EncoderMI: Membership Inference against Pre-trainedEncoders in Contrastive Learning
0.摘要
给定一组未标记的图像或(图像,文本)对,对比学习旨在预训练图像编码器,该编码器可用作许多下游任务的特征提取器。在这项工作中,我们提出了 EncoderMI,这是第一个针对通过对比学习预训练的图像编码器的成员推理方法。特别是,给定输入和对图像编码器的黑盒访问,EncoderMI 旨在推断输入是否在图像编码器的训练数据集中。 EncoderMI 可用于 1) 数据所有者审核其(公共)数据是否在未经其授权的情况下用于预训练图像编码器,或 2) 攻击者破坏私有/敏感训练数据的隐私。我们的 EncoderMI 利用图像编码器对其训练数据的过度拟合。特别是,过度拟合的图像编码器更有可能为其训练数据集中(或不在)的输入的两个增强版本输出更多(或更少)相似的特征向量。我们在自己从多个数据集上预训练的图像编码器,以及对比语言图像预训练 (CLIP) 图像编码器上评估 EncoderMI,后者在从互联网收集,并由 OpenAI 发布的 4 亿(图像、文本)对上进行了预训练。我们的结果表明,EncoderMI 可以实现高准确度、精确度和召回率。我们还探索了一种通过提前停止防止过度拟合来对抗 EncoderMI 的对策。我们的结果表明,它在 EncoderMI 的准确性和图像编码器的实用性之间实现了权衡,即它可以降低 EncoderMI 的准确性,但也会导致基于图像编码器构建的下游分类器的分类精度损失。
1.介绍
对比学习是一种很有前途的通用人工智能方法。特别是,给定图像或(图像,文本)对的未标记数据集(称为预训练数据集),对比学习预训练图像编码器,该图像编码器可用作许多下游任务的特征提取器。给定图像编码器,下游任务只需要少量或不需要标记的训练数据。然而,编码器的预训练通常会消耗大量数据和计算资源。因此,通常情况下,强大的编码器提供商(例如 OpenAI、谷歌)会预训练编码器,然后向下游客户(例如资源较少的组织、最终用户)提供服务。
现有的对比学习研究主要集中在如何训练更好的图像编码器,使其在下游任务上取得更好的性能。然而,对比学习的安全性和隐私性在很大程度上尚未得到探索。在这项工作中,我们对通过对比学习预训练的图像编码器进行成员推理进行了首次系统研究。特别是,我们旨在推断输入图像是否在图像编码器的预训练数据集中。如果输入在(或不在)图像编码器的预训练数据集中,则称为图像编码器的成员(或非成员)。
对比学习中的成员推理有两个重要的应用。假设数据所有者在 Internet 上公开他们的图像,例如在 Twitter 上。 AI 公司(例如 OpenAI)在未经数据所有者授权的情况下收集并使用公共数据对图像编码器进行预训练和货币化。这种做法可能会侵犯数据所有者的数据安全。例如,Twitter 要求 Clearview 停止从其网站上获取公共图像用于模型训练; FTC 要求 Ever 删除在未经授权的用户数据上训练的模型。
成员推理的第一个应用是数据所有者可以使用成员推理方法来审核他/她的(公共)数据是否在未经他/她授权的情况下用于预训练图像编码器,尽管成员推理结果可能没有正式的保证。成员推理的第二个应用是,当预训练数据是私有/敏感时,攻击者可以使用它来破坏预训练数据的隐私。例如,医院可以协同使用对比学习来预训练图像编码器,这些图像编码器可以在医院之间共享,以解决各种下游医疗保健任务,例如基于肺部 CT 图像的 COVID-19 测试和皮肤病预测。在这种情况下,预训练数据可能包括敏感的医学图像,一家医院可能会推断出其他医院的图像编码器的敏感成员。
我们的工作:在这项工作中,我们提出了 EncoderMI,这是第一个针对对比学习的成员推理方法。
威胁模型。我们将执行成员推理的实体(例如,数据所有者、攻击者)称为推理者。我们假设推理者可以通过黑盒访问预训练图像编码器(称为目标编码器),这是最困难和最普遍的情况。
推理者旨在推断输入是否在目标编码器的预训练数据集中。图像编码器的预训练依赖于三个关键维度:预训练数据分布、编码器架构和训练算法。换句话说,我们有背景知识的三个维度。推断者可能知道也可能不知道他们中的每一个。因此,我们总共为推断者提供了八种不同类型的背景知识。在我们的方法中,我们假设推理者有一个影子数据集。特别是,如果推理者知道的话,影子数据集可能具有与预训练数据分布相同的分布。否则,我们假设影子数据集与预训练数据集具有不同的分布。此外,如果推断者不知道编码器架构(或训练算法),我们认为推断者可以假设一个并基于假设进行成员推理。
我们的编码器MI。对比学习中的一个重要模块是数据增强。粗略地说,给定一个输入,数据增强模块通过对输入应用一系列随机操作(例如,随机灰度、随机调整裁剪)来创建另一个随机输入(称为增强输入)。我们观察到对比学习本质上旨在预训练图像编码器,以便它为从同一输入创建的两个增强输入输出相似的特征向量。 EncoderMI 基于这一观察。具体来说,当图像编码器过度拟合其预训练数据集时,它可能会为从预训练数据集(或不在)中的输入创建的增强输入,输出更(或更不)相似的特征向量。在 EncoderMI 中,推理者构建一个二元分类器(称为推理分类器)来预测输入是否是目标编码器的成员。粗略地说,如果目标编码器为从输入创建的增强输入生成相似的特征向量,我们的推理分类器就会预测输入是目标编码器的成员。接下来,我们讨论如何构建推理分类器。
给定影子数据集,我们首先将其分成两个子集,即影子成员数据集和影子非成员数据集。然后,我们基于推理器的已知条件使用影子成员数据集预训练编码器(称为影子编码器)(例如,推理者可以采用与预训练目标编码器相同的编码器架构和训练算法,如果他/她知道它们)。给定影子编码器和影子数据集,我们为影子数据集中的每个输入提取成员特征。特别地,给定影子数据集中的输入,我们首先创建 个增强输入(通过用于训练影子编码器的训练算法的数据增强模块),然后使用阴影编码器为每个增强输入生成特征向量,最后使用相似性度量作为输入的成员特征,计算n个特征向量之间的 · ( − 1)/2 成对相似性得分集。鉴于这些成员特征,如果成员特征是从影子成员(或非成员)数据集中的输入创建的,我们通过将成员特征标记为“成员”(或“非成员”)来构建推理训练数据集。给定推理训练数据集,我们构建一个推理分类器来推理目标编码器的成员。我们考虑三种类型的分类器:基于向量的分类器、基于集合的分类器和基于阈值的分类器。给定输入和对目标编码器的黑盒访问,我们首先提取输入的成员特征,然后使用推理分类器来预测输入是否是目标编码器的成员。
评估。为了评估 EncoderMI,我们首先通过我们自己的预训练图像编码器在 CIFAR10、STL10 和 Tiny-ImageNet 数据集上进行实验。我们的实验结果表明,EncoderMI 在所有八种不同类型的背景知识下都可以实现高精度、精确度和召回率。例如,我们基于向量的推理分类器在八种背景知识下在 Tiny-ImageNet 上的准确率可以达到 88.7% - 96.5%。此外,EncoderMI 可以实现更高的准确性,因为推断者可以访问更多的背景知识。我们还应用 EncoderMI 来推断 OpenAI 发布的 CLIP 图像编码器的成员。特别是,我们从 Google 图像搜索和 Flickr 收集了 CLIP 图像编码器的一些潜在成员和基本事实非成员。我们的结果表明,即使推断者不知道 CLIP 图像编码器的预训练数据分布、编码器架构和训练算法,EncoderMI 也是有效的。
