python基本语法
1.输出代码到文件上去
fp=open('D:/text1.txt','a+') #a+的意思是如果不存在就创建,如果存在的话就后面继续追加
print("hello world!",file=fp)
fp.close()
2.转移字符
\n 换行
\t 制表符,一组四个字符
\r 回车
\b 退一个格
不希望转义字符起作用,那就在前面加一个r,例如print(r"heeloo\nworld") 它最终输出的是 heeloo\nworld,当然最后一个字符不是是斜杠
3. Unicode的转换
print(chr(0b100111001011000))
print(ord('以'))4.关键字
import keyword
print(keyword.kwlist)5.存储类型

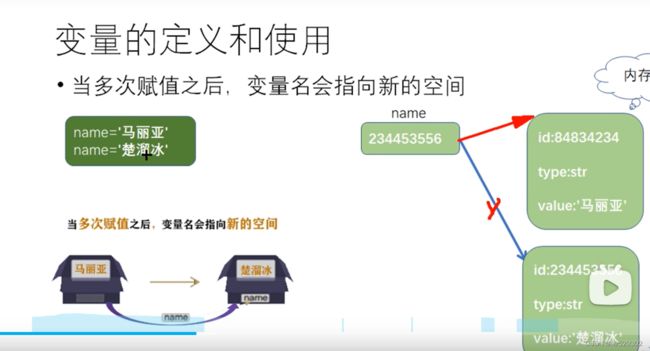
不管什么东西,加上单引号或者双引号就是str字符串类型
布尔类型可以转换为整数,True为1,False为0
三引号单双可以换行,都是为str字符串类型。

