路径叠加feature map的方法,从而补充损失信息的方法(黄色线路)。即把缩小端的底层特征送入放大端的相应位置帮助重建高质量图像,并且加速模型收敛。
2.基于Dice 系数的新型目标函数
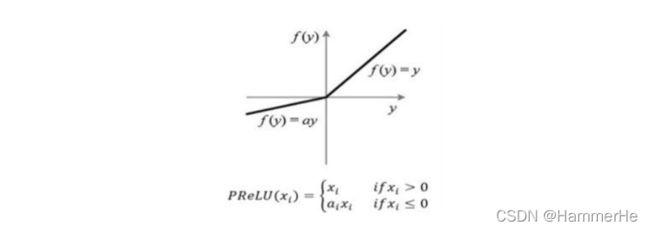
同样是基于Dice系数,但是不用单纯的ReLU了,用的目标函数是PReLU,是指增加了参数修正的 ReLU,其中参数α需要训练学习。
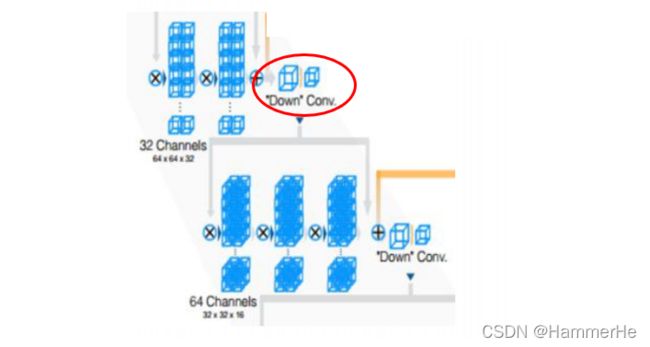
3.卷积层代替上采样和下采样的池化层
每个stage的末尾使用卷积核为2x2x2,stride为2的卷积,特征大小缩小一半。即使用适当步幅(大于1)的3D卷积来减小数据的大小。
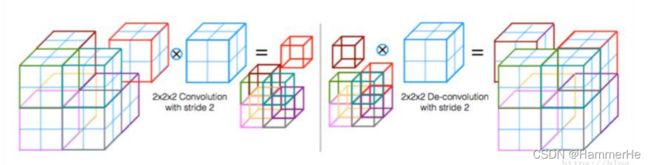
 这个过程更为直观的显示如下,前半段为卷积代替池化缩小尺寸:
这个过程更为直观的显示如下,前半段为卷积代替池化缩小尺寸:
4.末端处理
网络末尾加一个111的卷积,处理成与输入一样大小的数据,然后接一个softmax最,在softmax之后,输出由背景和前景的概率图组成。
具有较高概率(>0.5)的体素属于前景,而不是背景,被认为是组织器官的一部分。

5.改进数据扩充方法
(1)利用 2x2x2的网格控制点和B-spline得到密集形变场对图像进行随机形变。
(2)直方图匹配
4.DenseNet(为了引出FC-DenseNet)
一个关于DenseNet特点和细节比较完整的解读贴
首先要确认DenseNet是一种全新的连接模式,和ResNet以及GoogleNet的用途差不多。
前些年卷积神经网络提高效果的方向:
(1)要么深,加深网络层数,比如ResNet,解决了网络深时候的梯度消失问题
(2)要么宽,加宽网络结构,比如GoogleNet的Inception
DenseNet脱离了加深网络层数(ResNet)和加宽网络结构(Inception)来提升网络性能的定式思维
从特征feature的角度考虑,通过特征重用和旁路(Bypass)设置,既大幅度减少了网络的参数量,又在一定程度上缓解了gradient vanishing问题的产生.结合信息流和特征复用的假设
4.1 DenseNet的几大优点:
(1)减轻了vanishing-gradient(梯度消失)
(2)加强了feature的传递性,更有效地利用了feature
(3)一定程度上减少了参数数量
(4)强调参数有效性,参数使用效率高
(5)隐式深层监督,short paths;
(6)抗过拟合,尤其是训练数据匮乏时
4.2 DenseNet的网络结构
实际上DenseNet的核心就是在保证网络中层与层之间最大程度的信息传输的前提下,直接将所有层连接起来!