对策。当数据所有者使用 EncoderMI 审计数据滥用时,编码器提供者可能会采取针对 EncoderMI 的反制措施来逃避审计。当攻击者使用 EncoderMI 破坏预训练数据隐私时,可以采取反制措施来增强隐私。由于 EncoderMI 利用目标编码器对其训练数据的过度拟合,我们可以利用防止过度拟合的对策。特别是,我们推广了早期停止,这是一种最先进的基于过度拟合预防的对策,用于防止对分类器的成员推理,以减轻对预训练编码器的成员推理。粗略地说,early stopping 的思想是用较少的 epoch 训练目标编码器,以防止过拟合。我们的结果表明,它在 EncoderMI 的准确性和目标编码器的实用性之间实现了权衡。更具体地说,它会降低我们的 EncoderMI 的准确性,但也会导致基于目标编码器构建的下游分类器的分类准确性损失。
总之,我们在这项工作中做出了以下贡献:
• 我们提出了 EncoderMI,第一个针对对比学习的成员推理方法。
• 我们进行了大量实验来评估我们在 CIFAR10、STL10 和 Tiny-ImageNet 数据集上的 EncoderMI。此外,我们将 EncoderMI 应用于 CLIP 的图像编码器。
• 我们评估了针对EncoderMI 的基于早期停止的对策。我们的结果表明,它在 EncoderMI 的准确性和编码器的实用性之间实现了权衡。
2.对比学习的背景
给定大量未标记的图像或(图像,文本)对(称为预训练数据集),对比学习旨在预训练一个神经网络(称为图像编码器),该网络可用作许多下游任务的特征提取器(例如,图像分类)。给定输入图像,预训练图像编码器为其输出特征向量。
2.1 预训练一个编码器
对比学习中的一个重要模块是数据增强。给定一个输入图像,数据增强模块可以通过一系列随机操作(例如随机灰度、随机调整大小裁剪等)创建另一个随机输入(称为增强输入)。增强输入和原始输入具有相同的大小。此外,我们可以使用数据扩充模块为每个输入创建多个扩充输入。粗略地说,对比学习的想法是预训练图像编码器,使其为从相同(或不同)输入创建的两个增强输入输出相似(或不同)的特征向量。对比学习将这种相似性表述为对比损失,图像编码器经过训练将其最小化。接下来,我们介绍三种流行的对比学习算法,即 MoCo 、SimCLR和 CLIP ,以进一步说明对比学习的思想。
MoCo:MoCo 在未标记图像上预训练图像编码器。 MoCo 中包含三个主要模块:图像编码器(表示为ℎ)、动量编码器(表示为ℎ)和字典(表示为Γ)。图像编码器输出输入或增强输入的特征向量。动量编码器与图像编码器具有相同的架构,但与图像编码器相比更新速度要慢得多。给定输入或增强输入,动量编码器也为其输出一个向量。为了与特征向量区别,我们称之为关键向量。字典模块维护一个由动量编码器输出的关键向量队列,用于存储从前几个小批量中的输入创建的增强输入。此外,字典在图像编码器的预训练期间动态更新。
给定 个输入的小批量,MoCo 为小批量中的每个输入创建两个增强输入。两个增强输入分别传递给图像编码器和动量编码器。为简单起见,我们使用 u 和 u 来表示这两个增强输入。给定两个增强输入,图像编码器 ℎ,动量编码器 ℎ 和字典 Γ,MoCo 定义对比损失如下:
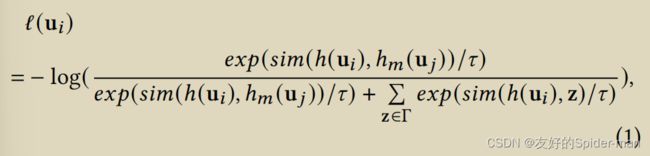
其中是自然指数函数,计算两个向量之间的余弦相似度,代表温度参数。最终的对比损失与对应于 个输入的 个(即 的)增强输入的对比损失ℓ(u)相加。 MoCo 通过最小化最终对比损失来预训练图像编码器。最后,动量编码器为 个增强输入(即 )输出的 个关键向量(即 ℎ (u))被入队到字典中,而N个最老的关键向量批次出列。
SimCLR :与 MoCo 类似,SimCLR 也尝试在未标记图像上预训练图像编码器。给定 个输入的小批量,SimCLR 通过数据扩充为小批量中的每个输入创建两个扩充输入。给定 2 · 个增强输入(表示为 {u1, u2, · · · , u2· }),SimCLR 旨在预训练图像编码器,使其为从相同(或不同)的输入创建的两个增强输入输出相似(或不同)的特征向量。形式上,给定一对从同一输入创建的增强输入 (u, u) ,对比损失定义如下:

其中  是指示函数, 是自然指数函数, 计算两个向量之间的余弦相似度,ℎ 是图像编码器, 是投影头, 是温度参数。最后的对比损失是所有 2· 对增强输入的对比损失 ℓ 的总和,其中每个输入对应于两对增强输入 (u, u) 和 (u, u)。SimCLR 通过最小化最终对比损失来预训练图像编码器。
是指示函数, 是自然指数函数, 计算两个向量之间的余弦相似度,ℎ 是图像编码器, 是投影头, 是温度参数。最后的对比损失是所有 2· 对增强输入的对比损失 ℓ 的总和,其中每个输入对应于两对增强输入 (u, u) 和 (u, u)。SimCLR 通过最小化最终对比损失来预训练图像编码器。
CLIP:CLIP 在未标记(图像、文本)对上联合预训练图像编码器和文本编码器。特别是,文本编码器将文本作为输入并为其输出特征向量。给定一小批 (图像,文本)对,CLIP 从每个输入图像创建一个增强输入图像。对于每个增强输入图像,CLIP 使用增强输入图像和最初与创建增强输入图像的输入图像配对的文本形成正确的(图像,文本)对,并且 CLIP 形成(-1)不正确的对使用增强输入图像和剩余的 ( − 1) 个文本。因此,总共有 个正确对和 · ( −1) 个错误对。 CLIP 联合预训练图像编码器和文本编码器,使得对于正确(或不正确)的(图像,文本)对,图像编码器为增强输入图像输出的特征向量与(或不相似)文本编码器为文本输出的特征向量。
观察:我们观察到这些对比学习算法试图预训练一个图像编码器,该编码器为从相同输入创建的两个增强输入输出相似的特征向量。具体来说,我们可以根据对比损失的定义对 MoCo和 SimCLR 进行观察。对于 CLIP,给定一个(图像,文本)对,图像编码器为图像的增强版本输出的特征向量类似于文本编码器为文本输出的特征向量。因此,图像编码器为从输入图像创建的两个增强输入输出的特征向量是相似的,因为它们都与文本编码器为给定文本输出的特征向量相似。正如我们将在第 4 节中讨论的那样,我们的 EncoderMI 利用这种观察来推断图像编码器预训练数据集的成员。
2.2 训练下游分类器
图像编码器可用作许多下游任务的特征提取器。我们认为这项工作中的下游任务是图像分类。特别是,假设我们有一个带标签的数据集(称为下游数据集)。我们首先使用图像编码器为下游数据集中的输入提取特征向量。然后,我们按照标准的监督学习使用提取的特征向量以及相应的标签来训练分类器(称为下游分类器)。给定来自下游任务的测试输入,我们首先使用图像编码器为其提取特征向量,然后使用下游分类器为提取的特征向量预测标签。预测标签被视为测试输入的预测结果。
3.问题定义
3.1 威胁模型
推理者的目标:给定输入图像 x,推断器旨在推断它是否在图像编码器(称为目标编码器)的预训练数据集中。如果输入在其预训练数据集中,我们将输入称为目标编码器的成员,否则我们将输入称为非成员。推断器的目标是在推断目标编码器的成员/非成员时实现高精度。
推断者的背景知识:我们认为推断者可以通过黑盒访问目标编码器。我们注意到,对于推断者来说,这是最困难和最普遍的情况。一个典型的应用场景是编码器提供商预训练一个编码器,然后向下游客户提供API。编码器的预训练取决于三个关键维度,即预训练数据分布、编码器架构和训练算法(例如,MoCo、SimCLR)。因此,我们沿着这三个维度来刻画推断者的背景知识。
预训练数据分布。该背景知识表征推断者是否知道目标编码器的预训练数据集的分布。特别是,如果推断者知道分布,我们假设他/她可以访问与预训练数据集具有相同分布的影子数据集。否则,我们假设推断者可以访问与预训练数据集具有不同分布的影子数据集。请注意,在这两种情况下,我们都认为影子数据集与预训练数据集没有重叠。为简单起见,我们使用 P 来表示背景知识的这一维度。
编码器架构。推断器可能知道也可能不知道目标编码器的架构。当推断者不知道目标编码器架构时,推断者可以假定一个并基于假定的进行成员推理。例如,当目标编码器使用 ResNet 架构时,推理器在执行成员推理时可能会采用 VGG 架构。我们用 E 来表示背景知识的这个维度。
