CVPR 2022 | 网络中批处理归一化估计偏移的深入研究
前言 批归一化(BN)是深度学习中的一项重要技术。在训练过程中使用小批量统计量对激活进行规范化,而在推理过程中使用估计的总体统计量进行规范化。
本文主要研究总体统计量的估计问题。作者定义了BN的估计偏移幅度,以量化衡量其估计的种群统计数据与预期的差异。作者的主要观察是,由于网络中BN的叠加,估计偏移可能会累积,这对测试性能有不利影响。
进一步发现,无批处理的归一化(BFN)可以阻止这种估计漂移的累积。这些观察结果促使作者设计了XBNBlock,在残差式网络的瓶颈区用BFN取代一个BN。
在ImageNet和COCO基准测试上的实验表明,XBNBlock持续地提高了不同架构(包括ResNet和ResNeXt)的性能,并且似乎对分布转移更稳健。
欢迎关注公众号CV技术指南,专注于计算机视觉的技术总结、最新技术跟踪、经典论文解读、CV招聘信息。

论文:Delving into the Estimation Shift of Batch Normalization in a Network
论文:https://arxiv.org/abs/2203.10778
代码:未公开
1.介绍
批归一化(BN)在训练过程中使用小批统计量对激活进行归一化,而在推断/测试过程中使用估计的总体统计量。BN确保标准化的小批输出在每次迭代中标准化,使训练稳定,尽管BN普遍取得了成功,但在某些场景中应用时仍会遇到问题。BN的一个很大局限性是它的小批量问题——BN的误差随着批量大小的减小而迅速增加。此外,如果训练数据和测试数据之间存在协变量偏移,具有朴素BN的网络的性能会显著退化。
虽然这些问题在不同的场景和上下文中出现,但用于推断的BN的估计总体统计量似乎是它们之间的联系:
1)如果在测试期间对BN的估计总体统计量进行纠正,则可以缓解BN的小批量问题;
2)一个模型如果基于可用的测试数据对BN的估计总体统计量进行调整,则对未见的领域数据(损坏的图像)更稳健。
本文对总体统计量的估计进行了系统的研究。作者引入了BN的期望总体统计量,考虑到在训练过程中激活的不明确的总体统计量具有变化的分布。如果BN的估计总体统计量与期望统计量不相等,将其称为估计偏移,并设计实验来定量研究估计偏移如何影响批处理归一化网络。作者通过实验观察到BN的估计偏移可以在一个网络中累积(图1)。进一步发现,一个无批处理的归一化(BFN)——独立地对每个样本进行归一化,而不跨越批处理维度——可以阻止BN估计漂移的积累。这缓解了分布漂移时网络性能的退化。这些观察结果促使设计了XBNBlock,在残差型网络的瓶颈处用BFN取代一个BN。
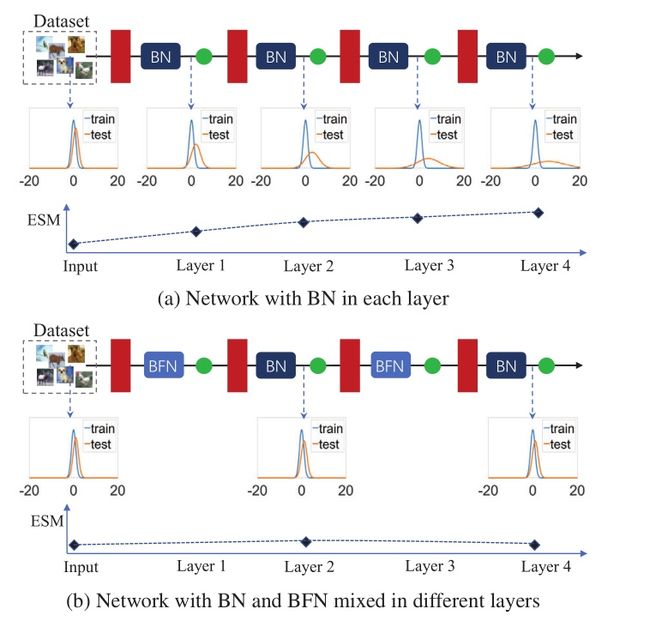
图1 主要观察结果说明
2.相关工作
