NER实战(数据处理+模型分析(词典匹配,统计ML,DL)+评价标准+模型融合)
0、NER 简介
多特征:实体识别不是一个特别复杂的任务,不需要太深入的模型,那么就是加特征,特征越多效果越好,所以字特征、词特征、词性特征、句法特征、KG表征等等的就一个个加吧,甚至有些中文 NER 任务里还加入了拼音特征、笔画特征。。?心有多大,特征就有多多
多任务:很多时候做 NER 的目的并不仅是为了 NER,而是服务于一个更大的目标或系统,比如信息抽取、问答系统等等。如果把整个大任务做一个端到端的模型,就需要做成一个多任务模型,把 NER 作为其中一个子任务;另外,单纯的 NER 也可以做成多任务(cascade),比如实体类型过多时,仅用一个序列标注任务来同时抽取实体与判断实体类型,会有些力不从心,就可以拆成两个子任务来做
时令大杂烩:把当下比较流行的深度学习话题或方法跟 NER 结合一下,比如结合强化学习的 NER、结合 few-shot learning 的 NER、结合多模态信息的 NER、结合跨语种学习的 NER 等等的,具体就不提了
首先是 LSTM-CRF,
和 BERT-CRF,
然后就是几个多任务模型, Cascade 开头的(因为实体类型比较多,把NER拆成两个任务,一个用来识别实体,另一个用来判断实体类型),
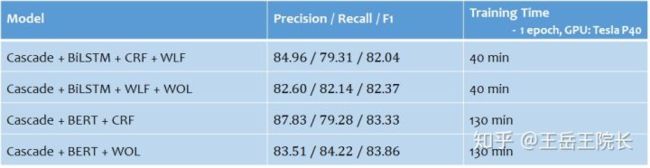
后面的几个模型里,WLF 指的是 Word Level Feature(即在原本字级别的序列标注任务上加入词级别的表征),
WOL 指的是 Weight of Loss(即在loss函数方面通过设置权重来权衡Precision与Recall,以达到提高F1的目的)
1. 模型介绍
代码:上述所有模型的代码都在这里,带 BERT 的可以自己去下载 BERT_CHINESE 预训练的 ckpt 模型,然后解压到 bert_model 目录下
数据集:一个电商场景下商品标题中的实体识别,因为是工作中的数据,并且通过远程监督弱标注的质量也一般,完整数据就不放了。但是我 sample 了一些数据留在 git 里了
-
HMM/PERCEPTRON/CRF
-
BI-LSTM+CRF
-
BERT+CRF & BERT+LSTM+CRF
BERT 还有一个至关重要的训练技巧,就是调整学习率。BERT内的参数在 fine-tuning 时,学习率一定要调小,特别时后面还接了别的东西时,一定要按两个学习率走,甚至需要尝试多次反复调,要不然 BERT 很容易就步子迈大了掉沟里爬不上来,个人经验。 -
Cascade 多任务NER
2、嵌套实体如何识别?
1、阅读理解
2、指针网络(预测实体的头尾),收敛可能较慢
Details: NER除了LSTM+CRF,还有哪些解码方式?如何解决嵌套实体问题?
虽然NER是一个比较常见的NLP任务,通常采用LSTM+CRF处理一些简单NER任务。NER还存在嵌套实体问题(实体重叠问题),如「《叶圣陶散文选集》」中会出现两个实体「叶圣陶」和「叶圣陶散文选集」分别代表「作者」和「作品」两个实体。而传统做法由于每一个token只能属于一种Tag,无法解决这类问题。笔者尝试通过归纳几种常见并易于理解的 实体抽取解码方式 来回答这个问题。
1、序列标注:SoftMax和CRF
本质上是token-level 的多分类问题,通常采用CNNs/RNNs/BERT+CRF处理这类问题。与SoftMax相比,CRF进了标签约束。对这类方法的改进,介绍2篇比较有价值的工作:
针对CRF解码慢的问题,LAN[1]提出了一种逐层改进的基于标签注意力机制的网络,在保证效果的前提下比 CRF 解码速度更快。文中也发现BiLSTM-CRF在复杂类别情况下相比BiLSTM-softmax并没有显著优势。
由于分词边界错误会导致实体抽取错误,基于LatticeLSTM[2]+CRF的方法可引入词汇信息并避免分词错误(词汇边界通常为实体边界,根据大量语料构建词典,若当前字符与之前字符构成词汇,则从这些词汇中提取信息,联合更新记忆状态)。
但由于这种序列标注采取BILOU标注框架,每一个token只能属于一种,不能解决重叠实体问题,如图所示。
基于BILOU标注框架,笔者尝试给出了2种改进方法去解决实体重叠问题:
