Unsupervised Pre-Training of Image Features on Non-Curated Data论文研读
Abstract
目前大多数非监督的特征学习的数据集一般都是小且经过精挑细选的,比如说ImageNet,因为评估transfer task的时候使用non-curated的原数据会降低特征的质量.
这篇文章的目的就是去研究在non-curated的数据下的非监督学习的方式.针对这一问题,提出了一种新的无监督方法,即利用自监督和聚类的方法来获取大规模数据中的complementary statistics。我们对来自YFCC100M的9600万张图像进行了验证.在无监督的基准测试方法中取得state of art的效果.
我们还证明,用我们的方法训练一个监督的VGG-16(使用deepercluster得到的卷积层的权重进行对网络进行初始化),在imagenet的验证集上达到了74.9%的top-1的分类精度,比从头开始训练的网络(vgg-16)提高了+0.8%。
1.Introduction
获得大量标注的图像很困难,所以无监督学习的方法就很重要了.
最近的一些工作都展示了无监督学习的方式的效果和有监督的的方式越来越靠近了.然而,他们都是训练在ImageNet上面的,而训练的方式就是简单的刨除了标签,但是它仅仅还是移除了人类的监督(标签),但是ImageNet里面的数据还是经过精挑细选的,并且里面的类别都是balance的,所有这篇文章主要是在没有经过这样处理的YFCC100M的数据集上做的,这个数据集里面包括了9900万的没有标注且不是精挑细选的从Flickr这个图像分享网站上面的图像.这个数据集是unbalanced的,类别数呈现"long-tail"分布(这正是和ImageNet相反的地方),比如guenon这个类别和baseball这个类别在ImageNet上面都是1300张,但是在YFCC100M里面,一个是226张,一个是256758张,非常的unbalanced.
我们提出了一种新的无监督方法,专门用来利用大量的原始数据,事实上,关于大规模的non-curated数据的训练需要(一)模型的复杂性随数据集的大小而增加;(二)模型对数据分布变化的稳定性。一个简单而有效的解决方案是将无监督学习的两个领域的方法结合起来:聚类和自监督学习.
由于聚类方法,如深度聚类,是从图像间(inter-image)的相似性来建立监督,所以当图像数量增加时,手头的任务就变得更加复杂。此外,当聚类的数量随数据集的大小变化时,DeepCluster可以捕捉到图像之间更细微的关系。聚类方法在推断目标标签的同时,特征也在被学习。因此,目标标签在训练过程演变,所有使得基于聚类的方法不稳定。(大概意思就是每训练一次就聚类一次,每次学习到的特征都在变,让再将特征聚类,所有基于聚类的方法不是很稳定).此外,这些方法直接依赖底层数据的簇结构,因此对数据分布非常敏感(比如上面提到的long-tail)。假设我们知道潜在类的分布,显式地处理不平衡的类别分配可能是一个解决方案.但是我们这个方法是不知道潜在类的分布的.另一方面,自监督学习是通过从输入信号中自动提取预测伪标签来设计一个pretext task.换句话说,自我监督的方法,如RotNet,利用图像内部(intra-image)的统计信息来建立监督,这通常与数据分布无关。然而,数据集的大小对任务的性质和结果特征的性能几乎没有影响.利用较大数据集的解决方案需要手动增加自我监督任务的难度.我们的方法通过聚类策略自动地增加复杂性。

(简单的介绍一下这个表:RotNet是利用图像内部(intra-image)的统计信息来建立监督,这通常与数据分布无关。所有对于long-tail类型的数据可能效果比较好,而deepcluster是利用图像之间的统计信息来建立监督,对long-tail类型可能效果并不是特别好,.所以作者结合deepcluster和rotnet提出来deepercluster这一个模型.)