先放一个dense block的结构图。
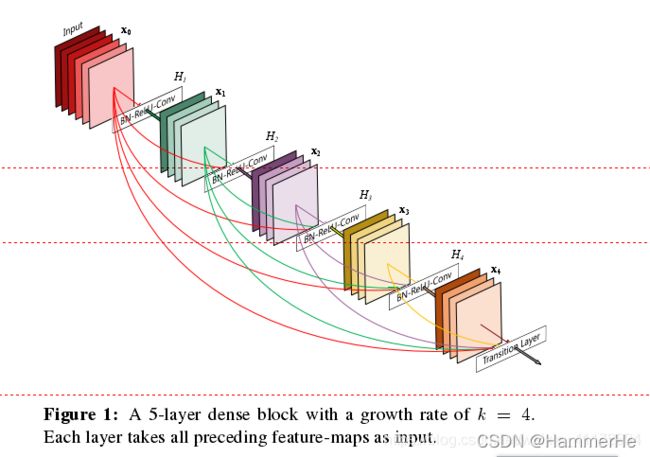
在传统的卷积神经网络中,如果你有L层,那么就会有L个连接,但是在DenseNet中,会有L(L+1)/2个连接。简单讲,就是每一层的输入来自前面所有层的输出。如下图:x0是input,H1的输入是x0(input),H2的输入是x0和x1(x1是H1的输出),以此类推:
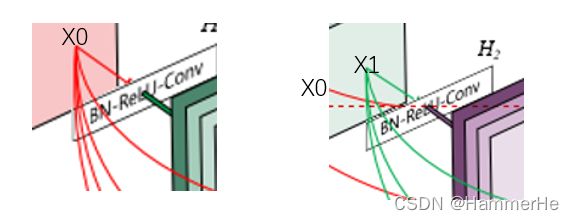
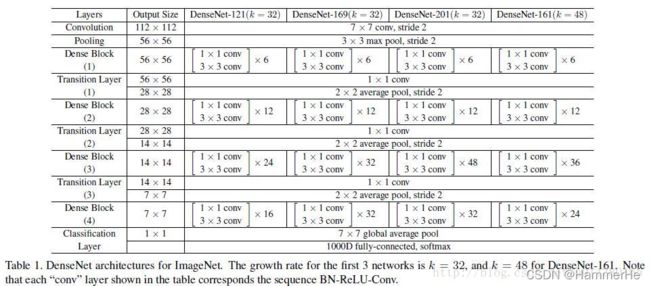
具体网络结构图:
这个Table1就是整个网络的结构图。这个表中的k=32,k=48中的k是growth rate,表示每个dense block中每层输出的feature map个数。
为了避免网络变得很宽,作者都是采用较小的k,比如32这样,作者的实验也表明小的k可以有更好的效果。
根据dense block的设计,后面几层可以得到前面所有层的输入,因此concat后的输入channel还是比较大的。
(1)bottleneck layer:在每个dense block的33卷积前面都包含了一个11的卷积操作,这就是所谓的bottleneck layer
目的是减少输入的feature map数量,既能降维减少计算量,又能融合各个通道的特征。
(2)Translation layer:为了进一步压缩参数,在每两个dense block之间又增加了11的卷积操作。这就是增加了这Translation layer,该层的11卷积的输出channel默认是输入channel到一半。
对于DenseNet-C这个网络就是加了Translation layer
对于DenseNet-BC这个网络,表示既有bottleneck layer,又有Translation layer。
5.FC-DenseNet
在该网络和U-Net其实本质上没太大区别,就是压缩路径和扩张路径的结合,只不过在FC-DenseNet中使用了Dense Block和Transition Up来代替了全卷积网络中的上采样操作,其中Transition Up使用转置卷积上采样特征图,然后与跳层的特征Concatenation一起成为新的Dense Block的输入。使用这种跳层解决Dense Block中特征损失的问题。
5.1 FC-DenseNet网络结构
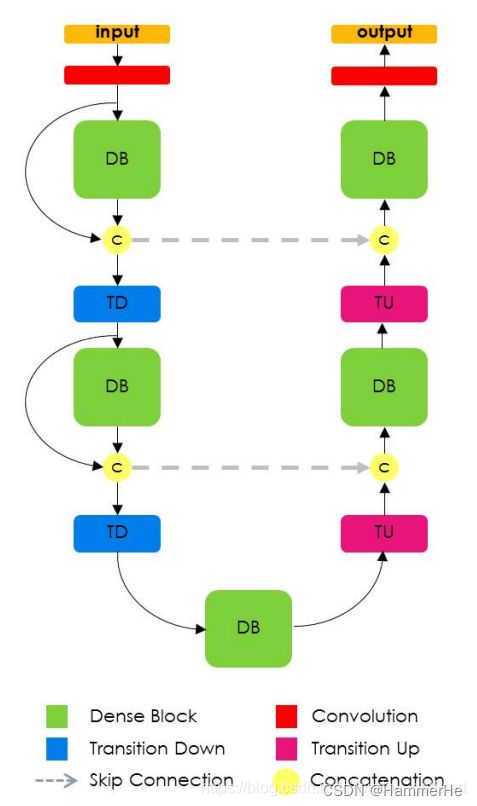
如上图所示:
在FC-DenseNet右侧使用Dense block和transition up替换FC上采样的卷积操作。Transition up 使用转置卷积上采样特征图,与跳层传来的特征串联,生成新的dense block的输入。
但这样会带来特征图数目的线性增长,为了解决这个问题,dense block的输入不与它的输出串联。同时引入跳层的结构来解决之前dense block特征损失的问题
那么什么叫dense block的输入不与它的输出串联?下面对dense block 模块展开介绍:
(1)Dense Block模块
dense block 结构如下图,令第一层输入x0有m个特征图,第一层输出x1有k个特征图,这k个特征图与m个特征图串联,作为第二层的输入,如此重复n次;
第N层的layer层输出后与前面的layer输出合并,共有N×k个特征图。而且输入m不与输出串联。
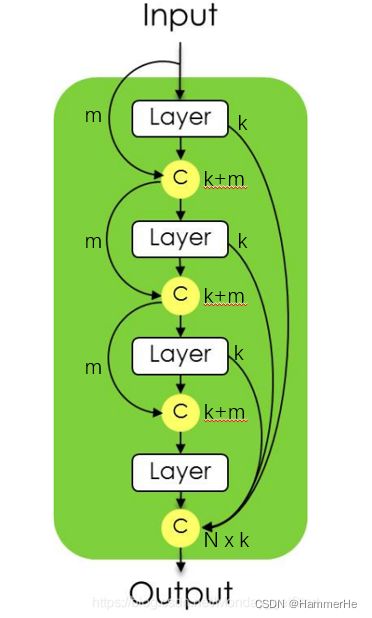
(2)具体网络结构