改进方法1:采取token-level 的多label分类,将SoftMax替换为Sigmoid,如图所示。当然这种方式可能会导致label之间依赖关系的缺失,可采取后处理规则进行约束。
改进方法2:依然采用CRF,但设置多个标签层,对于每一个token给出其所有的label,然后将所有标签层合并。显然这可能会增加label数量[3],导致label不平衡问题。基于这种方式,文献[4]也采取先验图的方式去解决重叠实体问题。
2、Span抽取:指针网络
指针网络(PointerNet)最早应用于MRC中,而MRC中通常根据1个question从passage中抽取1个答案片段,转化为2个n元SoftMax分类预测头指针和尾指针。对于NER可能会存在多个实体Span,因此需要转化为n个2元Sigmoid分类预测头指针和尾指针。
将指针网络应用于NER中,可以采取以下两种方式:
第一种:MRC-QA+单层指针网络。在ShannonAI的文章中[5],构建query问题指代所要抽取的实体类型,同时也引入了先验语义知识。如图所示,由于构建query问题已经指代了实体类型,所以使用单层指针网络即可;除了使用指针网络预测实体开始位置、结束位置外,还基于开始和结束位置对构成的所有实体Span预测实体概率[6]。此外,这种方法也适合于给定事件类型下的事件主体抽取,可以将事件类型当作query,也可以将单层指针网络替换为CRF。
第二种:多层label指针网络。由于只使用单层指针网络时,无法抽取多类型的实体,我们可以构建多层指针网络,每一层都对应一个实体类型。
需要注意的是:
1)MRC-QA会引入query进行实体类型编码,这会导致需要对愿文本重复编码输入,以构造不同的实体类型query,这会提升计算量。
2)笔者在实践中发现,n个2元Sigmoid分类的指针网络,会导致样本Tag空间稀疏,同时收敛速度会较慢,特别是对于实体span长度较长的情况。
3、片段排列+分类
上述序列标注和Span抽取的方法都是停留在token-level进行NER,间接去提取span-level的特征。而基于片段排列的方式[7],显示的提取所有可能的片段排列,由于选择的每一个片段都是独立的,因此可以直接提取span-level的特征去解决重叠实体问题。
对于含T个token的文本,理论上共有 [公式] 种片段排列。如果文本过长,会产生大量的负样本,在实际中需要限制span长度并合理削减负样本。
需要注意的是:
实体span的编码表示:在span范围内采取注意力机制与基于原始输入的LSTM编码进行交互。然后所有的实体span表示并行的喂入SoftMax进行实体分类。
这种片段排列的方式对于长文本复杂度是较高的。
4、Seq2Seq:
ACL2019的一篇paper中采取Seq2Seq方法[3],encoder部分输入的原文tokens,而decoder部分采取hard attention方式one-by-one预测当前token所有可能的tag label,直至输出 (end of word) label,然后转入下一个token再进行解码。
3. 如何平衡准确率与召回率?
1、分类任务:调节解码时的阈值
对于一个分类任务,是很容易通过设置一个可调的“阈值”来达到控制 P/R 的目的的。举个例子,判断一张图是不是 H 图,做一个二分类模型,假设模型认为图片是 H 图的概率是 p,人为设定一个阈值 a,假如 p>a 则认为该图片是 H 图。默认情况 p=0.5,此时如果降低 p,就能达到提高 Recall 降低 Precision 的目的.
但是 NER 任务怎么整呢,他的结果是一个完整的序列,你又不能给每个位置都卡一个阈值,没有意义.
2、所有深度学习任务:Weight of Loss e.g. 提高召回:漏预测增加损失、错预测降低损失;反之提高精确率
在所有深度学习任务上,都可以通过调整 Loss 来达到各种特殊的效果. 即在loss函数方面通过设置权重来权衡Precision与Recall,以达到提高F1的目的
通过控制模型学习时的 Loss 来控制 P/R:如果模型没有识别到一个本应该识别到的实体,就增大对应的 Loss,加重对模型的惩罚;如果模型识别到了一个不应该识别到的实体,就减小对应的 Loss,当然是选择原谅他.