DeeperCluster,在自我监督的约束下,通过对整个数据集的特征进行聚类,自动生成目标。由于原始数据的long-tail分布,处理大数据集和学习大量的标签是必要的,使得问题从计算的角度具有挑战性。对于这一个问题,作者提出了层次公式去适应分布式训练.这种方式能够去探索发现在tail部分潜在的种类.(可以去了解一下什么是long-tail效应).虽然我们的框架是通用的,但在实践中我们侧重于将Gidaris(rotnet)等人[15]的旋转监督分类任务与Caron(deepcluster)等人[6]的聚类方法相结合。图1所示,当我们增加训练图像的数量时,特征的质量会提高并超过那些在curated数据集上没有标签的训练图像的质量。
2.Related Work
Self-supervision
自监督学习从输入信号中建立一个pretext task来训练一个不带标注的模型。现在提出了很多pretext task,其中包括利用空间上下文、跨通道预测或视频的时间结构。一些pretext task明确地鼓励表示对特定类型的输入转换是不变的或有区别的。例如,Dosovitskiy等人的认为每个图像及其转换是一个类,以强制数据转换的不变性。在这篇论文中,作者建立在Gidaris(rotnet)等人的工作上,他们的模型鼓励特征对于图像的旋转是有区别的。最近,Kolesnikov等人在不同的卷积网络架构产生了了一个广泛的自监督学习方法的benchmark。与我们的工作相反,他们使用curated数据集进行预培训。
Deep clustering
聚类、密度估计和降维是无监督学习方法的一家子。人们曾尝试使用聚类来训练convnets。我们的论文以Caron(deepcluster)等人的工作为基础,其中k-means被用来聚类视觉表示。与我们的工作不同,他们主要专注于使用没有标签的ImageNet来训练他们的方法。最近,Noroozi等人的表明,聚类也可以作为一种distillation(蒸馏)的形式来提高自我监督训练的网络的性能。与我们的工作相反,他们只是把聚类作为一个后处理步骤,并没有利用聚类和自我监督之间的互补性来进一步提高特性的质量.
Learning on non-curated datasets
一些方法旨在从non-curated的数据流中学习视觉特征。它们通常使用诸如散列标记或地理定位之类的元数据作为嘈杂的支持。特别是Mahajan等人,训练了一个网络,将数十亿的Instagram图片分类为预定义的干净的标签集。它们表明,在几乎不需要人为干预的情况下,学习一些能够很好地传递给大脑的功能是可能的,如果fine-tuned得好,能达到最先进的性能(SOTA)。与我们的工作相反,他们使用一个必须清理的外部监督来源.
3. Preliminaries
在自监督学习中,使用pretext task直接从数据中提取目标标签。这些标签可以采取多种形式。它们可以被归类为与一个多类问题相关的类别标签,比如预测旋转的角度.
假设我们有一组n个图像{x1,…,xN}我们为每个输入分配一个pseudo-labels(伪标签)。鉴于这些pseudo-labels,我们学习的参数θ(卷积层的参数)会同线性分类器V预测pseudo-labels解决这个问题:

yn是聚类生成的伪标签,fθ(xn)是卷积层提取出来的特征,经过分类器V之后得到预测的标签,将聚类的伪标签yn作为真实标签,去优化θ和V.在优化过程中,伪标签是固定的,学习过程的质量完全取决于它们的相关性.
Rotation as self-supervision
Gidaris等人最近的研究表明,当训练一个卷积神经网络来区分不同的图像的旋转角度(0,90,180,270)时,可以获得良好的特征。我们借鉴了他的pretext task:RotNet,这个网络在自我监督学习这一块表现的很好,这个pretext task与一个多分类相连:分为0,90,180,270这四类.每一个在公式1中的输入xn都被随机旋转,并且与标签yn相关联,yn代表着旋转的角度.
Deep clustering
基于聚类的深层网络方法通常通过对convnets生成的可视化特征进行聚类来构建目标类(target classes)。因此,在训练过程中,标签会随着特征表示的变化而更新,并且在每个时代可能会有所不同.在这种情况下,我们定义了一个潜在的伪标签zn在Z的每个图像n以及相应的线性分类器W.这些clustering-based方法交替学习参数θ和W 和更新伪标签zn,在两次重新分配之间,固定伪标签zn,通过优化参数θ和分类器W,去解决:
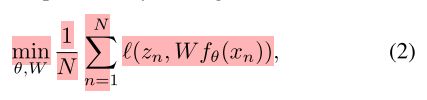
与式(1)的形式相同,通过最小化辅助损失函数,可以重新分配伪标签zn。这种损失有时与Eq.(2)一致,但也有一些工作提出了另一的objective.