训练算法。该维度表征推断者是否知道用于训练目标编码器的对比学习算法。当推断者不知道训练算法时,推断者可以根据假设的算法进行隶属度推断。例如,当目标编码器的训练算法是 MoCo时,推断器可以通过假设训练算法是 SimCLR 来执行成员推理。我们用 T 来表示背景知识的这个维度。
我们使用三元组 B = (P, E, T) 来表示推断者背景知识的三个维度。 B 中的每个维度都可以是“是”或“否”,其中一个维度是“是”(或“否”),当相应的背景知识维度对推断者可用(或不可用)时。因此,我们总共有八种不同类型的背景知识。例如,推断器知道预训练数据分布、目标编码器的体系结构和/或当编码器提供者公开它们以增加透明度和信任时的训练算法。
推断器的能力:推理者可以向目标编码器查询任何输入或增强输入的特征向量。
3.2 成员推理
给定推理者的目标、背景知识和能力,我们定义我们的对比学习的成员推理如下:
定义 3.1(对比学习的成员推理)。给定对目标编码器的黑盒访问、背景知识 B = (P, E, T) 和输入,成员推理旨在推断输入是否在目标编码器的预训练数据集中。
4 我们的工作
4.1 概述
回想一下,目标编码器被训练为为预训练数据集中的输入的增强版本输出相似的特征向量。我们的 EncoderMI 基于这一观察。具体来说,当编码器过度拟合其预训练数据集时,编码器可能会输出相似程度更高(或更低)的特征向量,用于从预训练数据集中(或不在)的输入中创建的增强输入。因此,如果目标编码器为输入的增强版本生成相似的特征向量,我们的 EncoderMI 会推断输入是目标编码器的成员。具体来说,在 EncoderMI 中,推理器构建一个二元分类器(称为推理分类器),它根据我们为输入创建的某些特征预测输入的成员/非成员。为了区分目标编码器产生的特征向量,我们将推理分类器使用的特征称为成员特征。基于目标编码器生成的某个输入增强版本的特征向量之间的相似性分数,我们生成此输入的成员特征。构建我们的推理分类器需要一个由已知成员和非成员组成的训练数据集(称为推理训练数据集)。为了构建推理训练数据集,我们将推理者的影子数据集分成两个子集,分别称为影子成员数据集和影子非成员数据集。然后,推断器使用影子成员数据集预训练一个编码器(称为影子编码器)。我们基于影子编码器和影子数据集构建了一个推理训练数据集。具体来说,影子成员(或非成员)数据集中的每个输入都是影子编码器的成员(或非成员),我们基于影子编码器为影子数据集中的每个输入创建成员特征。在基于推理训练数据集构建推理分类器后,我们将其应用于推理目标编码器的成员/非成员。
4.2 构建推理分类器
我们首先介绍如何在阴影数据集上训练阴影编码器。然后,我们讨论如何为输入提取成员特征。最后,我们讨论了如何基于影子编码器和影子数据集构建推理训练数据集,并根据构建的推理训练数据集,讨论如何构建推理分类器。
训练影子编码器:我们的 EncoderMI 的第一步是训练一个影子编码器,其基本事实成员/非成员为推理者所知。为简单起见,我们使用 ![]() 来表示阴影编码器。特别是,推理者将其影子数据集 D 分成两个不重叠的子集:影子成员数据集(表示为
来表示阴影编码器。特别是,推理者将其影子数据集 D 分成两个不重叠的子集:影子成员数据集(表示为 ![]() )和影子非成员数据集(表示为
)和影子非成员数据集(表示为 ![]() )。然后,推理者使用影子成员数据集
)。然后,推理者使用影子成员数据集![]() 预训练影子编码器。如果推理者可以访问目标编码器的架构(或训练算法),则推理者对影子编码器使用相同的架构(或训练算法),否则推理者假定影子编码器的架构(或训练算法)。我们注意到影子成员(或非成员)数据集中的每个输入都是影子编码器的成员(或非成员)。
预训练影子编码器。如果推理者可以访问目标编码器的架构(或训练算法),则推理者对影子编码器使用相同的架构(或训练算法),否则推理者假定影子编码器的架构(或训练算法)。我们注意到影子成员(或非成员)数据集中的每个输入都是影子编码器的成员(或非成员)。
提取成员特征:对于影子数据集中的每个输入,我们基于影子编码器![]() 提取其成员特征。我们的成员特征基于以下关键观察:通过对比学习预训练的编码器(例如,目标编码器、影子编码器)会为编码器预训练数据集中的输入增强版本生成相似的特征向量。因此,给定一个输入 x,我们首先使用用于预训练阴影编码器的训练算法的数据增强模块 A 创建 个增强输入。我们将 个增强输入表示为
提取其成员特征。我们的成员特征基于以下关键观察:通过对比学习预训练的编码器(例如,目标编码器、影子编码器)会为编码器预训练数据集中的输入增强版本生成相似的特征向量。因此,给定一个输入 x,我们首先使用用于预训练阴影编码器的训练算法的数据增强模块 A 创建 个增强输入。我们将 个增强输入表示为  ,
,  , · · · ,
, · · · , 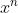 。然后,我们使用影子编码器为每个增强输入生成一个特征向量。我们用
。然后,我们使用影子编码器为每个增强输入生成一个特征向量。我们用 ![]() (
(![]() ) 表示阴影编码器
) 表示阴影编码器 ![]() 为增强输入
为增强输入![]() 生成的特征向量,其中 = 1, 2, · · · , 。对于输入 x 的成员特征由 个特征向量之间的成对相似性分数集组成。正式地,我们有:
生成的特征向量,其中 = 1, 2, · · · , 。对于输入 x 的成员特征由 个特征向量之间的成对相似性分数集组成。正式地,我们有:

其中 M (x, ![]() ) 是我们基于编码器
) 是我们基于编码器![]() 的输入 x 的成员特征, (·, ·) 衡量两个特征向量之间的相似性(例如, (·, ·) 可以是余弦相似性)。请注意,为简单起见,我们省略了 M (x,
的输入 x 的成员特征, (·, ·) 衡量两个特征向量之间的相似性(例如, (·, ·) 可以是余弦相似性)。请注意,为简单起见,我们省略了 M (x, ![]() ) 对 、A 和 的显式依赖。在 M (x,
) 对 、A 和 的显式依赖。在 M (x, ![]() ) 中有 · ( − 1)/2 个相似度分数,如果输入 x 是阴影编码器
) 中有 · ( − 1)/2 个相似度分数,如果输入 x 是阴影编码器![]() 的成员,它们往往会很大。
的成员,它们往往会很大。
构建推理训练数据集:给定影子成员数据集 ![]() 、影子非成员数据集
、影子非成员数据集 ![]() 和影子编码器
和影子编码器![]() ,我们构建推理训练数据集,用于构建推理分类器。特别地,给定输入 x ∈
,我们构建推理训练数据集,用于构建推理分类器。特别地,给定输入 x ∈ ![]() ,我们提取其成员特征 M (x,
,我们提取其成员特征 M (x, ![]() ) 并为其分配标签 1;给定输入 x ∈
) 并为其分配标签 1;给定输入 x ∈ ![]() ,我们提取其成员特征 M (x,
,我们提取其成员特征 M (x, ![]() ) 并为其分配标签 0,其中标签 1 表示“成员”,标签 0 表示“非成员”。形式上,我们的推理训练数据集(表示为 E)如下:
) 并为其分配标签 0,其中标签 1 表示“成员”,标签 0 表示“非成员”。形式上,我们的推理训练数据集(表示为 E)如下:
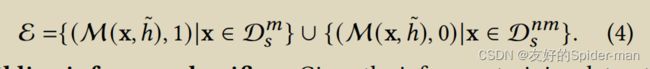
构建推理分类器:给定推理训练数据集  ,我们构建一个二元推理分类器。我们考虑三种类型的分类器,即基于向量的分类器、基于集合的分类器和基于阈值的分类器。这些分类器以不同的方式使用成员特征。接下来,我们一一讨论。
