爽啊,这么多有趣好玩强大的 Python 库
Python语言简洁、易读以及可扩展,在国内外用 Python 做研究的非常多。
Python 语言向来以丰富的第三方库而闻名。这么多有趣好玩且强大,靠一个人去寻找太难了。
最近粉丝群小伙伴们又罗列了一些,分享给大家。喜欢记得点个赞,加入见文末
文章目录
- 数据采集
-
- AKShare
- TuShare
- GoPUP
- GeneralNewsExtractor
- 爬虫
-
- playwright-python
- awesome-python-login-model
- DecryptLogin
- Scylla
- ProxyPool
- getproxy
- freeproxy
- fake-useragent
- Web 相关
-
- streamlit
- wagtail
- fastapi
- django-blog-tutorial
- dash
- PyWebIO
- Python 教程
-
- practical-python
- learn-python3
- python-guide
- 其他
-
- pytools
- amazing-qr
- sh
- tqdm
- loguru
- click
- KeymouseGo
- 技术交流
数据采集
在当今互联网时代,数据实在是太重要了,首先我们就来介绍几个优秀的数据采集项目
AKShare
AKShare 是基于 Python 的财经数据接口库,目的是实现对股票、期货、期权、基金、外汇、债券、指数、加密货币等金融产品的基本面数据、实时和历史行情数据、衍生数据从数据采集、数据清洗到数据落地的一套工具,主要用于学术研究目的。
import akshare as ak
stock_zh_a_hist_df = ak.stock_zh_a_hist(symbol="000001", period="daily", start_date="20170301", end_date='20210907', adjust="")
print(stock_zh_a_hist_df)
Output:
日期 开盘 收盘 最高 ... 振幅 涨跌幅 涨跌额 换手率
0 2017-03-01 9.49 9.49 9.55 ... 0.84 0.11 0.01 0.21
1 2017-03-02 9.51 9.43 9.54 ... 1.26 -0.63 -0.06 0.24
2 2017-03-03 9.41 9.40 9.43 ... 0.74 -0.32 -0.03 0.20
3 2017-03-06 9.40 9.45 9.46 ... 0.74 0.53 0.05 0.24
4 2017-03-07 9.44 9.45 9.46 ... 0.63 0.00 0.00 0.17
... ... ... ... ... ... ... ... ...
1100 2021-09-01 17.48 17.88 17.92 ... 5.11 0.45 0.08 1.19
1101 2021-09-02 18.00 18.40 18.78 ... 5.48 2.91 0.52 1.25
1102 2021-09-03 18.50 18.04 18.50 ... 4.35 -1.96 -0.36 0.72