2.1总体统计的估算和利用:
批归一化(BN)存在小批量问题,因为对总体统计数据的估计可能不准确。为了解决这一问题,提出了多种无批处理规范化(batch-free normalization, BFN)方法,如层规范化(layer normalization, LN)和组规范化(group normalization, GN)。这些工作在训练和推理过程中对每个样本执行相同的归一化操作。这些工作可能优于小批量训练的BN,其中估计是主要问题,但当批量大小适中时,它们的性能通常较差。
一些工作专注于仅在推断期间估计校正的归一化统计量,无论是领域自适应,腐败鲁棒性,还是小批量大小训练。这些策略并不影响模型的训练方案。
与上述工作相比,本文所做的的工作侧重于研究网络中BN的估计偏移。
2.2将BN与其他归一化方法相结合:
也有研究通过结合不同的归一化策略在一个层中构建归一化模块。不同于这些在一个层中构建规范化模块的方法,本文提出的XBNBlock是一个在不同层中混合了BN和BFN的构建块。此外,作者观察发现,BFN可以阻止网络中BN估计漂移的累积,这为上述方法将BN与其他归一化方法结合起来的成功提供了一个新的视角。
本文的工作与IBN-Net密切相关,它集成了实例归一化(instance normalization, IN)和BN作为构建块,并可以包装成几个深度网络来提高它们的性能。在此,作者着重观察到BFN(如IN)可以阻止BNs估计漂移的积累,这也为IBN-Net的测试性能的成功提供了合理的解释,特别是在分布漂移的情况下。
3.方法
3.1准备工作
Batch normalization: 设x∈Rd为给定层的多层感知器(MLP)的d维输入。在训练过程中,批归一化将m个小批数据中的每个神经元/通道归一化:

在推断/测试中的归一化如下:
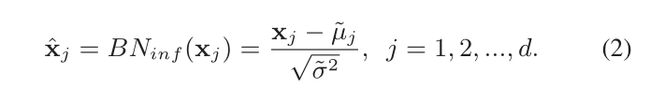
尽管层输入的总体统计均值和方差是不明确的,他们的估计值通常在Eqn. 2中使用,通过计算不同训练迭代t上的小批量统计的运行平均值,使用更新因子α如下:
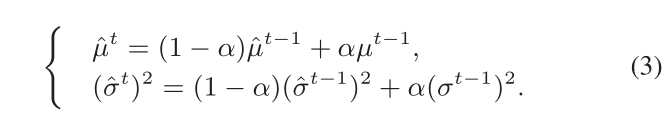
Batch-free normalization:无批归一化的存在是为了避免沿着批维进行归一化,从而避免对总体统计量的估计。这些方法在训练和推理过程中使用一致的操作。一个代表性的方法是层归一化(LN),它对每个训练样本的神经元内的层输入进行标准化,如下:
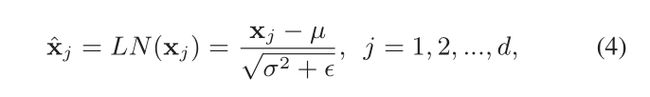
通过改变分组数,GN比LN更灵活,使其能够在仅限于小批量训练的视觉任务(如目标检测和分割)上取得良好的性能。虽然这些BFN方法在某些场景下可以很好地工作,但在大多数情况下它们的性能无法与BN相比,因此在CNN的架构中并不常用。
