「推荐系统特征工程」04:数据预处理
作者 | gongyouliu
编辑 | auroral-L
全文共4574字,预计阅读时间35分钟。
大家好,我是强哥。一个热爱暴走、读书、写作的人!
本章目录
一、数值与类别数据的预处理
1. 缺失值处理
2. 标准化
3. 归一化
4. 异常值与数值截断
5. 非线性变换
6. 类不平衡的处理
7. 机器学习范式的调整
二、时空数据的预处理
1. 时间数据
2. 空间数据
三、文本数据的预处理
四、富媒体数据的预处理
总结
特征工程是通过一些数据处理方法和技巧将原始数据转化为适合机器学习算法处理的特征的过程。一般来说,在真实业务场景中,数据一般会存在各种各样的问题,不是直接可以用于构建特征的,在构建特征之前需要对这些数据进行适当的预处理以提升数据的后续处理效率和增强数据的质量,这些处理方法就是本章我们要讲解的数据预处理。概括来说,我们这里指的数据预处理就是将原始数据处理为适合进行特征工程的比较规范的数据格式的过程。
推荐系统中可以使用的数据按照数据类型可以分为数值数据、类别数据、文本数据、时空数据和富媒体数据(图片、音频、视频等)等几种类型,本章我们就按照这种分类来分别讲解数据预处理的方法和技巧。下面我们先说说最常见最重要的数值与类别数据的预处理。
这里提一下,针对数据数据进行预处理之后是可以直接作为特征的,就不需要再进行特征工程了,后面在下一章的特征构建中就不会再详细讲解数值数据的特征构建了。
一、数值与类别数据的预处理
下面我们从7个不同的维度来对数值数据和类别数据的预处理进行说明。下面的表述中没有明确区分哪些预处理方法是适合数值数据的、哪些是适合类别数据的、哪些是两者都适合,读者根据这两类数据的特征自行就可以判定,因此笔者就不赘述。
1. 缺失值处理
实际上我们收集到的很多数据是存在缺失值的,比如某个视频数据缺少演职员信息。对于用户属性数据来说,很多用户可能也不会填写完备的信息(比如用户不填年龄、性别、收入等)。一般缺失值可以用均值、中位数、众数等填充,或者直接将缺失值当做一个特定的值来对待。还可以利用一些复杂的插值方法,如样条插值等来填充缺失值。最极端的一种处理方法是将包含缺失值的样本去掉(如果包含缺失值的样本占总样本的比例不大,这种方法是可行的,否则是不可取的)。在 scikit-learn 数据预处理模块中,Imputer 类为我们提供了插补缺失值的基本策略。
2. 标准化
数据标准化算是最常见的数据预处理方法了。具体来说,数据标准化更多的是指数据的无量纲化。通常情况下,数据的标准化处理是必须而且必要的,因为很多时候我们的原始数据集在不同维度特征的尺度(单位)上并不一致,需要通过标准化处理将其转化成具有相同尺度的数据。
不同特征之间由于量纲不一样,数值可能相差很大,直接将这些差别极大的特征灌入模型,会导致数值小的特征根本不起作用,所以一般我们要对数值特征进行标准化处理,常用的标准化方法有min-max标准化、分位数标准化、正态分布标准化等。下面分别简单介绍。
min-max标准化是通过求得该特征样本的最大值和最小值,采用如下公式来进行标准化,标准化后所有值分布在0-1之间,scikit-learn中preprocessing模块为我们提供了MinMaxScaler类来进行处理。
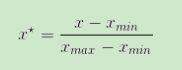
分位数标准化,是将该特征所有的值从小到大排序,假设一共有N个样本,某个值x排在第k位,那么我们用下式来表示x的新值。

正态分布标准化,是通过求出该特征所有样本值的均值和标准差,再采用下式来进行标准化。scikit-learn中preprocessing模块为我们提供了StandardScaler类来进行处理。
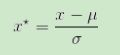
