俩个问题
1.怎么检测过拟合
2.怎么减少过拟合
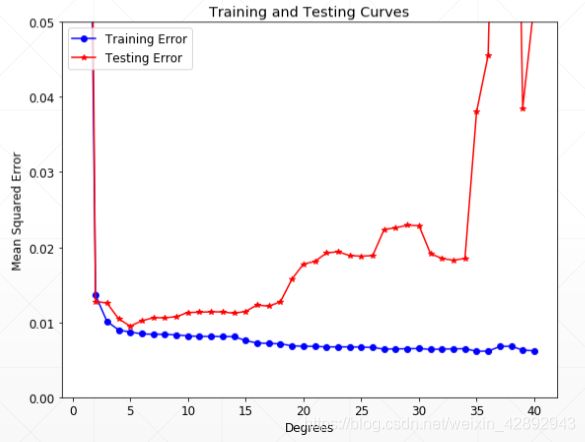
如何检测overfitting
train -val-test
import torch
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torchvision import datasets,transforms
batch_size = 200
learning_rate = 0.01
epochs = 10
####train = True 是用来分开train与test的
train_db = datasets.MNIST('../data', train=True, download=True,
transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
train_loader = torch.utils.data.DataLoader(
train_db,
batch_size=batch_size,shuffle = True
)
test_db = datasets.MNIST('../data', train=False, transform=transforms.Compose([
transforms.ToTensor(),
transforms.Normalize((0.1307,), (0.3081,))
]))
test_loader = torch.utils.data.DataLoader(
test_db,
batch_size=batch_size, shuffle=True
)
print('train:', len(train_db), 'test:', len(test_db))
train_db, val_db = torch.utils.data.random_split(train_db, [50000, 10000])
print('db1:', len(train_db), 'db2:', len(val_db))
train_loader = torch.utils.data.DataLoader(
train_db,
batch_size=batch_size, shuffle=True)
val_loader = torch.utils.data.DataLoader(
val_db,
batch_size=batch_size, shuffle=True)
class MLP(nn.Module):
def __init__(self):
super(MLP, self).__init__()
self.model = nn.Sequential(
nn.Linear(784, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 200),
nn.LeakyReLU(inplace=True),
nn.Linear(200, 10),
nn.LeakyReLU(inplace=True),
)
def forward(self, x):
x = self.model(x)
return x
device = torch.device('cuda:0')
net = MLP().to(device)
optimizer = optim.SGD(net.parameters(),lr = learning_rate)
criteon = nn.CrossEntropyLoss().to(device)
for epoch in range(epochs):
for batch_idx, (data, target) in enumerate(train_loader):
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
loss = criteon(logits, target)
optimizer.zero_grad()
loss.backward()
# print(w1.grad.norm(), w2.grad.norm())
optimizer.step()
if batch_idx % 100 == 0:
print('Train Epoch: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}'.format(
epoch, batch_idx * len(data), len(train_loader.dataset),
100. * batch_idx / len(train_loader), loss.item()))
test_loss = 0
correct = 0
for data, target in val_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(val_loader.dataset)
print('\nVAL set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(val_loader.dataset),
100. * correct / len(val_loader.dataset)))
###这里选保存为过拟合处的模型参数,设置,然后对惊醒test
test_loss = 0
correct = 0
for data, target in test_loader:
data = data.view(-1, 28 * 28)
data, target = data.to(device), target.cuda()
logits = net(data)
test_loss += criteon(logits, target).item()
pred = logits.data.max(1)[1]
correct += pred.eq(target.data).sum()
test_loss /= len(test_loader.dataset)
print('\nTest set: Average loss: {:.4f}, Accuracy: {}/{} ({:.0f}%)\n'.format(
test_loss, correct, len(test_loader.dataset),
100. * correct / len(test_loader.dataset)))