1103 2021-09-06 17.93 18.45 18.60 ... 4.55 2.27 0.41 0.78
1104 2021-09-07 18.60 19.24 19.56 ... 6.56 4.28 0.79 0.84
[1105 rows x 11 columns]
https://github.com/akfamily/akshare
TuShare
TuShare 是实现对股票/期货等金融数据从数据采集、清洗加工到数据存储过程的工具,满足金融量化分析师和学习数据分析的人在数据获取方面的需求,它的特点是数据覆盖范围广,接口调用简单,响应快速。
不过该项目有一部分功能是收费的,大家选择使用哦
import tushare as ts
ts.get_hist_data('600848') #一次性获取全部数据
Output:
open high close low volume p_change ma5 \
date
2012-01-11 6.880 7.380 7.060 6.880 14129.96 2.62 7.060
2012-01-12 7.050 7.100 6.980 6.900 7895.19 -1.13 7.020
2012-01-13 6.950 7.000 6.700 6.690 6611.87 -4.01 6.913
2012-01-16 6.680 6.750 6.510 6.480 2941.63 -2.84 6.813
2012-01-17 6.660 6.880 6.860 6.460 8642.57 5.38 6.822
2012-01-18 7.000 7.300 6.890 6.880 13075.40 0.44 6.788
2012-01-19 6.690 6.950 6.890 6.680 6117.32 0.00 6.770
2012-01-20 6.870 7.080 7.010 6.870 6813.09 1.74 6.832
ma10 ma20 v_ma5 v_ma10 v_ma20 turnover
date
2012-01-11 7.060 7.060 14129.96 14129.96 14129.96 0.48
2012-01-12 7.020 7.020 11012.58 11012.58 11012.58 0.27
2012-01-13 6.913 6.913 9545.67 9545.67 9545.67 0.23
2012-01-16 6.813 6.813 7894.66 7894.66 7894.66 0.10
2012-01-17 6.822 6.822 8044.24 8044.24 8044.24 0.30
2012-01-18 6.833 6.833 7833.33 8882.77 8882.77 0.45
2012-01-19 6.841 6.841 7477.76 8487.71 8487.71 0.21
2012-01-20 6.863 6.863 7518.00 8278.38 8278.38 0.23
https://github.com/waditu/tushare
GoPUP
GoPUP 项目所采集的数据皆来自公开的数据源,不涉及任何个人隐私数据和非公开数据。不过同样的,部分接口是需要注册 TOKEN 才能使用的。
import gopup as gp
df = gp.weibo_index(word="疫情", time_type="1hour")