,我们构建一个二元推理分类器。我们考虑三种类型的分类器,即基于向量的分类器、基于集合的分类器和基于阈值的分类器。这些分类器以不同的方式使用成员特征。接下来,我们一一讨论。
基于向量的分类器 (EncoderMI-V)。在基于向量的分类器中,我们将输入的成员特征集 M (x,![]() ) 转换为向量。具体来说,我们将 M (x,
) 转换为向量。具体来说,我们将 M (x, ![]() ) 中的 · ( −1)/2 相似度分数降序排列。我们将排序操作应用于推理训练数据集中每个输入的成员特征。然后,我们按照标准的监督学习程序在上训练基于向量的分类器(例如,完全连接的神经网络)。我们使用
) 中的 · ( −1)/2 相似度分数降序排列。我们将排序操作应用于推理训练数据集中每个输入的成员特征。然后,我们按照标准的监督学习程序在上训练基于向量的分类器(例如,完全连接的神经网络)。我们使用![]() 来表示基于向量的分类器。此外,我们使用 EncoderMI-V 来表示此方法。
来表示基于向量的分类器。此外,我们使用 EncoderMI-V 来表示此方法。
基于集合的分类器 (EncoderMI-S)。在基于集合的分类器中,我们直接对输入的成员特征集合 M (x, ![]() ) 进行操作。特别是,我们基于训练基于集合的分类器(例如 DeepSets)。基于集合的分类器将集合(即 M (x,
) 进行操作。特别是,我们基于训练基于集合的分类器(例如 DeepSets)。基于集合的分类器将集合(即 M (x, ![]() ))作为输入并预测标签 ( 1 或 0)。基于集合的分类器需要是输入集合置换不变的,即预测标签不依赖于集合元素的顺序。因此,基于集合的分类器和基于向量的分类器需要截然不同的神经网络架构。此外,基于集合的分类通常比基于向量的分类更难。为简单起见,我们使用
))作为输入并预测标签 ( 1 或 0)。基于集合的分类器需要是输入集合置换不变的,即预测标签不依赖于集合元素的顺序。因此,基于集合的分类器和基于向量的分类器需要截然不同的神经网络架构。此外,基于集合的分类通常比基于向量的分类更难。为简单起见,我们使用 来表示基于集合的分类器,并使用 EncoderMI-S 来表示此方法。
来表示基于集合的分类器,并使用 EncoderMI-S 来表示此方法。
基于阈值的分类器 (EncoderMI-T)。在基于阈值的分类器中,我们使用输入的 M (x, ![]() ) 中的平均相似度得分来推断其成员资格。特别是,当且仅当其成员特征 M (x,
) 中的平均相似度得分来推断其成员资格。特别是,当且仅当其成员特征 M (x, ![]() ) 的平均相似度得分不小于阈值时,我们基于阈值的分类器才预测输入是成员。关键的挑战是确定基于阈值的分类器在成员推理时实现高精度的阈值。给定一个阈值,我们使用()(或())来表示影子成员(或非成员)数据集中输入的数量,其平均相似性得分在M(x,
) 的平均相似度得分不小于阈值时,我们基于阈值的分类器才预测输入是成员。关键的挑战是确定基于阈值的分类器在成员推理时实现高精度的阈值。给定一个阈值,我们使用()(或())来表示影子成员(或非成员)数据集中输入的数量,其平均相似性得分在M(x,![]() )中小于(或不小于)。阴影数据集的阈值 为时,基于阈值的分类器的准确度为1 − ( () + ()) / |D |。我们的基于阈值的分类器使用最佳阈值 ∗ 最大化这种精度,即使得 () + ()最小化。如果我们将影子成员和影子非成员的平均相似度得分的概率分布绘制为两条曲线,其中 x 轴是平均相似度得分,y 轴是随机影子成员(或非成员)出现的概率有平均相似度得分,那么阈值 ∗ 就是两条曲线的交点。
)中小于(或不小于)。阴影数据集的阈值 为时,基于阈值的分类器的准确度为1 − ( () + ()) / |D |。我们的基于阈值的分类器使用最佳阈值 ∗ 最大化这种精度,即使得 () + ()最小化。如果我们将影子成员和影子非成员的平均相似度得分的概率分布绘制为两条曲线,其中 x 轴是平均相似度得分,y 轴是随机影子成员(或非成员)出现的概率有平均相似度得分,那么阈值 ∗ 就是两条曲线的交点。
Yeom 等人和宋等人利用类似的基于阈值的策略进行成员推理。与我们不同的是,他们的方法是为分类器设计的,并且基于分类器输出的置信度分数。
4.3 推断成员
给定对目标编码器ℎ的黑盒访问和输入x,我们使用推理分类器![]() (或或
(或或 )来预测输入x是否是目标编码器ℎ的成员。算法 1 显示了我们的方法。
)来预测输入x是否是目标编码器ℎ的成员。算法 1 显示了我们的方法。
 给定输入 x、数据增强模块 A 和整数 ,函数 Augmentation 产生 个增强输入。我们使用目标编码器 ℎ 为每个增强输入生成一个特征向量,然后我们计算成对相似性分数集作为输入 x 的成员特征 M (x, ℎ)。最后,我们使用推理分类器根据提取的成员特征来推断输入 x 的成员状态。Ranking 函数按降序排列 M (x, ℎ) 中的相似度分数,而 Average 函数计算 M (x, ℎ) 中相似度分数的平均值。
给定输入 x、数据增强模块 A 和整数 ,函数 Augmentation 产生 个增强输入。我们使用目标编码器 ℎ 为每个增强输入生成一个特征向量,然后我们计算成对相似性分数集作为输入 x 的成员特征 M (x, ℎ)。最后,我们使用推理分类器根据提取的成员特征来推断输入 x 的成员状态。Ranking 函数按降序排列 M (x, ℎ) 中的相似度分数,而 Average 函数计算 M (x, ℎ) 中相似度分数的平均值。
5. 实验
在本节中,我们在对未标记图像进行预训练的图像编码器上评估 EncoderMI。在第 6 节中,我们将 EncoderMI 应用于 CLIP,它在未标记(图像、文本)对上进行了预训练。
5.1 实验设置
数据集:我们在 CIFAR10、STL10 和 Tiny-ImageNet 数据集上进行实验。
• CIFAR10。 CIFAR10 数据集包含来自 10 个对象类别的 60,000 张彩色图像。特别是,数据集包含 50,000 张训练图像和 10,000 张测试图像。每幅图像的大小为 32×32。
• STL10。 STL10 数据集包含来自 10 个类别的 13,000 张带标签的彩色图像。具体来说,数据集分为5000张训练图像和8000张测试图像。我们注意到 STL10 数据集还包含 100,000 张未标记的图像。该数据集中每张图像的大小为 96×96。
• Tiny-ImageNet。 Tiny-ImageNet 数据集包含来自 200 个类别的 100,000 张训练图像和 10,000 张测试图像。每个类有 500 个训练图像和 50 个测试图像。每个图像的大小为 64 × 64。
训练目标编码器:对于 CIFAR10 或 Tiny-ImageNet,我们从其训练数据中随机抽取 10,000 张图像作为预训练数据集来训练目标编码器;对于 STL10,我们从其未标记的数据中直接抽取 10,000 张图像作为预训练数据集。默认情况下,我们使用 ResNet18 作为目标编码器的架构。此外,我们使用 MoCo在预训练数据集上预训练目标编码器。在预训练我们的目标编码器时,我们采用具有默认参数设置的公开可用的 MoCo v1 实现。除非另有说明,否则我们训练目标编码器 1,600 个时期。对于 CIFAR10 或 Tiny-ImageNet,我们将其 10,000 个测试图像视为目标编码器的“非成员”。对于 STL-10,我们将其 5,000 个训练图像和前 5,000 个测试图像视为目标编码器的“非成员”目标编码器。因此,除非另有说明,对于每个目标编码器,我们有 10,000 个基本事实成员和 10,000 个基本事实非成员。
