【深度之眼】Pytorch框架班第五期-优化器代码调试
优化器
采用梯度更新模型中的可学习参数,使得模型输出与真实标签的差异最小,即使loss下降。管理并更新模型中可学习参数的值,使得模型输出更接近真实标签。
Optimizer
class Optimizer(object):
def __init__(self, params, defaults):
self.defaults = defaults
self.state = defaultdict(dict)
self.param_groups = []
.
.
.
param_groups=[{'params': param_groups}]
defaults:优化器超参数
state: 参数的缓存,如momentum的缓存
param_groups: 管理的参数组
_step_count: 记录更新次数,学习率调整中使用
基本方法
1、zero_grad(): 清空所管理参数的梯度
pytorch特征:张量梯度不自动清零
class Optimizer(object):
def zero_grad(self):
for group in self.param_groups:
for p in group['params']:
if p.grad is not None:
p.grad.detach_()
p.grad.zero_()
2、step(): 执行一步更新,更新一次可学习参数。
3、add_param_group():添加参数组
class Optimizer(object):
def add_param_group(self, param_group):
for group in self.param_groups:
param_set.update(set(group['params']))
self.param_groups.append(param_group)
4、state_dict():获取优化器当前状态信息字典
5、load_state_dict(): 加载状态信息字典
class Optimizer(object):
def state_dict(self):
return {'state': packed_state,
'param_groups': param_groups,
}
def load_state_dict(self, state_dict):
代码
RMB分类
1、在75行加断点进行Debug。传入模型的参数,并设置超参数。
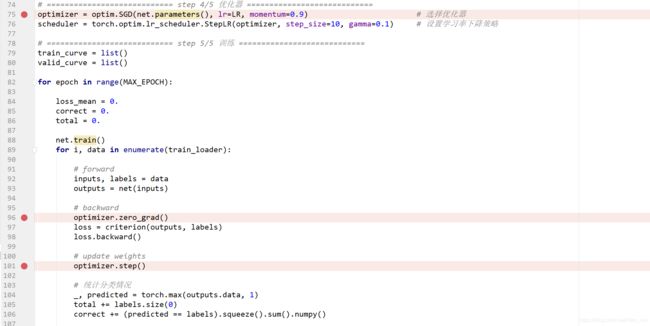
2、点击step into进入sgd.py中SGD类的__init__函数。我们可以看到首先是参数合法性的判断。
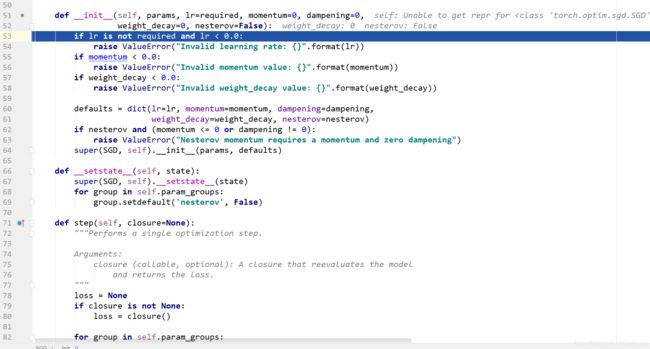
3、运行至64行,进入父类的__init__函数中,
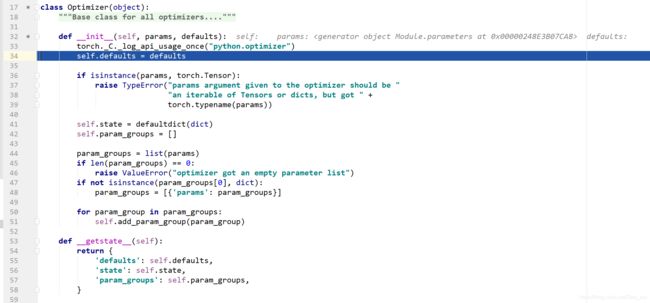
defaults里面为一些超参数。