print(df)
Output:
疫情
index
2022-12-17 18:15:00 18544
2022-12-17 18:20:00 14927
2022-12-17 18:25:00 13004
2022-12-17 18:30:00 13145
2022-12-17 18:35:00 13485
2022-12-17 18:40:00 14091
2022-12-17 18:45:00 14265
2022-12-17 18:50:00 14115
2022-12-17 18:55:00 15313
2022-12-17 19:00:00 14346
2022-12-17 19:05:00 14457
2022-12-17 19:10:00 13495
2022-12-17 19:15:00 14133
https://github.com/justinzm/gopup
GeneralNewsExtractor
该项目基于《基于文本及符号密度的网页正文提取方法》论文,使用 Python 实现的正文抽取器,可以用来提取 HTML 中正文的内容、作者、标题。
>>> from gne import GeneralNewsExtractor
>>> html = '''经过渲染的网页 HTML 代码'''
>>> extractor = GeneralNewsExtractor()
>>> result = extractor.extract(html, noise_node_list=['//div[@class="comment-list"]'])
>>> print(result)
Output:
{"title": "xxxx", "publish_time": "2019-09-10 11:12:13", "author": "yyy", "content": "zzzz", "images": ["/xxx.jpg", "/yyy.png"]}
新闻页提取示例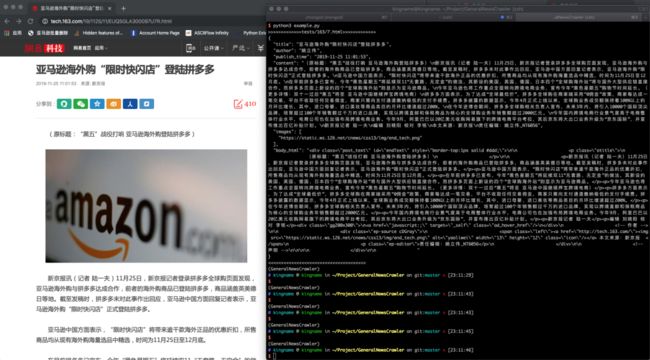
https://github.com/GeneralNewsExtractor/GeneralNewsExtractor
爬虫
爬虫也是 Python 语言的一大应用方向,很多朋友也都是以爬虫来入门的,我们来看看有哪些优秀的爬虫项目吧
playwright-python
微软开源的浏览器自动化工具,可以用 Python 语言操作浏览器。支持 Linux、macOS、Windows 系统下的 Chromium、Firefox 和 WebKit 浏览器。
from playwright.sync_api import sync_playwright
with sync_playwright() as p:
for browser_type in [p.chromium, p.firefox, p.webkit]:
browser = browser_type.launch()
page = browser.new_page()
page.goto('http://whatsmyuseragent.org/')
page.screenshot(path=f'example-{browser_type.name}.png')
browser.close()