训练影子编码器:在推断器知道目标编码器的预训练数据分布的场景下,我们从相应数据集的训练或未标记数据中随机抽取 20,000 张图像作为影子数据集。在inferrer不知道预训练数据分布的场景下,当预训练数据集来自STL-10时,我们从CI FAR10的训练数据中随机抽取20,000张图像作为影子数据集,我们随机抽取20,000张当预训练数据集为 CIFAR10 或 Tiny-ImageNet 时,来自 STL-10 未标记数据的图像作为阴影数据集。
我们将影子数据集随机分成两个不相交的集合,即影子成员数据集和影子非成员数据集,每个数据集包含 10,000 张图像。我们使用影子成员数据集训练影子编码器。如果推断者知道目标编码器的架构,我们对影子编码器采用相同的架构(即 ResNet18),否则使用带有批量归一化的 VGG-11 。如果推断者知道用于预训练目标编码器的算法,我们采用相同的训练算法(即 MoCo)来预训练影子编码器,否则采用 SimCLR 。在我们的实验中,我们使用公开可用的实现和两种训练算法的默认参数设置。我们训练每个阴影编码器 1,600 个时期。
构建推理分类器:我们基于影子数据集和影子编码器构建推理分类器。 EncoderMI-V 使用基于向量的推理分类器。我们使用具有两个隐藏层的完全连接的神经网络作为我们的基于向量的分类器。
特别地,两个隐藏层中的神经元数量均为 256。EncoderMI-S 使用基于集合的推理分类器。我们选择 DeepSets [53] 作为我们基于集合的推理分类器。此外,我们在实现中采用了 DeepSets [2] 的公开可用代码。对于基于向量的分类器和基于集合的分类器,我们采用交叉熵作为损失函数,并使用初始学习率为 0.0001 的 Adam 优化器训练 300 个 epoch。请注意,EncoderMI-T 利用基于阈值的分类器,不需要训练。
评估指标:继之前的工作之后,我们采用准确度、精确度和召回率来评估成员推理方法。给定包含目标编码器的真实成员和非成员的评估数据集,方法的准确性是方法正确预测的真实成员/非成员的比率;方法的精度是其预测成员中确实是成员的分数;方法的召回率是通过该方法预测为成员的基本事实成员的分数。
比较方法:现有的成员推理方法 旨在推断分类器或文本嵌入模型的成员。我们将这些方法概括为对比学习设置作为基线方法。特别是,我们将我们的方法与以下五种基线方法进行比较,其中前三种用于下游分类器,而后两种用于编码器。
基线-A。目标编码器用于为下游任务训练下游分类器。因此,在这种基线方法中,我们使用目标编码器为下游任务训练下游分类器(称为目标下游分类器),然后我们将现有的成员推理方法应用于目标下游分类器。特别是,我们将 CIFAR10 视为下游任务,我们随机抽取 10,000 个其训练示例作为下游数据集。下游数据集与预训练数据集和影子数据集没有重叠。给定阴影编码器和下游数据集,我们通过使用阴影编码器作为特征提取器来训练下游分类器(称为阴影下游分类器)。我们查询影子下游分类器输出的影子成员(或非成员)数据集中每个输入的置信度得分向量,并将其标记为“成员”(或“非成员”)。给定这些置信度得分向量以及相应的标签,我们训练了一个基于向量的推理分类器。对于给定的输入,我们首先查询目标下游分类器输出的置信度得分向量,然后使用推理分类器预测它是否是目标编码器的成员。请注意,在之前的工作之后,我们对输入的置信度分数进行排名,这优于未排名的置信度分数。
基线-B。 Choquette-Choo 等人提出了对分类器的仅标签成员推理。粗略地说,他们基于输入的一些增强版本为输入构建一个二进制特征向量。当且仅当相应的增强版本被目标分类器正确预测时,特征向量的条目为 1。这种仅标签成员推理方法需要输入的基本事实标签。预训练数据在对比学习中没有标记,使得该方法在实践中不适用于推断编码器的成员。然而,由于预训练数据 CIFAR10 和 Tiny-ImageNet 在我们的实验中具有真实标签,我们假设推断者知道它们并且我们评估仅标签方法。请注意,当预训练数据集来自 STL10 时,我们无法评估此方法,因为它们未标记。与 Baseline-A 类似,我们还将此方法应用于目标下游分类器以推断目标编码器的成员。对于影子数据集中的每个输入 x,我们创建 增加了 puts。此外,我们使用阴影下游分类器来预测 x 的标签和每个增强输入。我们构造一个二元向量 (0, 1, 2, · · · , ) 作为 x 的隶属特征,其中 0 = 1(或 = 1)当且仅当影子下游分类器正确预测 x 的标签(或第 个增广输入),其中 = 1, 2, · · · , 。如果输入在影子成员(或非成员)数据集中,我们将输入的成员特征标记为“成员”(或“非成员”)。给定成员特征及其标签,我们训练了一个基于向量的推理分类器。然后,我们使用推理分类器通过目标下游分类器推理目标编码器的成员。我们在实验中设置 = 10。
基线-C。宋等。 [48] 开发了针对分类器的基于对抗样本的成员推理方法。具体来说,他们利用目标分类器为从输入制作的对抗性示例产生的置信度分数来推断输入是否在目标分类器的训练数据集中。例如,他们基于目标对抗样本的方法(在 [48] 的第 3.3.1 节中讨论)首先为输入制作 − 1 个目标对抗样本(每个标签的目标对抗样本不是输入的真实标签) ), 然后使用目标分类器计算它们每个的置信度分数,最后将置信度分数连接为输入的成员特征,其中 是目标分类器中的类数。他们为目标分类器的每一类训练一个推理分类器,并使用与输入的真实标签相对应的推理分类器来推断其成员资格。输入的对抗性示例可以被视为输入的增强版本。因此,我们在实验中考虑了这些方法。我们注意到,这些方法需要输入的真实标签,而真实标签是下游分类器的一类。然而,在对比学习中,预训练数据通常没有标签。此外,即使预训练数据有标签,它们的标签也可能与下游分类器的标签不同。因此,我们将基于目标对抗示例的方法应用于我们设置中的下游分类器。具体来说,给定输入 x,我们使用 PGD [33] 基于影子下游分类器生成 得到的对抗样本,其中 是影子下游分类器的类数。然后,我们获得影子下游分类器为 目标对抗样本输出的 置信度得分向量,并将它们连接为 x 的成员特征。最后,我们根据影子数据集中输入的成员特征训练一个基于向量的推理分类器,并将其应用于通过目标下游分类器推理目标编码器的成员。此外,在 [48] 之后,我们在生成目标对抗样本时将扰动预算(即)设置为 8/255。
基线-D。在这种基线方法中,我们认为推断器将目标编码器视为分类器。换句话说,推断器将目标编码器为输入输出的特征向量视为分类器输出的置信度得分向量。因此,我们可以应用基于置信度得分向量的方法 [42、44] 来推断目标编码器的成员。具体来说,给定一个阴影编码器,我们使用它为相应阴影数据集中的每个输入输出一个特征向量。此外,我们将标签“成员”(或“非成员”)分配给影子成员(或非成员)数据集中输入的特征向量。然后,我们使用特征向量及其标签训练基于向量的推理分类器。给定目标编码器和输入,我们首先获得目标编码器为输入生成的特征向量。
然后,基于特征向量,推理分类器预测输入是目标编码器的成员还是非成员。
基线-E。宋等。 [46] 研究了文本域中嵌入模型的成员推理。他们的方法可以用来推断一个句子是否在文本嵌入模型的训练数据集中。特别是,他们使用中心词和句子中每个剩余词的嵌入向量之间的平均余弦相似度来推断句子的隶属关系。我们将此方法扩展到我们的设置。具体来说,我们可以将图像视为一个“句子”,将图像的每个补丁视为一个“词”。然后,我们可以使用图像编码器为每个补丁生成一个特征向量。我们将中心补丁视为中心词,并计算其与每个剩余补丁的余弦相似度。最后,我们使用平均相似度得分来推断原始图像的隶属度。具体来说,如果平均相似度得分大于阈值,则图像被预测为成员。与我们的 EncoderMI-T 类似,我们使用影子数据集来确定最佳阈值,即我们使用在影子数据集上实现最大推理精度的阈值。在我们的实验中,我们将图像均匀地分成 3 × 1(即 3)、3 × 3(即 9)或 3 × 5(即 15)个不相交的块。我们发现 3 × 3 的性能最好,所以我们将在正文中显示 3 × 3 的结果,并将 3 × 1 和 3 × 5 的结果推迟到附录中。
