图对比学习的应用(NCL,SimGRACE,ClusterSCL)
博主以往已经整理过图神经网络用于推荐系统,整理过对比学习用于推荐系统。
- 图神经网络用于推荐系统问题(PinSage,EGES,SR-GNN)
- 图神经网络用于推荐系统问题(NGCF,LightGCN)
- 图神经网络用于推荐系统问题(IMP-GCN,LR-GCN)
- 图神经网络用于推荐系统问题(SURGE,GMCF,TASRec,MixGCF)
- 对比学习用于推荐系统问题(SSL,S^3-Rec,SGL,DHCN,SEMI,MMCLR)
- 自监督学习用于推荐系统问题综述
而图+对比学习结合的趋势也算较为明显。本期先整理几篇WWW22的文章,SIGIR22的文章预计等文章陆续放出后补。
Improving Graph Collaborative Filtering with Neighborhood-enriched Contrastive Learning
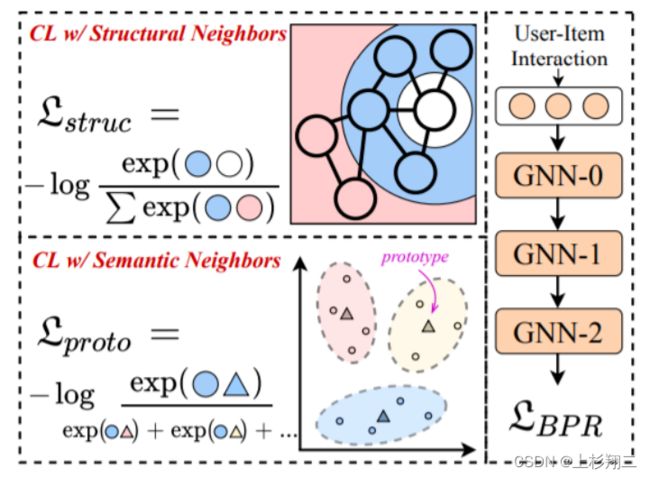
对比学习可以缓解推荐系统中数据稀疏问题,图方法可以考虑邻域节点之间的关系,两者都对协同过滤有提升效果。因此,图+对比学习是很合适的建模思路。这篇文章提出NCL(Neighborhood-enriched Contrastive Learning)方法,主要从两方面考虑对比关系,
- 考虑图结构上的用户-用户邻居,商品-商品邻居的对比关系。—>结构邻居
- 考虑节点表征聚类,节点与聚类中心构成对比关系。—>语义邻居
模型图如上图所示,即同时考虑Structural Neighbors和Semantic Neighbors。
- 结构邻居的对比学习。可以显式挖掘由交互图定义的邻居。具体做法是将用户自己的embedding和偶数层 GNN 的相应输出的embedding视为正例对来进行对比。但由于结构对比损失平等地对待用户/商品的同质邻居,这不可避免地将噪声信息引入对比对。因此作者提出结合语义邻居来扩展对比对。
- 语义邻居的对比学习。这里的语义邻居是指图上无法到达但具有相似特征(商品节点)或偏好(用户节点)的节点。具体的做法是,先通过聚类,将相似embedding对应的节点划分的相同的簇,用簇中心代表这个簇,即原型簇。然后和结构邻居的做法类似,构建语义邻域level上的对比损失。
def ProtoNCE_loss(self, node_embedding, user, item): #原型NCE loss的计算
user_embeddings_all, item_embeddings_all = torch.split(node_embedding, [self.n_users, self.n_items]) #user和item的embedding
user_embeddings = user_embeddings_all[user] # [B, e]
norm_user_embeddings = F.normalize(user_embeddings)
user2cluster = self.user_2cluster[user] # [B,],user聚类,如kmeans
user2centroids = self.user_centroids[user2cluster] # [B, e],聚类中心
pos_score_user = torch.mul(norm_user_embeddings, user2centroids).sum(dim=1) #正例分数,和聚类中心的相似度
pos_score_user = torch.exp(pos_score_user / self.ssl_temp)
ttl_score_user = torch.matmul(norm_user_embeddings, self.user_centroids.transpose(0, 1)) #所有的分数
ttl_score_user = torch.exp(ttl_score_user / self.ssl_temp).sum(dim=1)
proto_nce_loss_user = -torch.log(pos_score_user / ttl_score_user).sum()
item_embeddings = item_embeddings_all[item]
norm_item_embeddings = F.normalize(item_embeddings)
item2cluster = self.item_2cluster[item] # [B, ],item聚类,如kmeans
item2centroids = self.item_centroids[item2cluster] # [B, e],聚类中心