一般来说,如果我们不知道一个变量服从什么分布,假设是正态分布可能是最合适的(毕竟正态分布是宇宙中最本质的一种分布,很多其他分布通过中心极限定理都可以转为正态分布:中心极限定理是概率论中最重要的一类定理,有广泛的实际应用背景,在自然界与生产中,一些现象受到许多相互独立的随机因素的影响,如果每个因素所产生的影响都很微小时,总的影响可以看作是服从正态分布的),所以,我们用正态分布标准化是首选的标准化方法。
3. 归一化
归一化跟标准化不一样的地方是,标准化是对单个特征(即样本特征矩阵的列)进行的操作,而归一化是对行进行的操作(即对样本进行的操作),就是采用某种范数(比如L2范数),让整行的范数为1,假设样本中的某个行向量为![]() ,那么基于L2范数的归一化的公式如下。
,那么基于L2范数的归一化的公式如下。

scikit-learn中预处理模块(preprocessing)中的normalize函数可用来做归一化处理。
4. 异常值与数值截断
对于数值型数据,可能会存在异常值,包括异常大和异常小的值。在统计数据处理中有所谓3σ准则,即对于服从正态分布的随机变量,该变量的数值分布在(μ-3σ,μ+3σ)中的概率为0.9974,这时可以将超出该范围的值看成异常值,采用向上截断(用μ-3σ截断,即小于μ-3σ的值用μ-3σ替代)和向下截断(用μ+3σ截断,即大于μ+3σ的值用μ+3σ替代)的方法来为异常值赋予新的值。
对于真实业务场景,可能还要根据特征变量的实际意义来进行处理,笔者在之前做视频推荐过程中,经常会发现日志中视频的总时长是一个非常非常大的值(可能是在日志埋点时将时间戳混杂到视频时长中了),我们一般会用180分钟来截断电影的总时长,用45分钟来截断电视剧单集的总时长。
如果异常值所占样本比例非常少,也可以直接将包含异常值的样本剔除掉,但是有很多真实业务场景的算法模型利用非常多的特征,虽然每个特征异常值很少,但是如果特征总数很多的话,包含异常值的样本(只要包含某一个异常值的都算异常样本)总数可能是非常大的,所以直接丢弃的方法有时是不合适的。
5. 非线性变换
有时某个属性不同值之间差别较大(比如年收入),有时为了让模型具备更多的非线性能力(特别是对于线性模型),这两种情况下都需要对特征进行非线性变换,比如值取对数(值都是正的情况下)作为最终的特征,也可以采用多项式、高斯变换、logistic变换等转化为非线性特征。另外,对特征进行分桶,对数据进行降维(如PCA降维)都属于分线性变换方法。上面提到的分位数归一化、正态分布归一化其实都是非线性变换。
6. 类不平衡的处理
前面讲到的都是特征数据的预处理,当涉及到目标变量时,有时也需要进行适当的处理,这里面最常见的情况是当我们构建分类模型时会存在类不平衡的问题,也即正样本或者负样本其中一个的数量远小于另外一个。这种情况如果不进行处理会导致学习到的模型向出现次数多的那个类别倾斜(因为这个类别的数据多,导致“投票权过大”,容易左右最终的分类结果)。一般的处理方法是进行上采样或者下采样。这里举个例子说明一下,如果是正样本远远小于负样本,那么下采样就是从负样本中随机筛选样本,直到最终选出的负样本数量跟正样本数量差不多多,上采样(上采样可以采用构造样本的方法,如Smote算法等)是从正样本中重复抽样,加入正样本集合中,让正样本的数量大致等于负样本的数量。通过上采样和下采样我们就可以保证正负样本差不多多,这样就可以避免类不平衡问题。
处理类不平衡问题还可以从损失函数入手,通过设置损失函数的权重,使得少数类别数据判断错误的损失大于多数类别数据判断错误的损失,即当我们的少数类别数据预测错误的时候,会产生一个比较大的损失值,从而让模型参数往“让少数类别数据预测准确”的方向倾斜。
7. 机器学习范式的调整