 参数设置:我们为我们的方法采用以下默认参数:我们设置 = 10,我们采用余弦相似度作为我们的相似度度量,因为所有对比学习算法都使用余弦相似度来衡量两个特征向量之间的相似度。默认情况下,我们假设推断器知道目标编码器的预训练数据分布、编码器架构和训练算法。除非另有说明,否则我们将 CIFAR10 上的结果显示为预训练数据集。当推断器不知道目标编码器的训练算法时,我们假设推断器在查询目标编码器时仅使用随机调整大小的裁剪来获得输入的增强版本,因为我们发现这种数据增强实现了最佳性能。请注意,我们将 STL10 和 Tiny-ImageNet 中的每个图像调整为 32 × 32 以与 CIFAR10 保持一致。
参数设置:我们为我们的方法采用以下默认参数:我们设置 = 10,我们采用余弦相似度作为我们的相似度度量,因为所有对比学习算法都使用余弦相似度来衡量两个特征向量之间的相似度。默认情况下,我们假设推断器知道目标编码器的预训练数据分布、编码器架构和训练算法。除非另有说明,否则我们将 CIFAR10 上的结果显示为预训练数据集。当推断器不知道目标编码器的训练算法时,我们假设推断器在查询目标编码器时仅使用随机调整大小的裁剪来获得输入的增强版本,因为我们发现这种数据增强实现了最佳性能。请注意,我们将 STL10 和 Tiny-ImageNet 中的每个图像调整为 32 × 32 以与 CIFAR10 保持一致。
5.2 实验结果
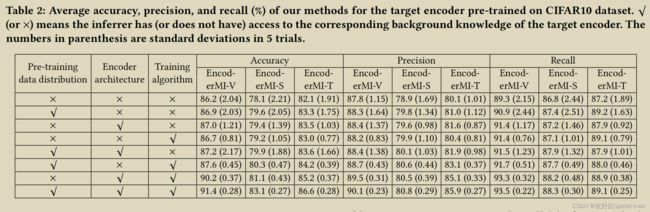
现有的成员推理方法不足:表 1 显示了五种基线方法的准确度、精确度和召回率。请注意,我们考虑的是在我们的威胁模型中具有最强背景知识的推断者,即推断者知道预训练数据分布、编码器架构和训练算法。换句话说,阴影编码器是在背景知识 B = ( √ , √ , √ ) 中训练的。我们发现 Baseline-A、Baseline-B、Baseline-C 和 Baseline-D 的准确率接近 50%,即它们的准确率接近随机猜测,其中输入被预测为概率为 0.5 的成员或非成员。原因是它们旨在推断分类器而不是编码器的成员。置信度得分向量可以捕捉到分类器是否对输入过度拟合,而特征向量本身并不能捕捉到编码器是否对输入过度拟合。因此,这些成员推理方法可以推断分类器的成员,但不能推断编码器的成员。Baseline-E 优于随机猜测。原因是输入的补丁可以看作是输入的增强版本,并且补丁之间的相似性分数在某种程度上捕获了图像编码器的过度拟合。然而,与我们的 EncoderMI 相比,Baseline-E 的准确性仍然很低。
我们的方法是有效的:表 2、5(附录)和 6(附录)显示了我们的方法在 CIFAR10、STL-10 和 Tiny-ImageNet 的 8 种不同类型的背景知识下的准确度、精确度和召回率数据集,分别。结果取五次试验的平均值。首先,我们的方法在所有 8 种不同类型的背景知识下都有效。例如,我们的 EncoderMI-V 在 8 种背景知识下在 Tiny-ImageNet 上的准确率可以达到 88.7% - 96.5%。其次,我们发现在大多数情况下,EncoderMI-V 比 EncoderMI-S 和 EncoderMI-T 更有效。特别是,EncoderMI-V 在大多数情况下比 EncoderMI-S 和 EncoderMI-T 实现更高的准确度(或准确率或召回率)。我们怀疑 EncoderMI-V 优于 EncoderMI-S,因为基于集合的分类通常比基于向量的分类更具挑战性,因此将成员推理视为基于向量的分类问题可以获得更好的推理性能。我们的 EncoderMI-T 可以实现与 EncoderMI-S 相似的准确度、精确度和召回率,这意味着输入图像的平均成对余弦相似度得分已经提供了有关输入成员状态的丰富信息。第三,我们的方法实现了比精确率更高的召回率,即我们的方法将更多的输入预测为成员而不是非成员。
第四,当推断者的背景知识较少时,标准差往往较大。这是因为成员推理在背景知识较少的情况下不太稳定。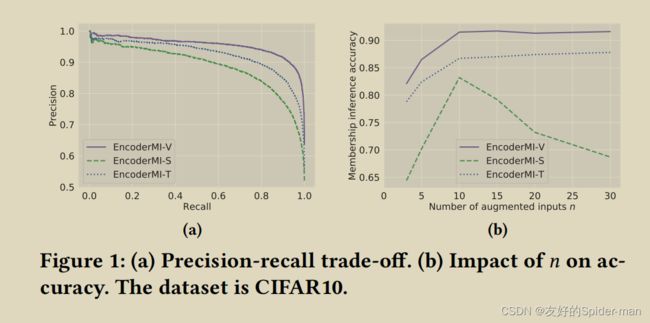
图 1a 显示了我们的三种方法在背景知识 B = ( √ , √ , √ ) 下的精确召回权衡。这些曲线是通过调整三个推理分类器中的分类阈值以产生不同的精度和召回率而获得的。我们的结果表明,随着召回率增加到 0.9 左右,精度略有下降,然后随着召回率的进一步增加而急剧下降。
推断者背景知识的影响:根据表 2、5 和 6,我们对推断者背景知识对我们方法的影响有三个主要观察结果。首先,EncoderMI-V 的准确率更高,因为推断者可以访问更多的背景知识,在大多数情况下,我们对 EncoderMI-S 和 EncoderMI-T 的观察结果相同。
例如,当推断者知道背景知识的所有三个维度时,EncoderMI-V 达到 96.5% 的准确率,而当推断者不知道任何 Tiny-ImageNet 数据集的任何一个时,EncoderMI-V 达到 88.7% 的准确率。其次,在背景知识的三个维度中,训练算法对 STL10 和 Tiny-ImageNet 的信息量最大,而这三个维度对 CIFAR10 的贡献相同。例如,在 Tiny-ImageNet 上,当推断器只能访问训练算法时,EncoderMI-V 达到 94.1% 的准确率,而当推断器只能访问编码器架构和预训练数据分布。对于 CIFAR10,当推断器只能访问三个维度中的任何一个时,EncoderMI-V 的准确率约为 86.8%。第三,编码器架构和预训练数据分布之间没有明显的赢家。例如,单独访问预训练数据分布(即 B = ( √ , ×, ×))比单独访问编码器架构(即 B = (×, √ , ×))获得更高的准确度对于我们在 Tiny-ImageNet 上的所有三种方法,我们在 STL10 上观察到相反的 EncoderMI-V 和 EncoderMI-T。
的影响:图 1b 显示了增强输入 的数量对我们的 CIFAR10 方法准确性的影响,其中推断者的背景知识为 B = ( √ , √ , √ )。我们观察到,对于 EncoderMI-V 和 EncoderMI-T,随着 的增加,精度先增加然后饱和。然而,对于 EncoderMI-S,精度随着 的增加先增加后减少。我们怀疑原因是随着 的增加,成员特征中成对相似性得分的数量呈指数增长,使得基于集合的分类变得更加困难。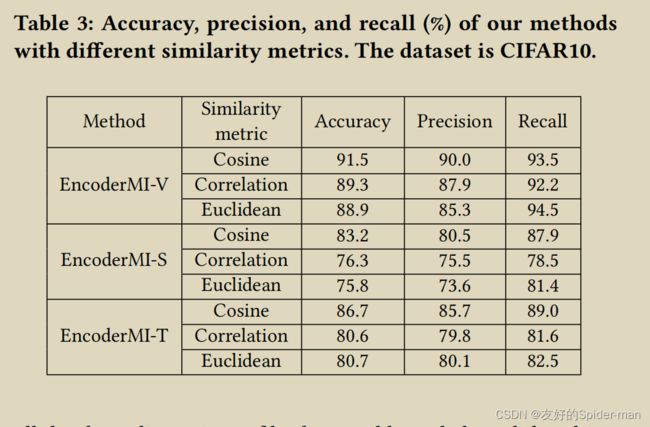 相似性度量的影响:表3显示了相似性度量对我们方法的影响,其中“相关性”是指皮尔逊相关系数。我们从实验结果中得到两个观察结果。首先,余弦相似度度量达到了最高的准确度(或准确率或召回率)。原因是余弦相似度度量也用于目标编码器的预训练。其次,当使用与目标编码器预训练中使用的相似性度量不同的相似性度量时,我们的方法仍然可以实现高精度(或精度或召回率)。
相似性度量的影响:表3显示了相似性度量对我们方法的影响,其中“相关性”是指皮尔逊相关系数。我们从实验结果中得到两个观察结果。首先,余弦相似度度量达到了最高的准确度(或准确率或召回率)。原因是余弦相似度度量也用于目标编码器的预训练。其次,当使用与目标编码器预训练中使用的相似性度量不同的相似性度量时,我们的方法仍然可以实现高精度(或精度或召回率)。