pos_score_item = torch.mul(norm_item_embeddings, item2centroids).sum(dim=1) #和user的操作类似
pos_score_item = torch.exp(pos_score_item / self.ssl_temp)
ttl_score_item = torch.matmul(norm_item_embeddings, self.item_centroids.transpose(0, 1))
ttl_score_item = torch.exp(ttl_score_item / self.ssl_temp).sum(dim=1)
proto_nce_loss_item = -torch.log(pos_score_item / ttl_score_item).sum()
proto_nce_loss = self.proto_reg * (proto_nce_loss_user + proto_nce_loss_item)
return proto_nce_loss
paper:https://arxiv.53yu.com/pdf/2202.06200.pdf
code:https://github.com/RUCAIBox/NCL
SimGRACE: A Simple Framework for Graph Contrastive Learning without Data Augmentation
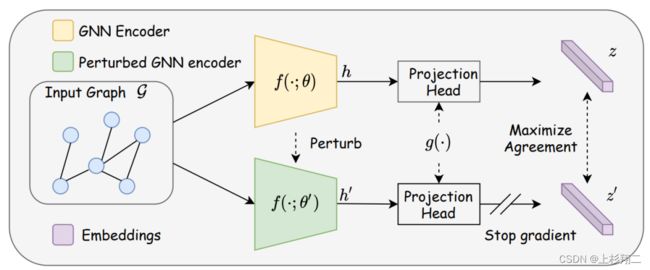
无需数据增强的图对比学习的框架。文章的motivation源于现有的对比学习方法都在数据增强上下各种功夫,但这些数据增强方法主要存在以下问题:
- 鉴于图数据的多样性,在增强过程中很难很好地保留语义。
- 需要手动试错、繁琐的搜索或昂贵的领域知识。
因此作者提出不如直接将原始图作为输入,再加上带有扰动版本的 GNN 模型作为两个编码器,以获得两个相关视图进行对比,如上图所示的GNN Encoder和perturbed GNN Encoder。其中扰动可以按照, h = f ( G ; θ ) , h ′ = f ( G ; θ ′ ) h=f(G;\theta),h'=f(G;\theta') h=f(G;θ),h′=f(G;θ′) θ l ′ = θ l + η ⋅ Δ θ l ; Δ θ l N ( 0 , σ l 2 ) \theta'_l=\theta_l+\eta \cdot \Delta \theta_l;\Delta \theta_l ~ N(0,\sigma^2_l) θl′=θl+η⋅Δθl;Δθl N(0,σl2)
同时作者给出了大量的理论证明。不过实际上,这篇文章的思路和陈丹器大佬在做句子表征,即SimCSE模型中的做法是很类似的,即认为alignment and uniformity是对比学习中重要的两个方面。
paper:https://dl.acm.org/doi/10.1145/3485447.3512156
code:https://github.com/junxia97/SimGRACE
ClusterSCL: Cluster-Aware Supervised Contrastive Learning on Graphs
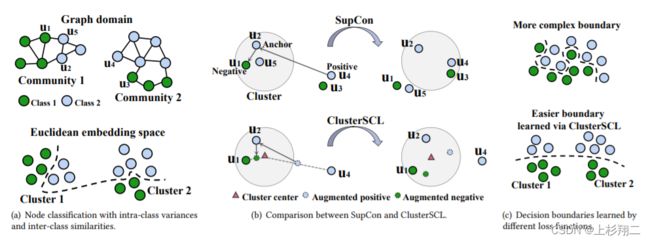
这一篇文章也是认为监督性对比学习存在问题,如上图:
- 难以处理具有较大类内方差的数据集。
- 难以处理高类间相似性的数据集。
如图a,(u1, u3) 或 (u2, u4) 属于同一类,但位于不同的图社区中。而 (u1, u2) 或 (u3, u4) 属于不同的类别,但具有相似的结构模式。但现有的监督对比学习方法SupCon在学习时会打破固有的集群分布,如图b。而作者提出的ClusterSCL 执行节点对比并保留集群分布,且从图c可以看到作者实现了更简单的决策边界。
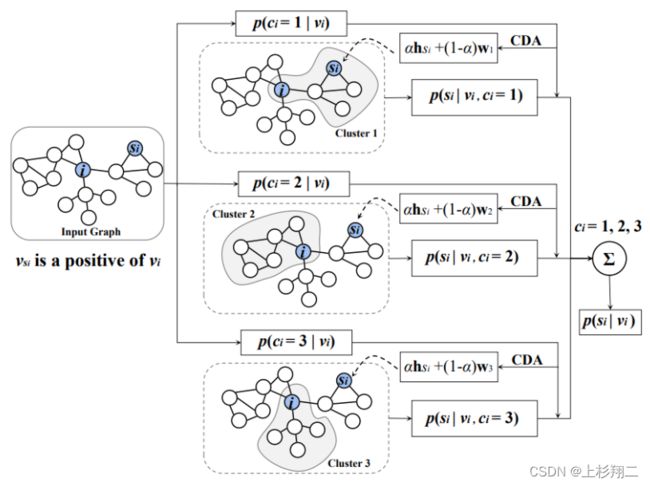
具体来说,作者提出了用于图学习任务的集群感知监督对比学习损失,ClusterSCL 。其主要思想是在监督对比学习期间以节点集群分布的形式保留图的结构和属性属性。即ClusterSCL 引入了集群感知数据增强策略,并将其与监督对比SupCon损失相结合。具体过程如下,是三个隐聚类簇的学习过程。
p ( s i ∣ v i ) = ∫ p ( c i ∣ v i ) p ( s i ∣ v i , c i ) d c i p(s_i|v_i)=\int p(c_i|v_i)p(s_i|v_i,c_i)dc_i p(si∣vi)=∫p(ci∣vi)p(si∣vi,ci)dci
paper:https://dl.acm.org/doi/10.1145/3485447.3512207
code:https://github.com/wyl7/ClusterSCL