6.注释

7.输入函数
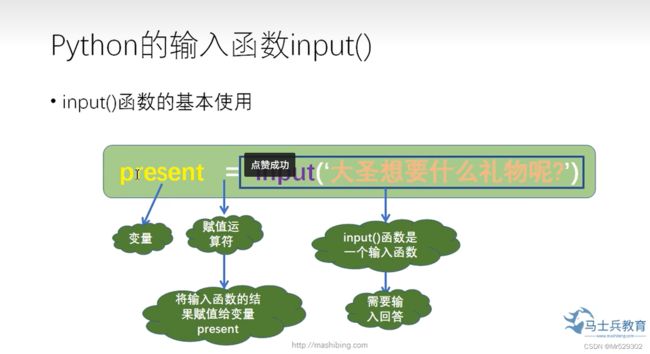
输入的自动为str类型,要进行加减乘除的话得提前进行类型强制转换
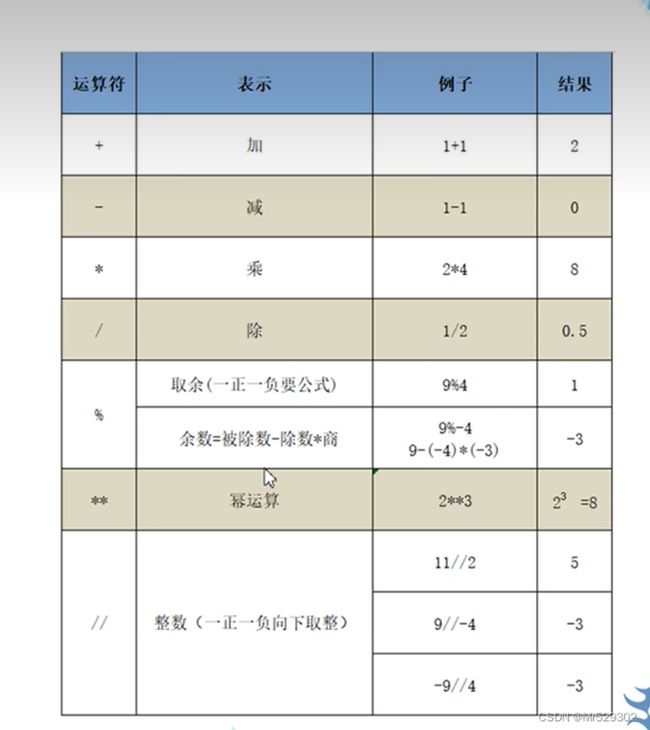
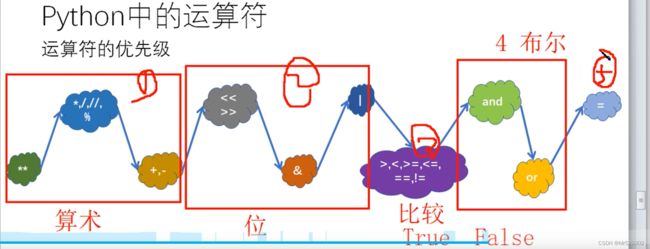
8.运算符
//为整除运输符号,**为多少次方
9.赋值
解包赋值a,b=b,a
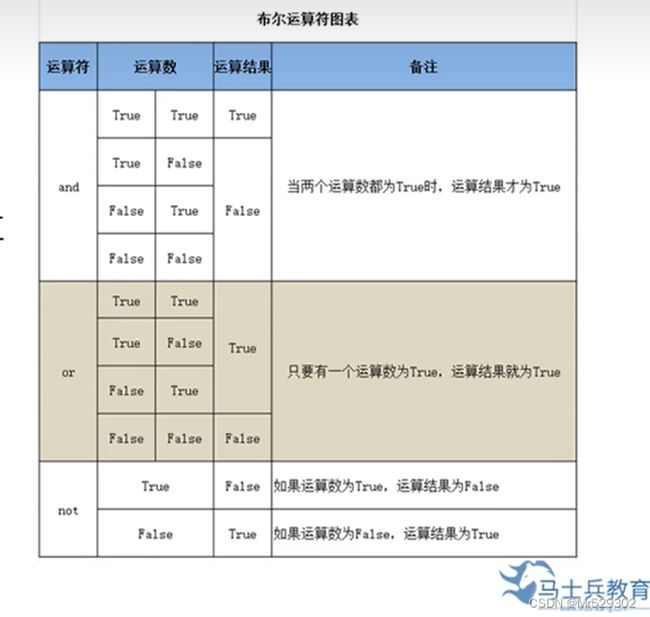
比较运算符若要比较两者的标识也就是地址用is
a is b #标识a的标识与b的一致,当然这是个布尔类型
a is not b

注意一下map函数的用法
10.其他函数


11.列表
format函数,split函数,len函数,CSDN上面自己搜用法
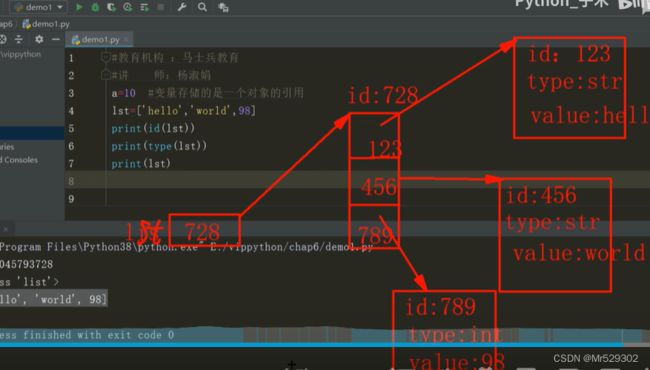
list2=list([1,2,3,4])
print(list2)索引正序是0,逆序是-1,分别对应正数第一和倒数第一



