机器学习概括(学习笔记)
(传统)机器学习
传统机器学习主要有分类(Classification)、回归(Regression)、聚类(Clustering)、降维(Dimensionality Reduction)、决策树(Decision Tree)、集成学习()、强化学习()等多种分类。
1.分类。属于标签为离散值的监督类学习。生成的模型需要根据输入参数打出一个离散型数值(预测类别)。 常见的如,KNN、决策树、逻辑回归。
2.回归。属于标签为连续值的监督类学习。生成的模型需要根据输入参数打出一个连续型数值(预测数值)。常见的如,线性回归、非线形回归、岭回归、支持向量回归。
3.聚类。属于无监督学习。需要根据样本参数按照一定规则划分聚簇,将数据分成不同组别。常见的如,K-Means。
4.降维。属于无监督学习。需要根据样本参数进行矩阵相关运算,将样本参数中较高维度的特征转化为低维度,同时尽可能保留样本中的信息。(可作为聚类的前置步骤)追求用更简洁的方式表现数据。
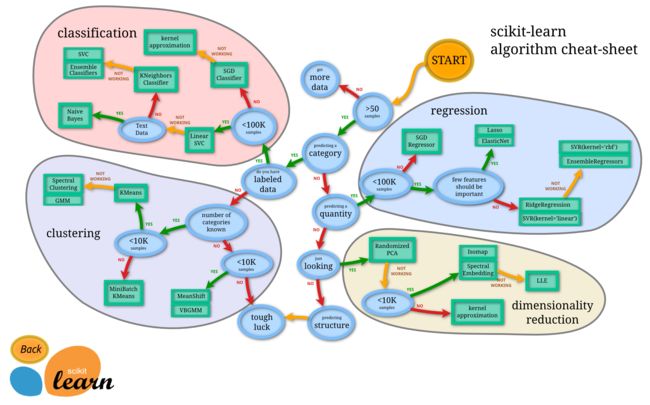
有监督学习(Supervised Learning)
有监督学习指对数据的若干特征与标签之间的关联性进行建模的过程。它的主要目标是从有标签的训练数据中学习模型,以便对未知或未来的数据做出预测。以用户是否会复购鲜花为例,可以采用监督学习算法在打过标签的(正确标识是与否)数据上训练模型,然后用该模型来预测新用户是否属于粘性用户。
注意:机器学习领域的预测变量通常称为特征,而响应变量通常称为目标变量或标签。
应用领域如人脸识别、语音翻译、医学诊断。
无监督学习(Unsupervised Learning)
定义:机器学习的一种方法,没有给定事先标记过的训练示例,自动对输入的数据进行分类或分群。
主要应用:聚类分析、关联分析、维度缩减等。
优点:
1.算法不受监督信息(偏见)的约束,即可以按不同方式分类,并没有一个明确的规定。
2.不需要标签数据,极大程度扩大数据样本。这样在面临成千上万个数据时可以让计算机自动去分类从而节省大量的人力成本。
应用领域如新闻聚类。
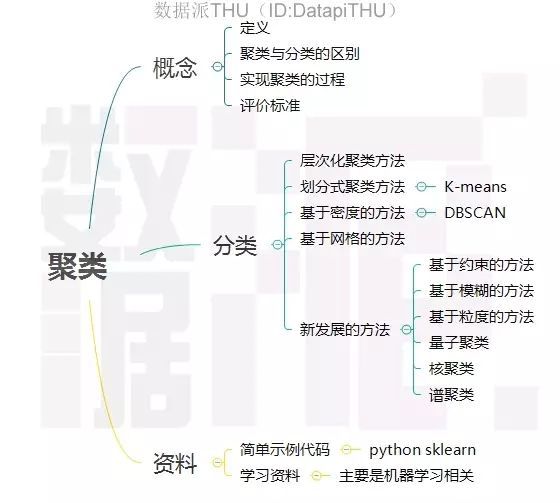
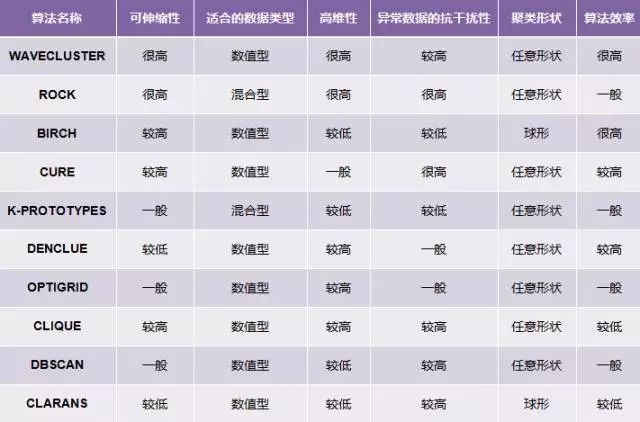
聚类分析
定义:不同于分类,不关心某一类具体是什么原因聚集在一起的,实现的目标只是把相似的东西聚到一起。
聚类结果评估主要有3种:外部有效性评估、内部有效性评估和相关性测试评估。
数据降维
定义:是指在某些限定条件下,降低随机变量的个数,得到一组“不相关”主变量的过程。
优点:
1.减少模型分析的数据量,提升处理效率,降低计算难度
2.实现数据可视化。
比如,我们把十七项指标降为三项指标,得到3个综合因子,就可以少算很多东西,提升我们的效率。同样,如果有十七项指标,我们是不可以把图形画出来的,但如果只有三项指标,我们就可以把数据可视化了。
常用数据降维算法:PCA、SVD