3.2批归一化的估计移位
在给定BN的期望总体统计量的情况下,如果BN的估计总体统计量与期望统计量不相等,则称为BN的估计偏移。研究BN的估计偏移对批处理归一化网络性能的影响具有重要意义。因此,本文试图定量地衡量估计统计量与预期统计量之间的差异程度。对于衡量的标准,文中有如下定义:
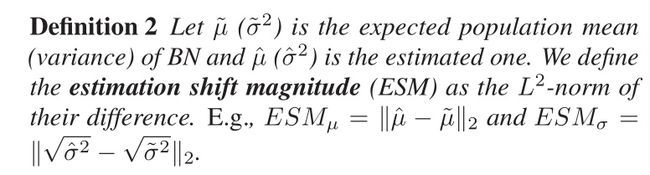
本文设置了两个实验来研究BN的估计偏移如何影响批处理归一化网络的性能以及如何进行校正。
设置1中,使用训练集等于测试集,研究在输入数据无分布偏移的情况下BN的估计偏移。如图2所示。这一现象清楚地表明,训练和测试之间的误差差距主要是由于对BN总体统计数据估计不准确造成的,而且由于BN层的叠加,对总体统计数据的不准确估计可能会被累积/复合。
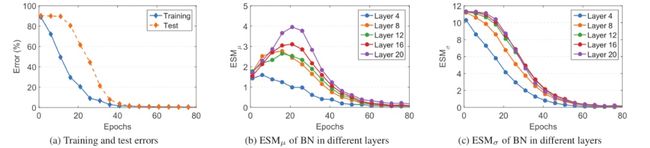
图2 训练集等于测试集的实验
设置2中,训练集是从测试集中采样得来的,通过改变训练集|S|的大小来调节训练集和测试集之间的分布转移。目的是希望看到变化的分布如何移位会影响网络中BN种群统计量的估计。如图3所示。这些观察表明,输入在训练集和测试集之间的分布偏移会导致BN的估计偏移,这对测试性能有不利的影响,而且在更深层次的BN的ESMσ在训练结束时具有潜在的更高的价值。
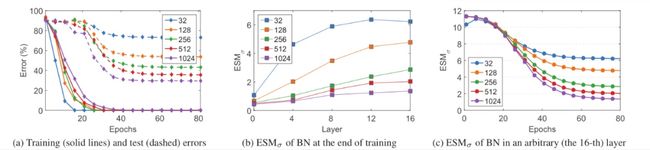
图3 训练集从测试集中采样的实验
通过以上观察,作者将奇数层的BNs替换为GNs,并将该网络称为“GNBN”。遵循前两个实验设置,并分别在图4和图5中显示结果。
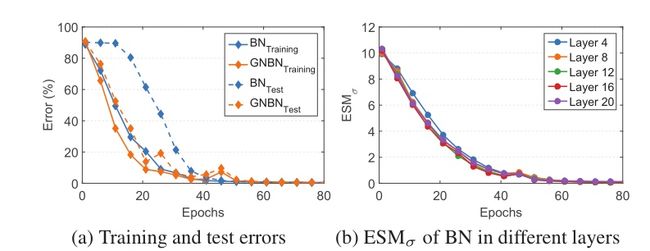
图4 遵循图2混合BN和GN的网络上的实验
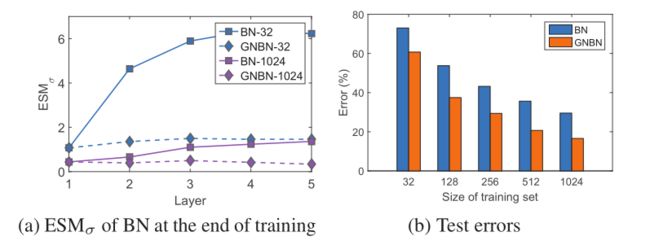
图5 遵循图3混合BN和GN的网络上的实验
根据上面的实验,作者认为BFN(例如GN)可以阻止网络中BN的估计漂移的积累,在分布漂移存在的情况下,可以缓解网络性能的退化。##4.实验部分 本文设计了XBNBlock来代替一个BN在瓶颈处使用BFN(图6 (a)),它广泛应用于残差型网络。图6 (b)显示了替换第二个的拟议的“XBNBlock-P2”。
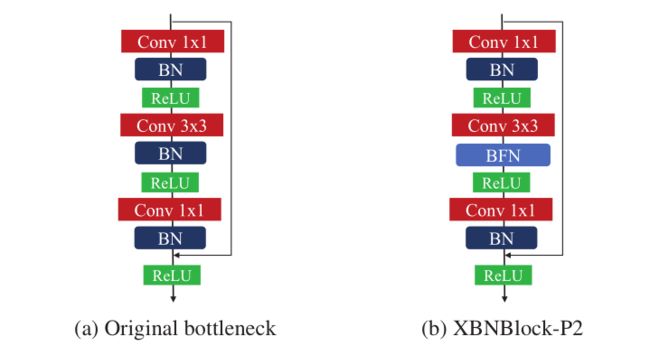
图6 Bottleneck vs 'XBNBlock-P2'