12.列表的增删改查
list1=['hello',23,'gh',56]
list2=['23',56,'aeae']
list1.append(200)
print(list1)
list1.extend(list2)
print(list1)
list1.insert(1,'ajehakejh')
print(list1)
pop()默认删除最后一个元素 ,reverse函数的用法,eval函数的用法
list1=['hello',23,'gh',56,33,44,55,66]
list1.remove(23)
print(list1)
list1.pop()
print(list1)
new_list=list1[1:3]
print(new_list)
list1.clear()
print(list1)
del list1
print(list1)list1=[1,2,3,4,5,6]
list1[0]='heel'
print(list1)
list1[1:3]=['asae','aeaeeqw','fsggdsa','kilt']
print(list1)13.列表的排序
list1=[3,45,21,1,0,69,82,35]
list1.sort(reverse=True)
print(list1)13.列表生成式

list1=[item for item in range(1,10)]
print(list1)14.字典
冒号之前为键,冒号之后为值,所以也叫键值对


score={'张三':99,'李斯':123,'尼玛':56}
print('张三' not in score)
del score['尼玛']
print(score)
score['阿木']=234 #既可以新增,也可以对已有的键进行修改
print(score)
score={'张三':99,'李斯':123,'尼玛':56}
print(score.keys())
print(type(score.keys()))
print(score.values())
print(type(score.values()))
print(list(score.values()))
print(list(score.keys()))
print(score.items())
print(list(score.items())) #转换之后的列表元素由元组组成
score={'张三':99,'李斯':123,'尼玛':56}
for item in score:
print(item,score[item],score.get(item)) 
score={'name':'张三','name':'李斯'}
print(score)
score={'name':'张三','nigername':'李斯'}
print(score)
item=['aea','sadag','asfgg']
score=[12,34,56]
list1=zip(item,score)
print(list(list1))
print({item:score for item,score in zip(item,score)})15.元组
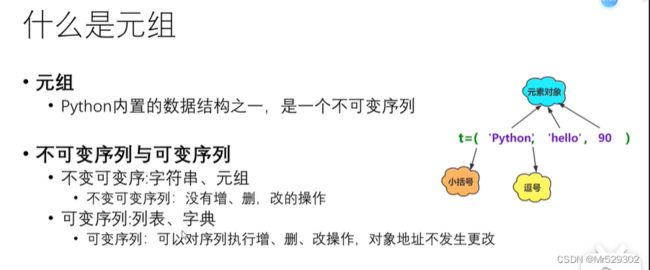

type='ajkelk',235,67.2
sch=(12,)
score=tuple(('aeae',234,56.2))
print(score)
print(type)
print(sch) 

16.集合

s=set(range(6))
print(set([1,2,3,4]))
print(set((1,2,3,4,4,5,5,6)))
print(set('Python'))
print(set({23,3,4,56,78}))
print(set())
#集合本身是无序,且无重复元素的
list1={1,2,3,4,56,7,8}
print(1 in list1)
print('python' not in list1)
list1.add(23)
print(list1)
list1.update({200,300,400})
print(list1)
list1.update((0,-1,-2,-3))
print(list1)
list1.remove(0)
print(list1)
list1.pop() #必须是无参数的
print(list1)

s1={1,2,3,4}
s2={2,3,4,5}
print(s1==s2)
print(s1!=s2)
list1={1,2,3,4,5,6,7,8}
list2={2,3,4,5,6}
list3={2,3,4,5,0}
print(list2.issubset(list1))
print(list3.issubset(list1))
print(list1.issuperset(list2))
print(list3.issuperset(list1))
print(list2.isdisjoint(list1))
print(list3.issuperset(list1))
#没有交集为True,有交集为False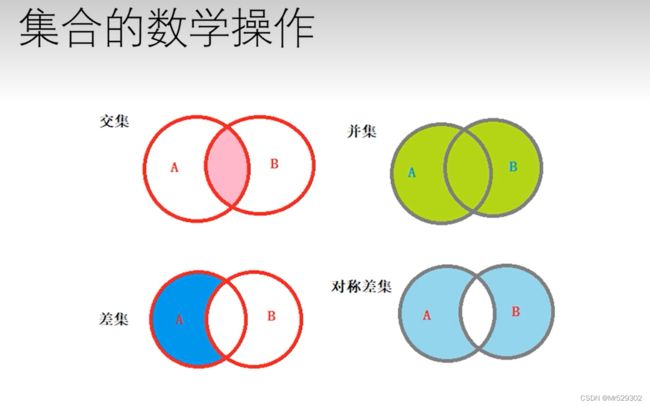
s1={1,2,3,4,5}
s2={3,4,5,6,7}
print(s1.intersection(s2))
print(s1 & s2)
print(s1.union(s2))
print(s1|s2)
print(s1.difference(s2))
print(s2.difference(s1))
print(s1-s2)
print(s1.symmetric_difference(s2))
print(s1^s2) 