半监督学习(Semi-supervised Learning)/混合学习
半监督学习方法介于有监督学习和无监督学习之间,通常在数据不完整时使用。训练数据包括少量正确的结果。应用在数据量有限,又想实现一个较好的正确的分类。
强化学习(Reinforcement Learning)
根据每次结果收获的奖惩进行学习(+3分,-5分),程序逐步寻找获得高分的方法实现优化。强化学习不同于监督学习,它将学习看作是试探评价过程,以“试错”的方式进行学习,并与环境交互已获得奖惩指导行为,以其作为评价。也就是说,强调如何基于环境而行动,以取得最大化的预期利益。此时,系统靠自身的状态和动作进行学习,从而改进行动方案以适应环境。应用领域如AlphaGo。
数据挖掘建模过程
1.理解商业
到底要干什么?以鲜花店为例,为了提高销售额,店员可以帮助客户快速找到他感兴趣的花束,同时在保证用户体验的情况下,为其附加一个可接受的小饰品,比如花瓶、零食、香水等。
2.理解数据
1)鲜花数据:鲜花名称、鲜花品类、采购时间、采购数量、采购金额等。
2)经营数据:经营时间、预定时间、预定品类、预定人数等。
3)其他数据:是否为节假日、用户口碑、竞争对手动向、天气情况等。
3.准备数据
在数据准备阶段我们需要对数据作出清洗、重建、合并等操作。选出要进行分析的数据,并对不符合模型输入要求的数据进行规范化操作。主要是为建模准备数据,可以从数据预处理、特征提取、特征选择等几方面出发,整理如下:
1)缺失值:由于个人隐私或设备故障导致某些观测值在某些纬度上的漏缺,通常称为缺失值。缺失值存在可能会导致模型结果的错误,所以针对缺失值可以考虑删除、众数或均值填充等解决。
2)异常值:由于远离正常样本的观测点,它们的存在同样会对模型的准确型造成影响。可以通过象限图或3sigma(正态分布)进行判断,如果是,可以考虑删除或单独处理。
3)量纲不一致:模型容易受到不同量纲的影响,因此需要通过标准化方法(通常采用归一化、Normalization之类的方法)将数据进行转换。
4)维度灾难:当数据集中包含上百乃至上千万的变量时,往往会提高模型的复杂度,从而影响模型的运行效率,所以需要采用方差分析、相关分析、主成分分析等手段实现降维。
4.建模型
在最终决定选择哪种模型之前,各种模型都尝试一下,然后再选取一个较好的。各种模型在不同的环境中,优劣会有所不同。
5.评估模型
评估阶段主要是对建模结果进行评估,目的是选出最佳的模型,让这个模型能够更好地反映数据的真实性。并不是每一次建模都能符合我们的目标,对效果较差的结果分析原因,偶尔也会返回前面的步骤对挖掘过程重新定义。比如,对于决策树或者逻辑回归,即使在训练集中表现良好,但在测试集中结果较差,说明该模型存在过拟合。
6.模型部署
建立的模型需要解决实际的问题,它还包括了监督、产生报表和重新评估模型等过程。很多时候建模一般使用spss、python、r等,在建模的过程中只考虑模型的可用性,在生产环境中通常会利用Java或C++等语言将模型改写,从而提高运行性能。