预训练数据集和影子数据集大小的影响:图 2 显示了预训练数据集和影子数据集的大小对我们三种方法的准确性的影响,其中推断者的背景知识为 B = ( √、√、√)。预训练数据集和影子数据集都是从STL10的未标记数据中随机抽取的,但它们没有重叠。请注意,我们在这些实验中没有使用 CIFAR10,因为它的数据集很小,我们无法对大尺寸的不相交的预训练和阴影数据集进行采样。首先,我们观察到我们的方法的准确性随着预训练数据集变小而增加。原因是当目标编码器的尺寸较小时,它更容易过度拟合预训练数据集。其次,我们的方法对影子数据集大小不太敏感。特别是,给定预训练数据集大小,当阴影数据集大小在 5,000 到 25,000 之间时,我们的三种方法中的每一种都达到了相似的精度。我们的结果表明,在各种大小的阴影数据集上预训练的阴影编码器可以在成员推理方面模仿目标编码器的行为。
数据扩充的影响:推断器使用的数据扩充操作可能与用于预训练目标编码器的操作不同。在这个实验中,我们明确地研究了数据扩充的影响。我们假设推断器使用四种常用数据增强操作的综合列表,即随机灰度、随机调整大小裁剪、随机水平翻转和颜色抖动。我们逐渐增加推断者的综合列表和目标编码器之间的重叠数据增强操作的数量。特别是,目标编码器从仅使用数据增强操作高斯模糊开始,这不在推断器的列表中。然后,我们按照以下顺序将推断器的数据增强操作一一添加到目标编码器的预训练模块中:随机灰度、随机调整大小裁剪、随机水平翻转和颜色抖动。我们为每个目标编码器计算下游分类器的成员推理精度和分类精度,其中下游分类器的构建与 Baseline-A 相同。图 3 显示了结果。我们观察到 referrer 和目标编码器之间的重叠数据增强操作的数量控制了成员推理准确性和目标编码器实用性之间的权衡,即目标编码器对成员推理的抵抗力更强,但下游分类器也更少当目标编码器使用引用者综合列表中较少的数据增强操作时准确。
6 将我们的方法应用于CLIP
CLIP 联合对从互联网收集的 4 亿对(图像、文本)图像编码器和文本编码器进行预训练。OpenAI 公开了图像编码器和文本编码器。我们将具有 ViT-B/32 架构的 CLIP 图像编码器视为目标编码器,并应用我们的 EncoderMI 来推断其成员。具体来说,给定一个输入图像,我们的目标是使用 EncoderMI 来推断它是否被 CLIP 使用。接下来,我们首先介绍实验装置,然后展示实验结果。
6.1 实验设置
潜在成员和已知非成员:为了评估我们的 EncoderMI for CLIP 图像编码器,我们需要一个由已知成员和非成员组成的评估数据集。但是,CLIP 的预训练数据集并未对外发布。因此,我们无法获得 CLIP 的已知成员。但是,我们可以收集一些图像,这些图像是 CLIP 预训练数据集的潜在成员和已知非成员。具体来说,根据 Radford 等人的说法。用于预训练 CLIP 的(图像,文本)对是根据一组 500,000 个流行关键字从互联网上收集的。因此,我们收集了以下两个评估数据集,每个数据集有 1,000 个潜在成员和 1,000 个 已知非成员:
• 谷歌。我们使用 CIFAR100 的类名作为关键词,并使用谷歌图像搜索来收集图像。附录 A 显示了类名的完整列表,例如,“clock”、“house”和“bus”。特别是,我们使用公开可用的工具根据关键字从谷歌搜索中抓取图像。我们为每个关键字收集了 10 张图像,因此我们总共收集了 1,000 张图像。我们将这些图像视为潜在成员,因为它们也可能被 CLIP 收集和使用。为了构建真实的非成员,我们进一步使用关键字从谷歌搜索中收集了 2,000 张图像。我们将它们随机分成 1,000 对;对于每一对,我们将两张图片调整为相同大小,并将它们连接起来形成一张新图片,总共有 1,000 张图片。我们将这些图像视为已知非 CLIP 成员。
• Flickr。与上面的谷歌评估数据集类似,我们使用 100 个关键词和一个公开可用的工具从 Flickr 收集了一个评估数据集。具体来说,我们收集了 1,000 张图像作为潜在成员。此外,我们进一步收集了 2,000 张图像并将它们随机配对为 1,000 张图像,我们将其视为已知非成员。
我们承认,在我们的两个评估数据集中,一些潜在成员可能不是 CLIP 的真实成员。对于每个潜在成员和真实非成员,我们将它们的大小调整为 CLIP 的输入大小,即 224 × 224。
推理分类器:我们假设推理者不知道 CLIP 的预训练数据分布、编码器架构和训练算法,这是我们的 EncoderMI 最困难的场景。我们使用我们在第 5 节之前的实验中构建的推理分类器。具体来说,在我们之前的实验中,对于我们的三种方法(即 EncoderMI-V、EncoderMI-S 和 EncoderMI-T)中的每一种以及三种影子中的每一种数据集(即 CIFAR10、STL10 和 Tiny-ImageNet),我们构建了对应于 8 种背景知识的 8 个推理分类器。我们使用前面实验中背景知识B=(√,√,√)对应的推理分类器(即表2、表5、表6最后几行对应的推理分类器)来推理成员剪辑。给定一张输入图像,我们创建 10 个增强输入并使用 CLIP 的图像编码器为每个输入生成一个特征向量。然后,我们计算 10 个特征向量之间的 45 对余弦相似度得分,它们构成了输入图像的成员特征集。我们的推理分类器根据成员特征预测输入图像的成员状态。
6.2 实验结果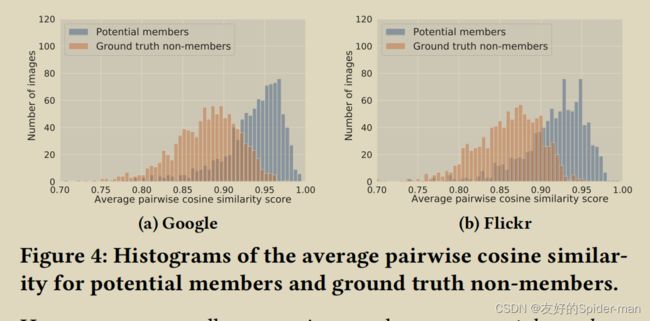
潜在成员和已知非成员的余弦相似度得分分布:回想一下,对于每个潜在成员或已知非成员,EncoderMI 构建由 45 个成对余弦相似度得分组成的成员特征。我们计算每个潜在成员或已知非成员的 45 个成对余弦相似性分数的平均值。图 4 显示了我们两个评估数据集中潜在成员和真实非成员的平均成对余弦相似度得分的直方图。我们观察到潜在成员和已知非成员在平均成对余弦相似性得分方面在统计上是可区分的。特别是,潜在成员往往比地面实况非成员具有更大的平均成对余弦相似性分数。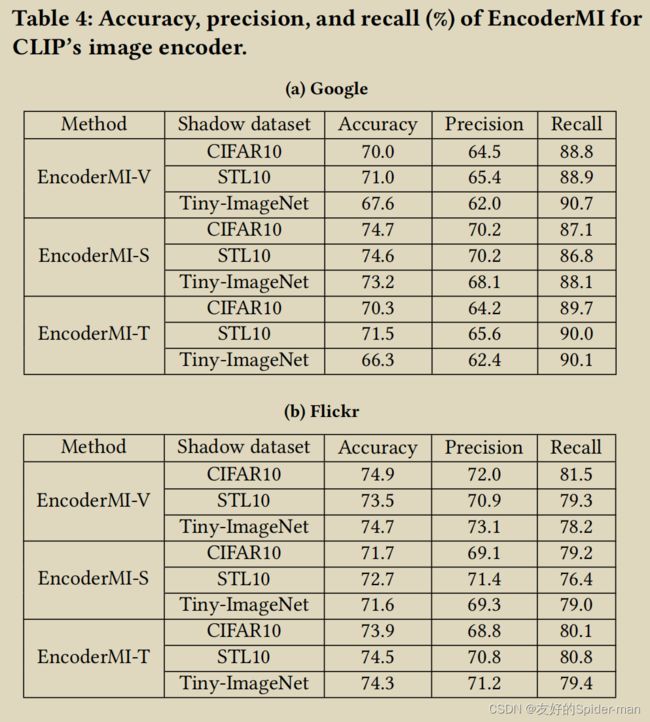
EncoderMI的效率:表 4 显示了 EncoderMI 的三个变体在应用于 CLIP 的图像编码器时基于不同阴影数据集的准确性、精确度和召回率。准确性、精确度和召回率是根据每个评估数据集中的 1,000 个潜在成员和 1,000 个真实非成员计算的。首先,我们观察到基于不同阴影数据集的 EncoderMI 实现了高精度,例如 0.66 – 0.75。我们的结果表明,过拟合存在于现实世界的图像编码器中,例如 CLIP。其次,EncoderMI 实现了比精度更高的召回率,这意味着 EncoderMI 将很大一部分潜在成员预测为成员。第三,与 Flickr 相比,我们的 EncoderMI 在 Google 上的召回率更高(或精度更低)。换句话说,我们的 EncoderMI 预测来自 Google 图像搜索的更多输入作为成员。原因是,平均而言,来自 Google 图像搜索的输入的平均成对余弦相似度得分大于来自 Flickr 的输入,如图 4 所示。
7 关于对策的讨论
通过提前停止防止过度拟合:回想一下,我们的 EncoderMI 利用了目标编码器在其预训练数据集上的过度拟合。请注意,目标编码器对其预训练数据集的过度拟合与分类器的过度拟合不同。例如,当分类器对其训练数据集过度拟合时,它可能在其训练数据集和测试数据集上具有不同的分类精度。此外,分类器为其训练数据集和测试数据集输出的置信度得分向量在统计上也是可区分的。给定一个输入,目标编码器为其输出一个特征向量。然而,特征向量本身并不能捕获目标编码器对输入的过度拟合。相反,当目标编码器过度拟合其预训练数据集时,它可能会为预训练数据集中的输入的增强版本输出更多相似的特征向量。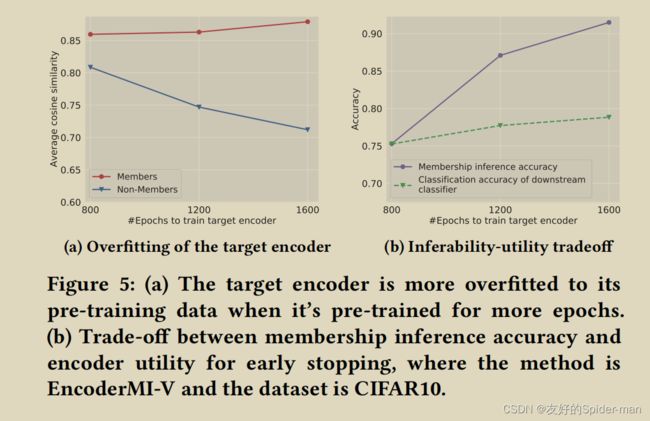