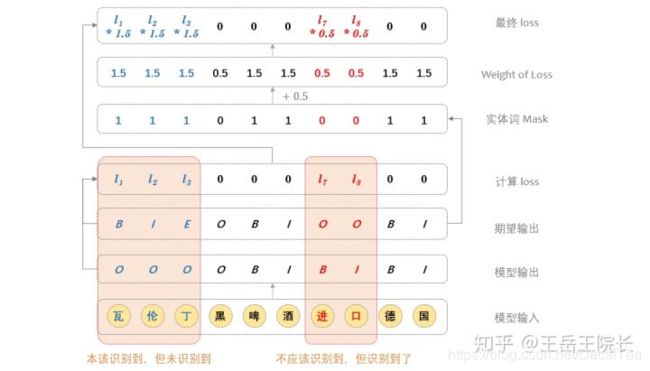
# logits_bio 是预测结果,形状为 B*S*V,softmax 之后就是每个字在BIO词表上的分布概率,不过不用写softmax,因为下面的函数会帮你做
# self.outputs_seq_bio 是期望输出,形状为 B*S
# 这是原本计算出来的 loss
loss_bio = tf.nn.sparse_softmax_cross_entropy_with_logits(logits=logits_bio, labels=self.outputs_seq_bio) # B * S
# 这是根据期望的输出,获得 mask 向量,向量里出现1的位置代表对应的字是一个实体词,而 O_tag_index 就是 O 在 BIO 词表中的位置
masks_of_entity = tf.cast(tf.not_equal(self.outputs_seq_bio, O_tag_index), tf.float32) # B * S
# 这是基于 mask 计算 weights
weights_of_loss = masks_of_entity + 0.5 # B *S
# 这是加权后的 loss
loss_bio = loss_bio * weights_of_loss # B * S
我还不知道怎么把这个方法和 CRF 结合起来。因为在代码里,CRF 通过函数crf_log_likelihood 直接计算得到整个句子级别的 loss,而不是像上面一样,用交叉熵在每个字上计算 loss,所以这种基于 mask 的方法就没法用了
但是从实验效果来看,虽然去掉了 CRF,但是加入 WOL 之后的方法的 F1Score 还是要大一些。原本 Precision 远大于 Recall,通过权衡,把两个分数拉到同个水平,可以提升最终的 F1Score.
3、加入领域字典+规则模板提高召回
4. How to combine Word-Level Feature and char-level feature ?
即在原本字级别的序列标注任务上加入词级别的表征
中文 NER 和英文 NER 有个比较明显的区别,就是英文 NER 是从单词级别(word level)来做,而中文 NER 一般是字级别(character level)来做。
词级别的中文NER:利用ML模型,如HMM, CRF, 感知机。基于分词器和词性标注器的结果,根据规则将分词和词性标注集转化为命名实体识别的标注集。
字级别的中文NER:利用深度学习模型,如BERT,因为BERT提取的是字特征向量。优点是可以避免因为分词错误所以识别不到实体的情况。
NER-DL:如何结合字特征和词特征呢?
对于英文NER:
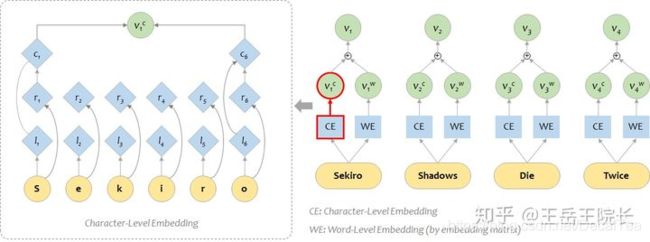
在英文 NLP 任务中,想要把字级别特征加入到词级别特征上去,一般是这样:单独用一个BiLSTM 作为 character-level 的编码器,把单词的各个字拆开,送进 LSTM 得到向量 vc;然后和原本 word-level 的(经过 embedding matrix 得到的)的向量 vw 加在一起,就能得到融合两种特征的表征向量。如图所示:
对于中文NER:
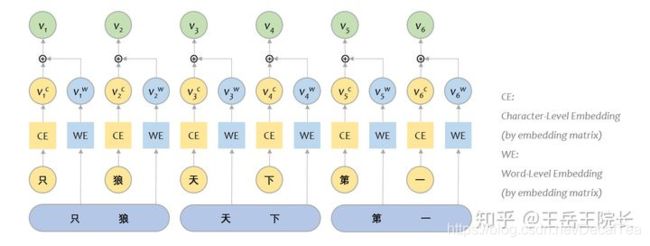
我的输入是字级别的,怎么把词级别的表征结果加入进来呢?
ACL2018 有个文章[4]是做这个的,提出了一种 Lattice-LSTM 的结构,但是涉及比较底层的改动,不好实现。后来在 ACL2020 论文里看到一篇文章[5],简单明了。然后我就再简化一下,直接把字和词分别通过 embedding matrix 做表征,按照对应关系,拼在一起:
从结果上看,增加了词级别特征后,提升很明显:

我还没有找到把词级别特征结合到 BERT 中的方法。因为 BERT 是字级别预训练好的模型,如果单纯从 embedding 层这么拼接,那后面那些 Transformer 层的参数就都失效了