为了研究在XBNBlock中应用BFN的位置,本文使用GN(group=64)作为BFN。本文考虑了三个XBNBlock变体,它们取代了瓶颈中的第一个、第二个和第三个BN,分别称为“XBNBlock- p1”、“XBNBlock- p2”和“XBNBlock- p3”。将这些xbnblock替换为ResNet-50的所有瓶颈,结果如表1显示。观察到“XBNBlock-P2”获得了最好的性能,在接下来的实验中,默认将“XBNBlock-P2”(图6)作为XBNBlock。
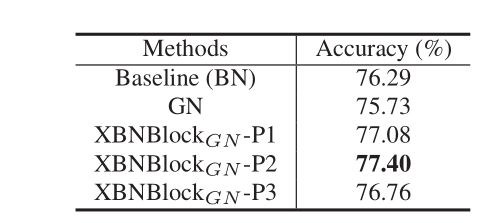
表1 在XBNBlock应用GN时不同位置的结果
作者还研究了XBNBlock在网络中的应用位置。结果如图7所示。作者将这一现象归因于IN对归一化输出提供了更强的约束,这会影响模型的表示能力。
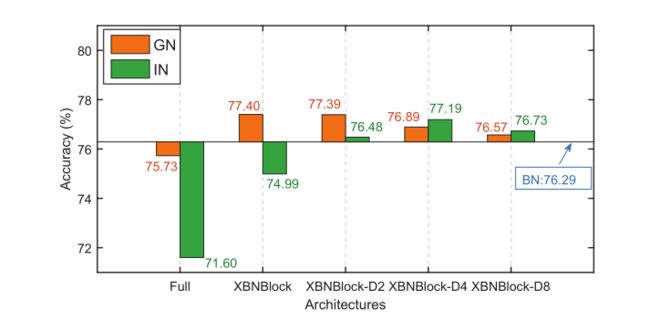
图7 在网络中应用XBNBlock时,不同位置的验证准确率Top-1
在ResNet-101、ResNeXt-50和ResNeXt-101上验证了XBNBlock的有效性。baseline是使用BN训练的原始网络,同时我们也使用GN训练模型。结果如表2所示。我们可以看到,与所有架构相比,我们的方法始终显著地提高了baseline(BN)。

表2 ResNets和 ResNeXts上的Top-1准确率(% )用于 ImageNet
除了上述中描述的标准训练策略外,本文还使用更高级的训练策略进行实验。XBNBlock的表现也始终显著优于baseline。表3显示了ResNet-50的结果。

表3 使用高级训练在 ResNet-50 上的Top-1准确率(% )策略
本文使用Faster R-CNN框架进行目标检测,并使用在ImageNet(表2)上预训练的ResNet-50模型作为骨干,结合特征金字塔网络(FPN)。本文考虑了两种设置:1)使用由两个完全连接层'2fc'组成的box head,而没有规范化层;2)将'2fc'box head替换为'4conv1fc',并为'GN'和'XBNBlockGN'应用GN到FPN和box head。结果在表4中报告。

表4 使用Faster R-CNN框架对COCO进行检测和分割的结果(%)
使用Mask R-CNN框架进行目标检测和实例分割。本文使用ResNet-50和ResNeXt-101模型在ImageNet上预训练(表2)作为骨干,并结合FPN。我们考虑了”2fc”和”4conv1fc”设置。我们再次使用由掩码R- CNN代码库提供的训练脚本的默认超参数配置。结果如表5所示。XBNBlock预训练模型的性能始终显著优于BN†和GN。

表5 使用Mask R-CNN框架对COCO进行检测和分割的结果(%)