https://github.com/microsoft/playwright-python
awesome-python-login-model
该项目收集了各大网站登陆方式和部分网站的爬虫程序。登陆方式实现包含 selenium 登录、通过抓包直接模拟登录等。有助于新手研究、编写爬虫。
不过众所周知,爬虫是非常吃后期维护的,该项目已经很久没有更新了,所以各种登录接口是否还能正常使用,还存在疑问,大家选择使用,或者自行二次开发。

https://github.com/Kr1s77/awesome-python-login-model
DecryptLogin
相比于上一个,该项目则还在持续更新,同样是模拟登录各大网站,对于新手还是非常有研究价值的。
from DecryptLogin import login
# the instanced Login class object
lg = login.Login()
# use the provided api function to login in the target website (e.g., twitter)
infos_return, session = lg.twitter(username='Your Username', pd='Your Password')
https://github.com/CharlesPikachu/DecryptLogin
Scylla
Scylla 是一款高质量的免费代理 IP 池工具,当前仅支持 Python 3.6。
http://localhost:8899/api/v1/stats
Output:
{ "median": 181.2566407083, "valid_count": 1780, "total_count": 9528, "mean": 174.3290085201 }
https://github.com/scylladb/scylladb
ProxyPool
爬虫代理IP池项目,主要功能为定时采集网上发布的免费代理验证入库,定时验证入库的代理保证代理的可用性,提供API和CLI两种使用方式。同时也可以扩展代理源以增加代理池IP的质量和数量。该项目设计文档详细、模块结构简明易懂,同时适合爬虫新手更好的学习爬虫技术。
import requests
def get_proxy():
return requests.get("http://127.0.0.1:5010/get/").json()
def delete_proxy(proxy):
requests.get("http://127.0.0.1:5010/delete/?proxy={}".format(proxy))
# your spider code
def getHtml():
# ....
retry_count = 5
proxy = get_proxy().get("proxy")
while retry_count > 0:
try:
html = requests.get('http://www.example.com', proxies={"http": "http://{}".format(proxy)})
# 使用代理访问
return html
except Exception:
retry_count -= 1
# 删除代理池中代理
delete_proxy(proxy)