有时为了解决问题的方便,我们还可能会调整机器学习的范式,比如将多分类问题转为2分类问题,将回归问题转为分类问题等,这时就需要对目标变量进行预处理。比如某些业务场景其实是不需要知道人的具体的年龄的,这时可以将人按照年龄分为少儿、少年人、青年人、中年人、老年人等几类,将回归问题(预测人的年龄)转化为分类问题(预测是少儿、少年人、青年人、中年人还是老年人)。也有将分类问题转为预测连续值的,最典型的是logistic回归,通过logistic回归来预测目标变量出现的概率。
二、时空数据的预处理
时空数据也是推荐系统中非常重要的数据,特别是基于地理位置(LBS)的应用(比如滴滴、美团外卖等)。对于某些业务问题,时间和空间数据是非常关键的,包含了正确预测目标标量的重要信息。对于时空数据的处理一般可以转为数值数据或者类别数据。下面分别对时间数据和空间数据的预处理进行说明。
1. 时间数据
如果是精确的时间可以用长整型表示(转化为从某个起点开始经历的秒数),时间也可以是年份、星期、月份、季度等,不管哪种方式都可以采用跟数值数据或类别数据类似的处理方式,这里不赘述。
2. 空间数据
如果空间是采用经纬度这种二维坐标表示,那么就是一个二维向量。如果是采用距离表示,那么就是一个数值。如果用上下左右前后这种方位表示,那么可以看成是类别变量。不管怎样,都可以采用跟数值数据或者离散数据的方式进行预处理,这里不赘述。
三、文本数据的预处理
原始文本数据中存在的问题有多种,比如有不合法的字符、多余的标点等(特别是通过爬虫爬的数据可能会比较杂乱),这些是需要剔除掉的。有些文本是通过ASR(Automatic Speech Recognition,自动语音识别技术)技术将录音文件转为文本的,这里面还涉及到方言、同音词、发音不准、停顿产生的重复字词、表述方式颠倒混乱等问题,这些都是需要进行预处理的,否则会影响后续特征工程的效果。
上面提到的很多问题本身就是NLP领域非常棘手的问题,不是特别好处理,也没有通用的好方法,这些问题的解决方案也超出了本书讨论的范围,这里不再赘述,感兴趣的读者可以自行查阅相关学习材料。
四、富媒体数据的预处理
这里的富媒体数据主要是指图片、视频、音频等。下面分别对它们涉及到的数据预处理进行简单说明。
图片数据通常需要进行的处理是将所有图片尺寸调整为一致,这主要是方便深度学习等技术进一步对图片等进行建模学习。有些机器学习方法还需要对图片进行灰度处理,这主要是基于目的来定的,有些模型(比如OCR),不需要色彩信息,这时就可以灰度处理,这样处理的好处是减少处理复杂度,提升处理效率。因为彩色图像包含信息量大,处理速度较慢,要是每秒的帧数多,又是彩色的,会造成程序运行特别慢,甚至程序被卡死。彩色图像最常见的是RGB三个通道或者RGB加上透明度四个通道,灰度图就一个通道,信息量减少了好几倍,变成灰度后,模型处理效率会提升很多。
对于视频的处理,很多机器学习应用(比如标签提取、视频比对等)是将视频提取关键帧,再采用处理图片的思路,所以预处理就跟图片类似。
从音频中提取机器学习特征的方式有两种,那么对应数据预处理方式也有两种:一种是通过ASR转为文字,这在上面已经介绍过了,这里不再说明;另一种是直接从音频中提取特征,这时预处理需要做的工作有剔除声音中的噪音、调低或者调高音量、调整倍速播放等。另外,音频也会有多种格式,一般也会将不同的格式转换为同一种格式,方便后续进一步处理。
其它的多媒体数据,比如Word、PDF、HTML等等,都需要进行预处理,转化为上面提到的一些数据形式,方便后续处理,这里不再赘述。
总结
本章我们简单整理了原始数据在进行特征工程之前需要进行的预处理。我们本章的讲解是根据数据的类别来分别说明的,主要从数值数据、类别数据、时空数据、文本数据、富媒体数据等几个大类来讲解各自的预处理方法和策略。
原始数据只有经过适当的预处理,让格式更规整,质量更高,才会在后面的机器学习建模过程中获得更好的效果。我们会在后续章节详细说明经过处理的数据怎么进行特征工程、怎么选择特征、怎么评估特征等与特征工程相关的知识。
我出版的畅销书《构建企业级推荐系统:算法、工程实现与案例分析》,可以跟这个系列文章一起阅读,大家有需要可以点击下面链接购买。
