CRF++入门学习
CRF++简介
Conditional Random Field:条件随机场,一种机器学习技术(模型)
CRF由John Lafferty最早用于NLP技术领域,其在NLP技术领域中主要用于文本标注,并有多种应用场景,例如:
- 分词(标注字的词位信息,由字构词)
- 词性标注(标注分词的词性,例如:名词,动词,助词)
- 命名实体识别(识别人名,地名,机构名,商品名等具有一定内在规律的实体名词)
CRF++安装
CRF++官方下载地址:https://taku910.github.io/crfpp/
Windows版的无须安装,直接解压即可使用
Linux编译命令,在解码目录依次执行下面两条命令
% ./configure
% make
% su
#make install
注:只有拥有root帐号的用户才能成功安装。(su 命令就是切换到root权限下)
CRF++解压后的说明
doc文件夹:官方主页的内容
example文件夹:有四个数据包,每个数据包有四个文件:
训练数据(test.data)、测试数据(train.data)、模板文件(template)、执行脚本文件exec.sh。
example文件夹:有四个任务的训练数据、测试数据和模板文件。
sdk文件夹:CRF++的头文件和静态链接库。
crf_learn.exe:CRF++的训练程序
crf_test.exe:CRF++的预测程序
libcrfpp.dll:训练程序和预测程序需要使用的静态链接库。
简单说,就是只用crf_learn.exe、crf_test.exe、libcrfpp.dll这三个
这里直接使用CRF自带的例子进行试验一下:
在example中的某个例子做一下测试。例如:example中chunking文件夹,其中原有4个文件:exec.sh;template;test.data;train.data。将crf_learn.exe;crf_test.exe;libcrfpp.dll三个文件复制到这个文件夹(chunking)底下。
输入如下(看自己解压到那个文件夹):
D:\CRF++-0.58\example\chunking>crf_learn template train.data model
你可以看到控制台上打印处的信息,并会产生一个新的文件:model。
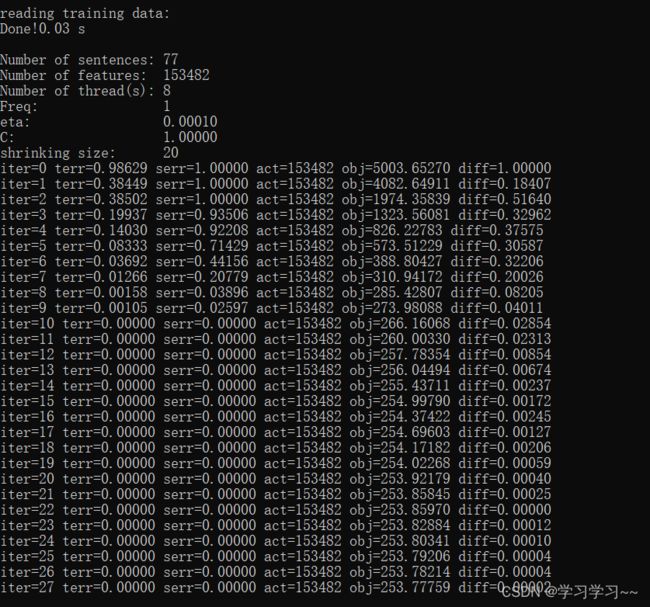 训练中一些参数的说明:
训练中一些参数的说明:
ter:迭代次数
terr:标记错误率
serr:句字错误率
obj:当前对象的值。当这个值收敛到一个确定值的时候,训练完成
diff:与上一个对象值之间的相对差
训练语料格式:
1. 训练语料至少应具有两列,列间由空格或制表位间隔,且所有行(空行除外)必须具有相同的列数。句子间使用空行间隔。
2. 一些合法的语料示例:
有两列特征的:
太 Sd N
短 Sa N
而 Bu N
已 Eu N
。 Sw N
只有一列特征的
太 N
短 N
而 N
已 N
。 N
特征的选取及模板的编写(template格式):
特征选取的行是相对的,列是绝对的,一般选取相对行前后m行,选取n-1列(假设语料总共有n列),特征表示方法为:%x[行,列],行列的初始位置都为0。例如:
以前面语料为例
“ Sw N
北 Bns B-LOC
京 Mns I-LOC
市 Ens I-LOC
首 Bn N
假设当前行为“京”字这一行,那么特征可以这样选取:
特征模板 意义 代表特征
%x[-2,0] -2行,0列 “
%x[-1,0] -1行,0列 北
%x[0,0] 0行,0列 京
%x[1,0] 1行,0列 市
%x[2,0] 2行,0列 首
%x[-1,0]/%x[0,0] -1行0列与0行0列的组合 北/京
模板制作:模板分为两类:Unigram和Bigram。
其中Unigram/Bigram是指输出token的Unigram/Bigrams,而不是特征。
以前面示例中的特征为特征,制作为Unigram模板如下:
#Unigram
U00:%x[-2,0]
U01:%x[-1,0]
U02:%x[0,0]
U03:%x[1,0]
U04:%x[2,0]
说明:
1. 行与行之间可以有空行;
2.Unigram的特征前使用字母U,而Bigram的特征前使用字母B。后面的数字用于区分特征,当然这些数字不是一定要连续。
训练:
语料的训练可以使用命令(在终端或DOS命令行中):crf_learn <模板> <训练语料> <模板文件>(% crf_learn template train.data model)
其中模板和训练语料是需要事先准备好的,模板文件在训练完成后生成
测试:
命令行:
% crf_test -m model test.data
有两个参数-v和-n都是显示一些信息的,-v可以显示预测标签的概率值,-n可以显示不同可能序列的概率值,对于准确率,召回率,运行效率,没有影响
参考博客:
链接:https://blog.csdn.net/felomeng/article/details/4288492