Updating the targets with k-means
在这项工作中,我们重点研究了Caron(deepcluster)等人提出的深度聚类的框架,其中利用k-means对活动进行聚类来获得潜在标签。更准确地说,通过求解以下优化问题,实现了目标zn的更新:
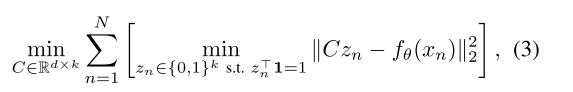
C是一个矩阵,其中每一列对应一个聚类中心, k是聚类中心的数目,zn是一个只有一个非零项的二元向量(里面只有一个1,其实全是0,为1的位置的索引就是预测的标签类别)。该方法假设簇k的数量是先验已知的;在实践中,我们通过对下游任务(dowmstream task)的验证来设置它。当目标最小化(2)时,潜在标签在随机梯度下降T个epoch之后再进行更新(2)。(聚类标签每T个epoch之后才更新一次)
4.Method
在这一节中,我们将描述如何将自监督学习与深度聚类相结合,以扩展到大数据集图像和标签。
4.1. Combining self-supervision and clustering
我们假设输入x1,…, xn为被旋转的图像,每个图像与一个编码其旋转角度的目标标签yn和一个赋值为zn的簇相关.在训练过程中,随着视觉表示(特征)的变化,聚类产生的标签也发生了变化.我们用Y表示可能的旋转角度集合,用Z表示可能的簇分配集合。将自监督与深度聚类相结合的一种方法是将Eq.(1)和Eq.(2)中定义的损失相加。然而,把这些损失加在一起假定旋转和聚类关系是两个独立的任务,这可能会限制可以捕获的信号.相反,我们使用笛卡尔积空间Y×Z,它可以捕获两个任务之间更丰富的交互。我们得到如下优化问题:

请注意,任何聚类或自监督方法(多目标分类)都可以与这个公式相结合。例如,我们可以使用一个自我监督任务来捕获有关图像块排列、或视频帧排序的信息.但是,这一公式在combined target的数目上不具规模.其复杂度为O(|Y||Z|),这限制了使用大数目的聚类或具有大输出空间的自监督任务.特别是,如果我们想要捕获包含在non-curated数据集tail分布部分的信息,我们可能需要大量聚类数目。因此,我们提出了一个基于scalable的分级损失的方案,它是为适应分布式训练而设计的.
4.2. Scaling up to large number of targets Hierarchical
层次结构损失通常用于语言建模,其目标是从一个大的词汇表中预测一个单词。这些方法不是在完整的词汇表上做出一个decision,而是将这个过程划分为一个层次的decision,每一个包含一个更小的输出空间(split the process in a hierarchy of decisions, each with a smaller output space)。例如,词汇表可以被分成语义相似的词的簇,层次过程将首先观察一个簇,然后在这个簇中观察一个词。

按照这一流程,我们将目标标签划分为一个2级层次结构,在这个层次结构中,我们首先预测(predict,这里应该是predict吗?)一个超类(super-class),然后在其关联的目标标签中预测一个子类。第一个层次是将图像划分为S个超类(super-class),用yn表示图像n的{0,1}S中的超类赋值向量,用yns表示yn的第s项.这个超类的分配是在top-feature上用一个线性分类器V来完成的。层次结构的第二级是通过对每个超类(super-class)内部的划分来实现的。我们用属于超类s的图像n,用zns向量表示在{0,1}Ks的赋值表示ks的子类(意思就是讲s个超类分成K个子类,这样每一个样本就有两个标签:S大类的标签和K小类的标签).有S个子类分类器W1,…,Ws.每一个都预测相对应的超类s中的子类成员。线性分类器的参数(V,W1,…,WS)和θ是通过最小化损失函数共同学习的,损失函数如下:

注意,不属于超类s的图像也不属于这个超类的的ks子类.
Choice of super-classes.
一种自然的划分方法是根据自监督任务的目标标签来定义超类,并根据聚类生成的标签来定义子类。然而,这将意味着整个数据集的每个图像都将出现在每个超类中(具有不同的旋转),这样就不会利用层次结构的优点来使用更多的clusters.