return None
https://github.com/Python3WebSpider/ProxyPool
getproxy
getproxy 是一个抓取发放代理网站,获取 http/https 代理的程序,每 15 min 更新数据。
(test2.7) ➜ ~ getproxy
INFO:getproxy.getproxy:[*] Init
INFO:getproxy.getproxy:[*] Current Ip Address: 1.1.1.1
INFO:getproxy.getproxy:[*] Load input proxies
INFO:getproxy.getproxy:[*] Validate input proxies
INFO:getproxy.getproxy:[*] Load plugins
INFO:getproxy.getproxy:[*] Grab proxies
INFO:getproxy.getproxy:[*] Validate web proxies
INFO:getproxy.getproxy:[*] Check 6666 proxies, Got 666 valid proxies
...
https://github.com/fate0/getproxy
freeproxy
同样是一个抓取免费代理的项目,该项目支持抓取的代理网站非常多,而且使用简单。
from freeproxy import freeproxy
proxy_sources = ['proxylistplus', 'kuaidaili']
fp_client = freeproxy.FreeProxy(proxy_sources=proxy_sources)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/98.0.4758.102 Safari/537.36'
}
response = fp_client.get('https://space.bilibili.com/406756145', headers=headers)
print(response.text)
https://github.com/CharlesPikachu/freeproxy
fake-useragent
伪装浏览器身份,常用于爬虫。这个项目的代码很少,可以阅读一下,看看ua.random是如何返回随机的浏览器身份的。
from fake_useragent import UserAgent
ua = UserAgent()
ua.ie
# Mozilla/5.0 (Windows; U; MSIE 9.0; Windows NT 9.0; en-US);
ua.msie
# Mozilla/5.0 (compatible; MSIE 10.0; Macintosh; Intel Mac OS X 10_7_3; Trident/6.0)'
ua['Internet Explorer']
# Mozilla/5.0 (compatible; MSIE 8.0; Windows NT 6.1; Trident/4.0; GTB7.4; InfoPath.2; SV1; .NET CLR 3.3.69573; WOW64; en-US)
ua.opera