17.字符串

a='python'
b="python"
c='''python'''
print(id(a))
print(id(b))
print(id(c)) 


a='python'
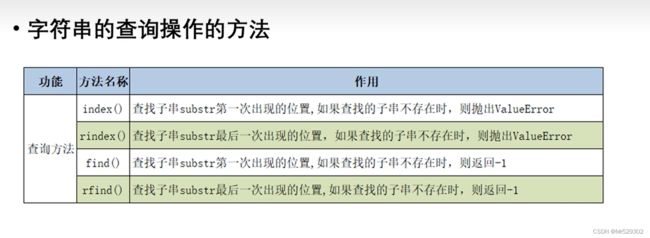
print(a.index('t'))
print(a.find('t'))
print(a.rindex('t'))
print(a.rfind('t'))
print(a.find('k'))
print(a.rfind('k')) 
转换之后,会产生一个新的对象,即地址发生变化

s1='hello,python'
print(s1.center(20,'*'))
print(s1.ljust(20,'*'))
print(s1.rjust(20))
print(s1.zfill(20))
print('-1234'.zfill(10)) 
s1='hello python gih'
print(s1.split(sep='o'))
print(s1.split(sep='o',maxsplit=1))
print(s1.rsplit(maxsplit=1)) 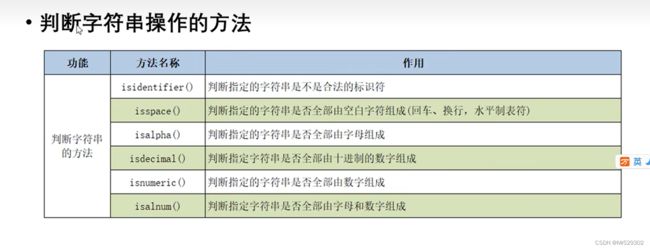
s1='hello,python'
print(s1.isidentifier()) #合法字符是字母,数字,下划线
print('heelo'.isidentifier())
print('1.','\t'.isspace())
print('2.','abc'.isalpha())
print('3.','123'.isdecimal())
print('4.','123456'.isnumeric())
print('5.','23a'.isalnum()) 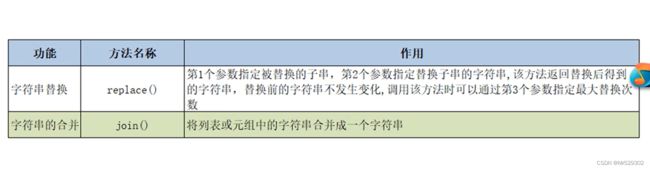
s='人生苦短,我用Python'
s='人生苦短,我用Python Python Python'
print(s.replace('Python','Java',2))
s1=('a','b','c')
s2=['hello','java']
print('*'.join(s2))
print(''.join(s2))
print(''.join(s1)) 
print('apple'>'app')
print(ord('a'))
print(chr(97))
print(ord('汤'))
#is 比较的是内存 == 比较的是Value 
s1='hello,python'
print(s1[:5])
print(s1[6:]) #产生了新的地址
#[:5]是默认到5前面一个元素,而[6:]是包含最后一个元素
print(s1[:5]+'!'+s1[6:])