相反,我们通过每隔T个周期在完整数据集上运行m个聚类中心的k- means来将数据集分割成m个集合。然后我们使用分配给这些m个簇和角度旋转类之间的笛卡尔积来形成超类。有4m个超类,每个超类由属于相应集群的数据子集组成(如果集群完全平衡,则为N/m个图像)。然后用k-means将这些子集进一步划分为k个子类。这相当于在完整的数据集上运行一个具有旋转约束的层次k-均值聚类来形成我们的层次损失.我们通常使用m = 4和k = 80k,所有总共有320k个不同的集群被分成4个子集。我们的方法“DeeperCluster”与DeepCluster有相似之处,但deepercluster是设计用于扩展到更大的数据集。我们在对非旋转图像特征进行聚类和训练网络预测输入数据的旋转和与此旋转对应的聚类之间的集群分配之间进行了改变(这里不知道咋翻译的)
Distributed training
构建基于数据分割的超类有助于实现在图像数量上良好扩展的分布式实现。具体地说,在优化式(5)时,我们在p个gpu形成的的分布式communication groups,其数目和超类的数目相同,即G = 4m。不同的communication group共享参数θ和超类分类器V,而子类的的参数分类器W1,…,WS仅在communication group内共享。每个communication group只处理图像的子集和与超类s相关的旋转角度。
Distributed k-means
每隔T个epoch,我们通过在整个数据集上运行两次连续的k-means来重新计算超类和子类的赋值。这是通过在不同的gpu之间随机分割数据集来实现的。每个GPU负责计算其分得的聚类分配,而聚类中心则在GPU之间进行更新。我们通过只sharing每个集群分配的元素数量及其特性的总数来减少gpu之间的通信.然后根据这些统计数据计算新的聚类中心.我们从经验上观察到k-均值在10次迭代中趋于收敛。我们使用64个gpu(每次迭代1分钟)将维度为4096的9千6百万个特征聚类成m = 4个簇。然后,我们将这个gpu池分成4组,每组16个gpu。每个组将23M的特征聚类成80k的聚类中心中(每次迭代4分钟)
4.3. Implementation details
采用小批量随机梯度下降,使Eq.(5)的损失最小化。每个小批处理包含3072个实例(什么实例???),分布在64个GPU中,所以每个小批处理每个GPU中有48个实例。我们使用了dropout, weight decay, momentum和一个恒定的学习速率0.1。我们每3个时代重新分配一次集群。为了加快训练速度,我们在YFCC100M上训练RotNet的权重来初始化网络.
总结一下这个method(转载的):
文章提出了一个基于大规模未处理数据的非监督feature学习方法:DeeperCluster。该方法受self-supervised learning和clustering 两种方法的启发:
1.Self-supervised learning。这类方法通过设计一个“辅助任务”来实现。“辅助任务”会在输入数据上加上一个伪标签,然后用一个网络来预测这个伪标签。例如:把输入的图片旋转一个角度,然后预测旋转的角度。(也可以是对图片做一个transformation,然后预测出transformation)
3.Clustering。其实就是k-means聚类。通过k-means在图片的feature空间上进行聚类,能给每个图片设置一个类标签,然后可以用一个网络来预测这个类标签。
这两个方法,相当于用两种不同的方式,”创造“出两种不同类型的类的集合。假设用Self-supervised learning"创造“出来的类的集合是A,Clustering创造出来的类的集合是B,A和B的笛卡尔乘积为C,用C来表示所有图片的类型的集合(每张图片从属的两个不同类型的类,组合成的新类,肯定在C里面)。然后用一个网络来预测图片所属的新类。通过这种方式,只需要用一个网络,就可以预测两个类型,把Self-supervised learning和Clustering结合到了一起。
Self-supervised learning采用了判断图片旋转类型的方法(参考《Unsupervised representation learning by predicting image rotations》)。Clustering采用了分级的方式:先把所有图片聚类成m个大类;再通过旋转(总共有4中旋转),把一个大类变成4个大类;最后每个大类内的图片再聚类成n的小类。
用k-means在图片的feature空间上进行聚类时,由于在训练过程中,模型参数在不断的更新,相当于feature提取器在不断更新,所以图片的feature空间也在不断的更新。算法并不是每次更新模型参数时,都重新用k-means为所有图片重新聚类,而是每经过T个epoch重新聚类一次。
算法流程如下:
1.最终目的是要训练出来一个好的特征提取网络。所以,先要初始化一个未训练的特征提取网络,用来提取图片feature。
2.用k-means对所有图片(未旋转)的feature进行聚类(clustering),分成m个大类。(每张未旋转的图片有了一个大类的标签)
3.然后将这m个类的每一类分成k个类,对应4中的旋转之后的图像的伪标签.
4.对m个大类进行扩展:用“旋转角度的类型”(4种)和“m个大类“计算笛卡尔乘积,得到4m个新的大类。每张经过旋转的图片,只属于4m个大类里面的一个类型。(每张经过旋转的图片有了一个大类的标签)
5.4m个大类的每个类,再分别使用k-means对属于本类中的图片的feature进行聚类,分成k个子类。(每张经过旋转的图片,在一个大类下面,又有了一个子类的标签)
6.构建1个大类的分类器(4m个大类),每个大类下面再构造1个子类分类器(4个子类),总共1 + 4m个分类器。所有分类器分成两部分:特征提取网络,分类网络。不同分类器的特征提取网络是共享的,分类网络各不相同。然后用Deeper Clustering loss来训练,训练T个epochs。
7.T个epochs后,重新回到第2步。