# Opera/9.80 (X11; Linux i686; U; ru) Presto/2.8.131 Version/11.11
ua.chrome
# Mozilla/5.0 (Windows NT 6.1) AppleWebKit/537.2 (KHTML, like Gecko) Chrome/22.0.1216.0 Safari/537.2'
ua.google
# Mozilla/5.0 (Macintosh; Intel Mac OS X 10_7_4) AppleWebKit/537.13 (KHTML, like Gecko) Chrome/24.0.1290.1 Safari/537.13
ua['google chrome']
# Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11
ua.firefox
# Mozilla/5.0 (Windows NT 6.2; Win64; x64; rv:16.0.1) Gecko/20121011 Firefox/16.0.1
ua.ff
# Mozilla/5.0 (X11; Ubuntu; Linux i686; rv:15.0) Gecko/20100101 Firefox/15.0.1
ua.safari
# Mozilla/5.0 (iPad; CPU OS 6_0 like Mac OS X) AppleWebKit/536.26 (KHTML, like Gecko) Version/6.0 Mobile/10A5355d Safari/8536.25
# and the best one, get a random browser user-agent string
ua.random
https://github.com/fake-useragent/fake-useragent
Web 相关
Python Web 有太多优秀且老牌的库了,比如 Django,Flask 就不说了,大家都知道,我们介绍几个小众但是好用的。
streamlit
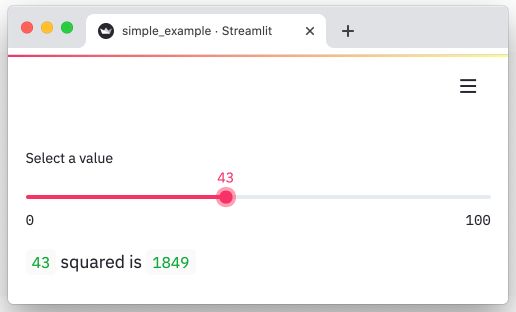
streamlit 能够快速地把数据制作成可视化、交互页面的 Python 框架。分分钟让我们的数据变成图表。
import streamlit as st
x = st.slider('Select a value')
st.write(x, 'squared is', x * x)
Output:
https://github.com/streamlit/streamlit
wagtail
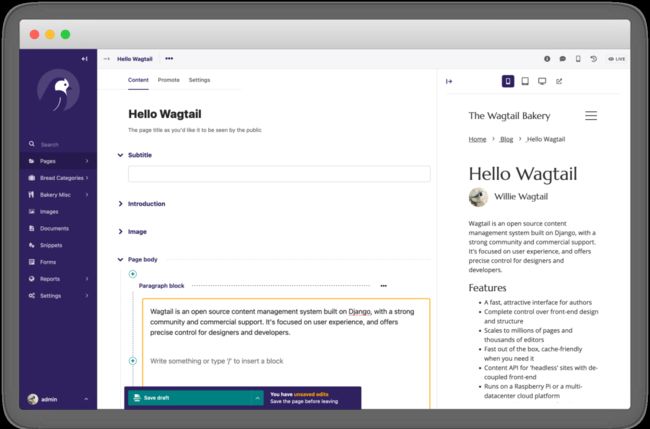
是一个强大的开源 Django CMS(内容管理系统)。首先该项目更新、迭代活跃,其次项目首页提到的功能都是免费的,没有付费解锁的骚操作。专注于内容管理,不束缚前端实现。
https://github.com/wagtail/wagtail
fastapi
基于 Python 3.6+ 的高性能 Web 框架。“人如其名”用 FastAPI 写接口那叫一个快、调试方便,Python 在进步而它基于这些进步,让 Web 开发变得更快、更强。
from typing import Union
from fastapi import FastAPI
app = FastAPI()