我们发现目标编码器在训练更多epoch时更适合其预训练数据集。回想一下,由我们的 EncoderMI 构造的输入的成员特征由 45 个成对余弦相似度分数组成。对于目标编码器的每个成员或非成员,我们计算其成员特征中的平均成对余弦相似度得分,并且我们进一步计算所有成员(或非成员)的平均成对余弦相似度得分。图 5a 显示了目标编码器成员和非成员的平均成对余弦相似度分数随着预训练时期数量的增加,其中预训练数据集基于 CIFAR10。我们观察到成员(或非成员)的平均成对余弦相似度随着时期数的增加而增加(或减少)。换句话说,目标编码器在预训练更多时期时更适合其预训练数据集。
我们的观察启发我们通过提前停止来防止过度拟合来对抗 EncoderMI,即预训练目标编码器的次数更少。我们针对我们的 EncoderMI 评估了基于提前停止的对策。特别是,我们在基于 CI FAR10 的预训练数据集上预训练目标编码器。在我们对目标编码器进行一些 epoch 的预训练之后,我们计算了我们的 EncoderMI-V 在背景知识 B = ( √ , √ , √ ) 下的准确率,我们还计算了基于目标构建的下游分类器的分类准确率编码器。如第 5 节所述,预训练数据集和下游数据集都是基于 CIFAR10 构建的,下游分类器的分类精度是基于 CIFAR10 的测试数据集计算的。图 5b 显示了我们的 EncoderMI-V 的成员推理精度和下游分类器的分类精度,因为我们对目标编码器进行了更多的预训练。我们观察到基于提前停止的防御实现了权衡,即它降低了成员推理的准确性,但也降低了下游分类器的分类准确性。我们注意到 Song 等人。发现针对分类器的成员推理,提前停止优于其他防止过度拟合的对策,并且他们还观察到提前停止的成员推理准确性和分类器效用之间的权衡。
差分隐私预训练:差分隐私可以为机器学习模型训练数据集中的每个输入提供正式的成员隐私保证。许多差分隐私学习算法已经被提出。这些算法在训练数据、目标函数 或学习过程中通过(随机)梯度下降计算的梯度中添加噪声。例如,阿巴迪等人。提出了差分私有随机梯度下降(DP-SGD),它将随机高斯噪声添加到随机梯度下降计算的梯度中。将这些差异隐私学习算法推广到对比学习将是有趣的未来工作。特别地,当预训练数据集改变一个输入时,差分隐私对比学习算法学习的编码器并没有太大变化。然而,差分隐私也可能会给编码器带来很大的效用损失,即基于差分隐私编码器构建的下游分类器的分类精度可能会低得多。
对抗性学习:已经研究了基于对抗性学习的对策,以减轻对分类器的成员推理,其灵感来自基于对抗性学习的对抗属性推理攻击的对策。例如,Nasr 等人。 [34] 提出在训练目标分类器时向损失函数添加对抗性正则化项,其中对抗性正则化项对成员推理方法的准确性进行建模。贾等。 提出了 MemGuard,它不修改训练过程,而是为每个输入的目标分类器输出的置信度得分向量添加精心设计的扰动。具体来说,这个想法是将扰动的置信度得分向量变成推理分类器的对抗样本,推理分类器根据扰动的置信度得分向量进行随机隶属度推理。将这些对策扩展到预训练的编码器将是有趣的未来工作。例如,我们可以将 EncoderMI 的准确性捕获为对抗性正则化项,并在使用对比学习对编码器进行预训练时将其添加到对比损失中;我们还可以为每个(增强的)输入的编码器输出的特征向量添加精心设计的扰动,这样由我们的 EncoderMI 为输入构建的成员特征集成为推理分类器的对抗样本,这使得随机成员基于扰动成员特征的推理。一个关键的挑战是如何找到对每个特征向量的这种扰动,因为成员特征取决于与输入的增强版本相对应的一组特征向量之间的成对相似性。
8 相关的工作
成员推理:在针对机器学习分类器的成员推理中,推理器旨在推断输入是否在分类器(称为目标分类器)的训练数据集中。例如,在 Shokri 等人提出的方法中。 [44],推断者首先训练影子分类器来模仿目标分类器的行为。给定其基本事实成员和非成员为推理者所知的影子分类器,推理者训练推理分类器,然后将其应用于目标分类器的推理成员。塞勒姆等人。 [42] 通过放宽对推断者的假设进一步改进了这些方法。惠等。 [24] 提出了不需要训练影子分类器的盲目成员推理方法。在我们工作的同时,He 等人。 [22] 还研究了针对对比学习的成员推理。他们假设预训练数据和下游数据相同。具体来说,给定一个带标签的训练数据集,他们首先使用对比学习来预训练编码器,然后用它在带标签的训练数据集上微调分类器。他们试图通过将现有方法 [42、44] 应用于微调分类器来推断输入是否在标记的训练数据集中。
我们的方法与这些方法不同,因为它们旨在推断分类器的成员,而我们的方法旨在推断通过对比学习预训练的编码器的成员。我们的实验结果表明,当应用于推断编码器成员时,这些方法可以达到接近随机猜测的准确性。原因是分类器输出的置信度分数向量可以捕获分类器是否对输入过拟合,而编码器输出的特征向量本身不能捕获编码器是否对输入过拟合。
输入的增强版本的特征向量之间的相似性得分捕获编码器是否对输入过度拟合,我们的方法利用这种相似性得分来推断输入的成员状态。
现有的用于预训练模型 [8, 46] 的成员推理方法侧重于自然语言领域。例如,Carlini 等人。 [8] 提出了 GPT2 [39] 的成员推理方法,这是一种预训练的语言模型,他们进一步利用成员推理方法重建 GPT-2 的训练数据。具体来说,他们首先重建了一些候选文本,然后应用成员推理方法来确定每个候选文本的成员状态。据我们所知,之前没有研究过图像域中编码器的成员推理。
之前的工作 [23, 54] 还研究了针对迁移学习的成员推理。例如,Hidano 等人。 [23] 假设白盒访问教师模型的转移部分,而 Zou 等人。 [54]利用教师模型的后验。我们的工作与这些不同,因为预训练图像编码器不同于训练教师模型,因为前者对未标记数据使用对比学习,而后者对标记数据使用标准监督学习。
针对成员推理的对策:提出了许多对策 [9、29、31、34、42、44、47] 来对抗分类器的成员推理。第一类对策 [42、44、47] 试图在训练分类器时防止过度拟合,例如标准 2 正则化 [44]、dropout [42] 和提前停止 [47]。第二类对策 [7, 43] 基于差分隐私 [15],这通常会给机器学习分类器带来很大的效用损失。第三类对策利用对抗性学习,例如对抗性正则化 [34] 和 MemGuard [29]。我们针对我们的 EncoderMI 探索了一种基于提前停止的对策。我们的结果表明,这种对策在成员推理准确性和编码器的实用性之间实现了权衡。
对比学习:对比学习 [10、13、17、20、37、40、50] 旨在通过利用未标记数据本身中的监督信号,对未标记数据的图像编码器进行预训练。未标记的数据可以是未标记的图像或(图像,文本)对。预训练编码器可用于许多下游任务。对比学习的关键思想是预训练图像编码器,使其为从同一输入图像创建的一对增强输入输出相似的特征向量,并为从不同输入图像创建的一对增强输入输出不同的特征向量。对比学习方法的示例包括我们在第 2 节中讨论的 MoCo [20]、SimCLR [10] 和 CLIP [38]。我们注意到 Jia 等人。 [28] 提出了 BadEncoder,它将后门嵌入到预训练的图像编码器中,使得基于后门编码器构建的多个下游分类器同时继承后门行为。
9 结论和后续工作
在这项工作中,我们提出了第一个针对通过对比学习预训练的图像编码器的成员推理方法。我们的方法利用图像编码器的过度拟合,即它为相同输入的两个增强版本生成更多相似的特征向量。我们自己在多个数据集上预训练的图像编码器以及真实世界图像编码器的实验结果表明,我们的方法可以实现高精度、精确度和召回率。此外,我们还发现基于提前停止的对策实现了成员推理准确性和编码器效用之间的权衡。
未来有趣的工作包括 1) 将我们的方法扩展到白盒设置,其中推理器可以访问目标编码器的参数,2) 扩展我们的方法以推断(图像,文本)对的成员关系,3)针对我们的方法开发新的对策,以及 4)探索预训练图像编码器的其他隐私/保密风险,例如窃取它们的参数 [49] 和超参数(例如,编码器架构)[51]。