XBNBlock的一个主要担忧是,由于BNs的存在,它不能在小批量的训练场景下很好地工作。在这里,本文从零开始训练Faster R-CNN,并使用没有冻结的正常BN。本文使用ResNet-50作为backbone和遵循与之前实验相同的设置,除了:1)在每个GPU上改变了{2,4,8}中的批大小(BS);2)在{0.01,0.02,0.04}中搜索学习率考虑到BS的变化,并显示了最佳的性能。如表6所示。我们可以看到,在批大小为4和8的情况下,XBNBlockGN获得了明显优于BN和GN的性能。

表6 从头训练对COCO的检测结果(%)
5.结论
本文发现BN的估计偏移在网络中会累积,这会导致网络在测试过程中受到不利影响,而无批处理的归一化可以阻止这种估计偏移的累积,从而缓解网络在分布偏移时的性能退化。这些观察结果可能有助于理解归一化在不同场景中的应用,并为更好的性能设计架构。
CV技术指南创建了一个计算机视觉技术交流群和免费版的知识星球,目前星球内人数已经700+,主题数量达到200+。
知识星球内将会每天发布一些作业,用于引导大家去学一些东西,大家可根据作业来持续打卡学习。
CV技术群内每天都会发最近几天出来的顶会论文,大家可以选择感兴趣的论文去阅读,持续follow最新技术,若是看完后写个解读给我们投稿,还可以收到稿费。 另外,技术群内和本人朋友圈内也将发布各个期刊、会议的征稿通知,若有需要的请扫描加好友,并及时关注。
加群加星球方式:关注公众号CV技术指南,获取编辑微信,邀请加入。
公众号其它文章
计算机视觉入门路线
计算机视觉中的论文常见单词总结
YOLO系列梳理(四)关于YOLO的部署
YOLO系列梳理(三)YOLOv5
YOLO系列梳理(二)YOLOv4
YOLO系列梳理(一)YOLOv1-YOLOv3
CVPR2022 | 可精简域适应
CVPR2022 | 基于自我中心数据的OCR评估
CVPR 2022 | 使用对比正则化方法应对噪声标签
CVPR2022 | 弱监督多标签分类中的损失问题
CVPR2022 | iFS-RCNN:一种增量小样本实例分割器
CVPR2022 | A ConvNet for the 2020s & 如何设计神经网络总结
CVPR2022 | PanopticDepth:深度感知全景分割的统一框架
CVPR2022 | 重新审视池化:你的感受野不是最理想的
CVPR2022 | 未知目标检测模块STUD:学习视频中的未知目标
CVPR2022 | 基于排名的siamese视觉跟踪
从零搭建Pytorch模型教程(六)编写训练过程和推理过程
从零搭建Pytorch模型教程(五)编写训练过程--一些基本的配置
从零搭建Pytorch模型教程(四)编写训练过程--参数解析
从零搭建Pytorch模型教程(三)搭建Transformer网络
从零搭建Pytorch模型教程(二)搭建网络
从零搭建Pytorch模型教程(一)数据读取
关于快速学习一项新技术或新领域的一些个人思维习惯与思想总结