@app.get("/")
def read_root():
return {"Hello": "World"}
@app.get("/items/{item_id}")
def read_item(item_id: int, q: Union[str, None] = None):
return {"item_id": item_id, "q": q}
https://github.com/tiangolo/fastapi
django-blog-tutorial
这是一个 Django 使用教程,该项目一步步带我们使用 Django 从零开发一个个人博客系统,在实践的同时掌握 Django 的开发技巧。
https://github.com/jukanntenn/django-blog-tutorial
dash
dash 是一个专门为机器学习而来的 Web 框架,通过该框架可以快速搭建一个机器学习 APP。
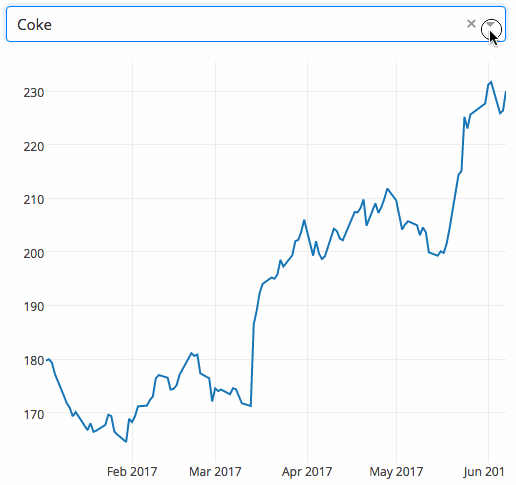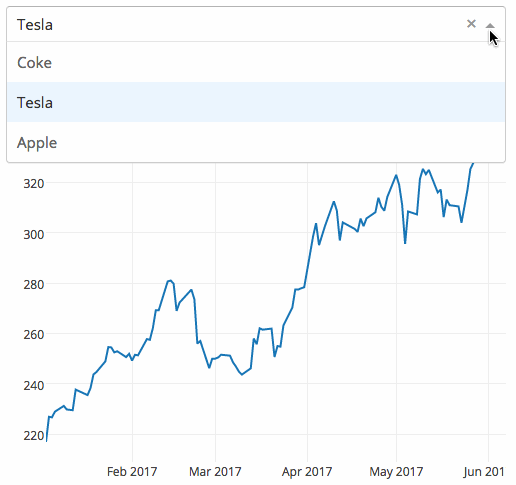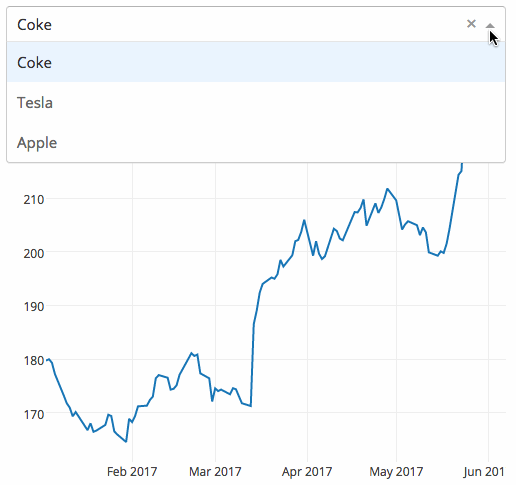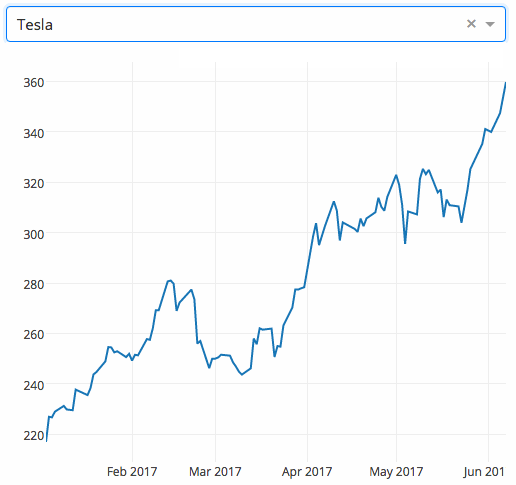
https://github.com/plotly/dash
PyWebIO
同样是一个非常优秀的 Python Web 框架,在不需要编写前端代码的情况下就可以完成整个 Web 页面的搭建,实在是方便。
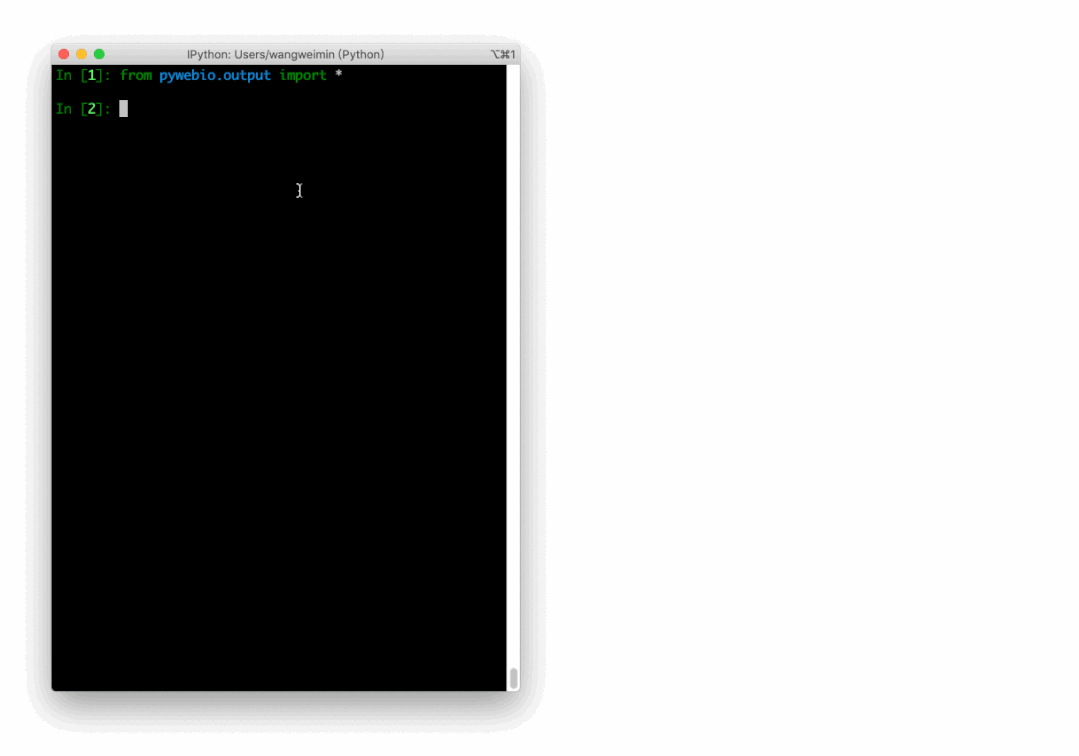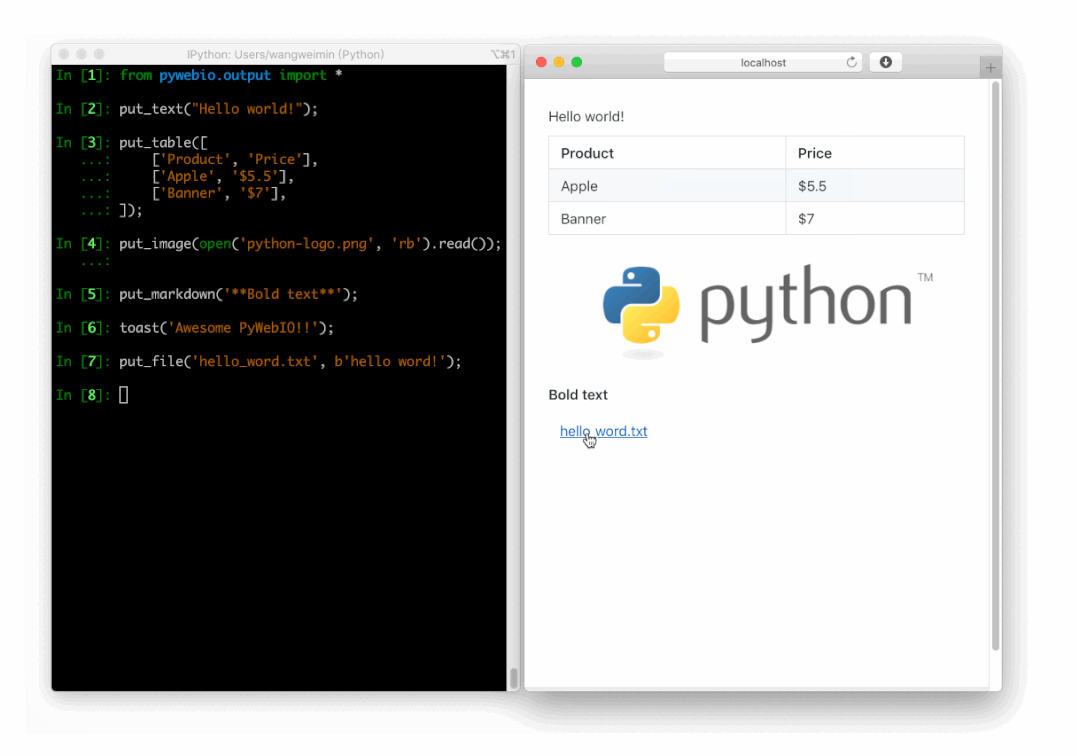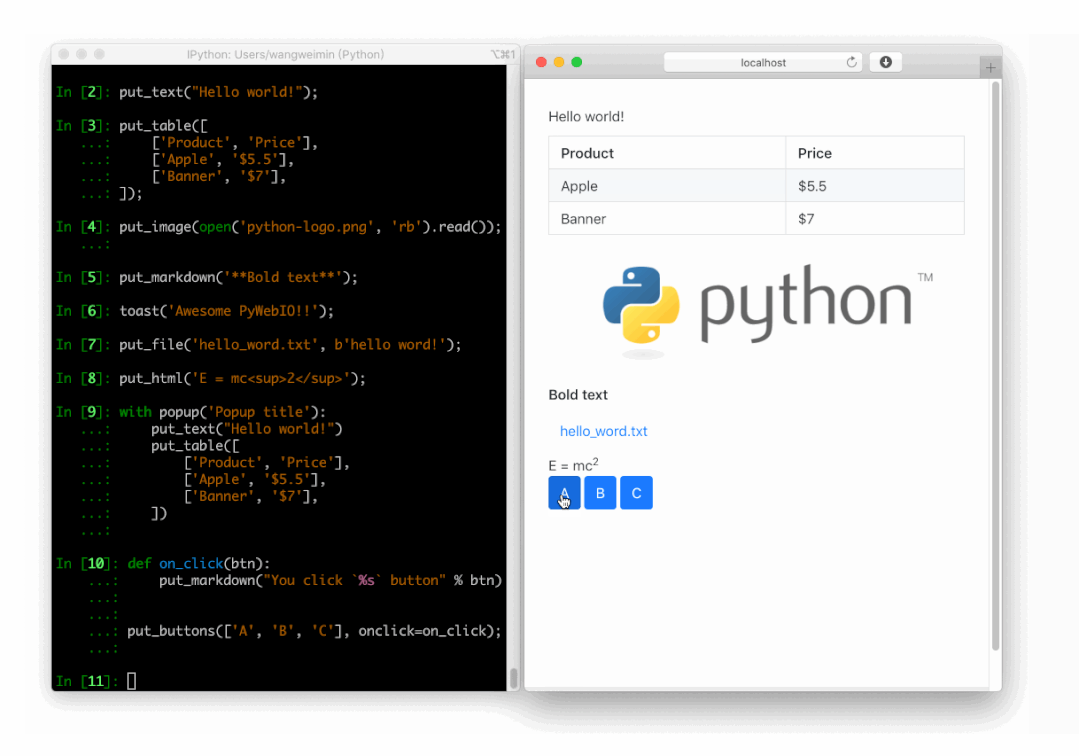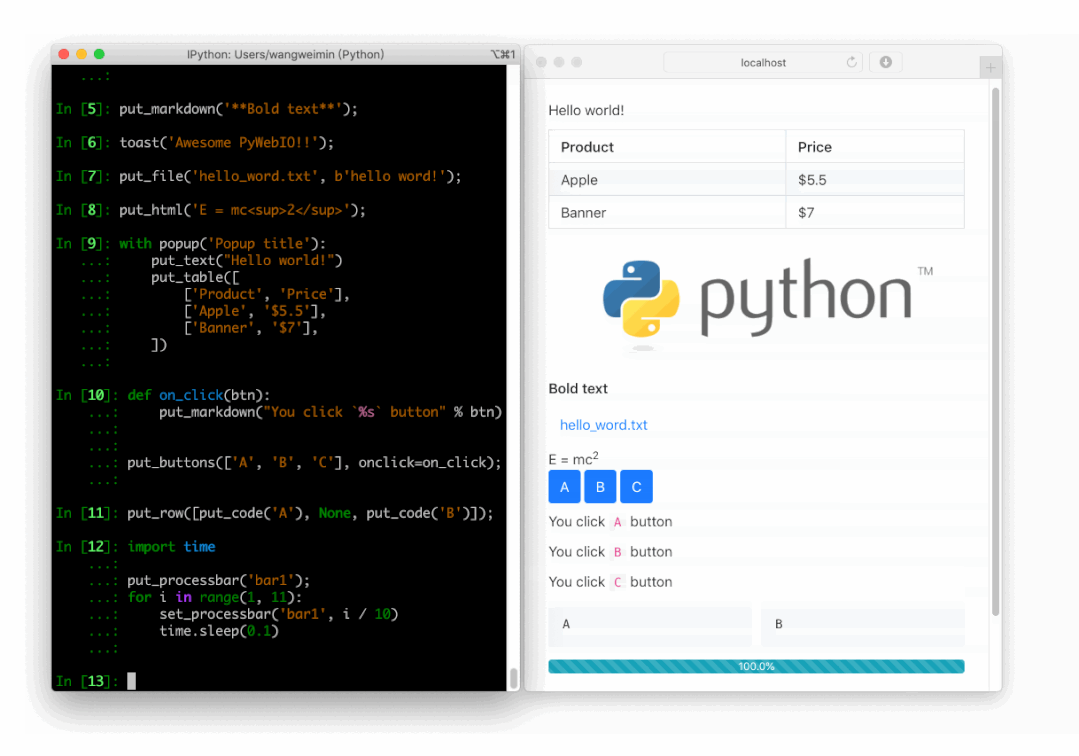
https://github.com/pywebio/PyWebIO
Python 教程
practical-python
一个人气超高的 Python 学习资源项目,是 MarkDown 格式的教程,非常友好。
https://github.com/dabeaz-course/practical-python
learn-python3
一个 Python3 的教程,该教程采用 Jupyter notebooks 形式,便于运行和阅读。并且还包含了练习题,对新手友好。
https://github.com/jerry-git/learn-python3
python-guide
Requests 库的作者——kennethreitz,写的 Python 入门教程。不单单是语法层面的,涵盖项目结构、代码风格,进阶、工具等方方面面。一起在教程中领略大神的风采吧~
https://github.com/realpython/python-guide
其他
pytools
这是一位大神编写的类似工具集的项目,里面包含了众多有趣的小工具。
截图只是冰山一角,全貌需要大家自行探索了
import random
from pytools import pytools
tool_client = pytools.pytools()
all_supports = tool_client.getallsupported()