对于self.param_groups,我们首先创建一个空列表。然后在第51行采用self.add_param_group函数添加参数。
回到主程序我们可以发现,我们的优化器optimizer中的param_groups为一个list,list中的每一个元素为字典,字典中的value为列表params,列表中为所有的可学习参数。
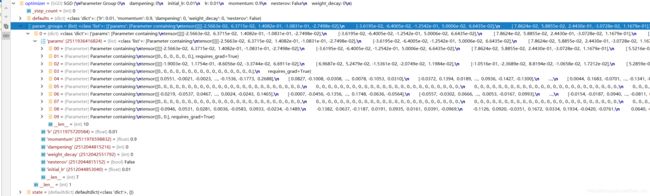
optimizer首先进行初始化,将需要管理和更新的参数放到优化器其中,接着迭代训练时清空梯度,然后使用step更新权值。
使用方法
import os
BASE_DIR = os.path.dirname(os.path.abspath(__file__))
import torch
import torch.optim as optim
import sys
hello_pytorch_DIR = os.path.abspath(os.path.dirname(__file__)+os.path.sep+".."+os.path.sep+"..")
sys.path.append(hello_pytorch_DIR)
from tools.common_tools import set_seed
set_seed(1) # 设置随机种子
weight = torch.randn((2, 2), requires_grad=True)
weight.grad = torch.ones((2, 2))
optimizer = optim.SGD([weight], lr=0.1)
# ----------------------------------- step -----------------------------------
flag = 0
# flag = 1
if flag:
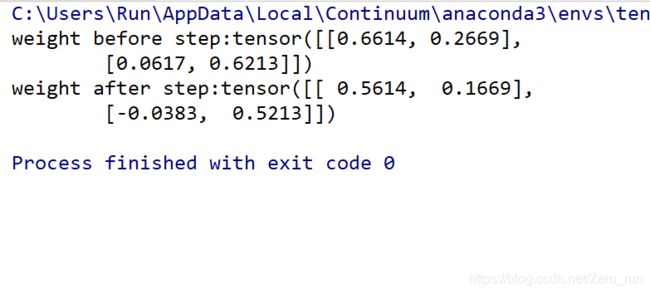
print("weight before step:{}".format(weight.data))
optimizer.step() # 修改lr=1 0.1观察结果
print("weight after step:{}".format(weight.data))
# ----------------------------------- zero_grad -----------------------------------
flag = 0
# flag = 1
if flag:
print("weight before step:{}".format(weight.data))
optimizer.step() # 修改lr=1 0.1观察结果
print("weight after step:{}".format(weight.data))
print("weight in optimizer:{}\nweight in weight:{}\n".format(id(optimizer.param_groups[0]['params'][0]), id(weight)))
print("weight.grad is {}\n".format(weight.grad))
optimizer.zero_grad()
print("after optimizer.zero_grad(), weight.grad is\n{}".format(weight.grad))
# ----------------------------------- add_param_group -----------------------------------
flag = 0
# flag = 1
if flag:
print("optimizer.param_groups is\n{}".format(optimizer.param_groups))
w2 = torch.randn((3, 3), requires_grad=True)
optimizer.add_param_group({"params": w2, 'lr': 0.0001})
print("optimizer.param_groups is\n{}".format(optimizer.param_groups))
# ----------------------------------- state_dict -----------------------------------
flag = 0
# flag = 1
if flag:
optimizer = optim.SGD([weight], lr=0.1, momentum=0.9)
opt_state_dict = optimizer.state_dict()
print("state_dict before step:\n", opt_state_dict)
for i in range(10):
optimizer.step()
print("state_dict after step:\n", optimizer.state_dict())
torch.save(optimizer.state_dict(), os.path.join(BASE_DIR, "optimizer_state_dict.pkl"))
# -----------------------------------load state_dict -----------------------------------
flag = 0
# flag = 1
if flag:
optimizer = optim.SGD([weight], lr=0.1, momentum=0.9)
state_dict = torch.load(os.path.join(BASE_DIR, "optimizer_state_dict.pkl"))
print("state_dict before load state:\n", optimizer.state_dict())
optimizer.load_state_dict(state_dict)
print("state_dict after load state:\n", optimizer.state_dict()
运行step观察weight的变化
zero_grad()

add_param_group

state_dict
![]()
load_state_dict
![]()