tool_client.execute(random.choice(list(all_supports.values())))
https://github.com/CharlesPikachu/pytools
amazing-qr
可以生成动态、彩色、各式各样的二维码,真是个有趣的库。
#3 -n, -d amzqr https://github.com -n github_qr.jpg -d .../paths/
https://github.com/x-hw/amazing-qr
sh
sh 是一个成熟的,用于替代 subprocess 的库,它允许我们调用任何程序,看起来它就是一个函数一样。
$> ./run.sh FunctionalTests.test_unicode_arg
https://github.com/amoffat/sh
tqdm
强大、快速、易扩展的 Python 进度条库。
from tqdm import tqdm
for i in tqdm(range(10000)):
...
https://github.com/tqdm/tqdm
loguru
一个让 Python 记录日志变得简单的库。
from loguru import logger
logger.debug("That's it, beautiful and simple logging!")
https://github.com/Delgan/loguru
click
Python 的第三方库,用于快速创建命令行。支持装饰器方式调用、多种参数类型、自动生成帮助信息等。
import click
@click.command()
@click.option("--count", default=1, help="Number of greetings.")
@click.option("--name", prompt="Your name", help="The person to greet.")
def hello(count, name):
"""Simple program that greets NAME for a total of COUNT times."""
for _ in range(count):
click.echo(f"Hello, {name}!")
if __name__ == '__main__':
hello()
Output:
$ python hello.py --count=3
Your name: Click
Hello, Click!
Hello, Click!
Hello, Click!
KeymouseGo
Python 实现的精简绿色版按键精灵,记录用户的鼠标、键盘操作,自动执行之前记录的操作,可设定执行的次数。在进行某些简单、单调重复的操作时,使用该软件可以十分省事儿。只需要录制一遍,剩下的交给 KeymouseGo 来做就可以了。
https://github.com/taojy123/KeymouseGo
好了,这就是今天分享的全部内容,喜欢就点个赞吧~
技术交流
源码、数据、技术交流提升,均可加交流群获取,群友已超过2000人,添加时最好的备注方式为:来源+兴趣方向,方便找到志同道合的朋友
方式①、添加微信号:dkl88191,备注:来自CSDN +研究方向
方式②、微信搜索公众号:Python学习与数据挖掘,后台回复:加群