较YOLOv7精度提升1.9%,54.7mAP的PP-YOLOE+强势登场!

精度54.7mAP,相较YOLOv7提升1.9%
L版本端到端推理速度42.2FPS
训练速度提升3.75倍
COCO数据集仅需20epoch即可达到50.0mAP
下游任务泛化性最高提升8%
10+即开即用多端部署Demo
这究竟是什么模型,竟可达到以上效果?
答案是:PP-YOLOE+
PP-YOLOE+是基于飞桨云边一体高精度模型PP-YOLOE迭代优化升级的版本,具备以下特点:
- 超强性能
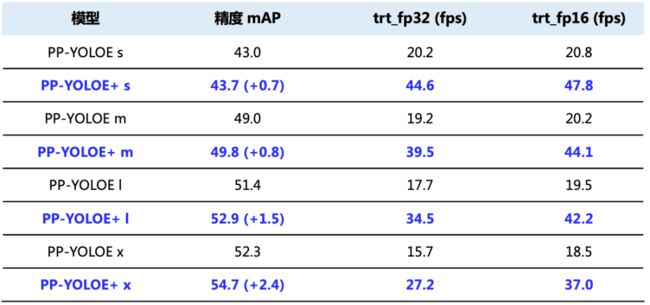
表格1:PP-YOLOE+与PP-YOLOE性能对比
*备注:上表中的数据均在V100上测试所得,V100 + CUDA11.2 + cudnn8.2.0 + TRT8.0.1.6
-
训练收敛加速:使用Objects365预训练模型,减少训练轮数,训练收敛速度提升3.75倍。
-
下游任务泛化性显著提升:在农业、夜间安防、工业等不同场景数据集上验证,精度最高提升8.1%。
-
高性能部署能力:本次升级PP-YOLOE+支持多种部署方式,包括Python/C++、Serving、ONNX Runtime、ONNX-TRT、INT8量化等部署能力。
超强性能与超高泛化性使得PP-YOLOE+助力开发者在最短时间、最少量数据上能得到最优效果。
模型下载与完整教程请见PP-YOLOE+:
https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.5/configs/ppyoloe

回顾:PP-YOLOE经典网络结构剖析
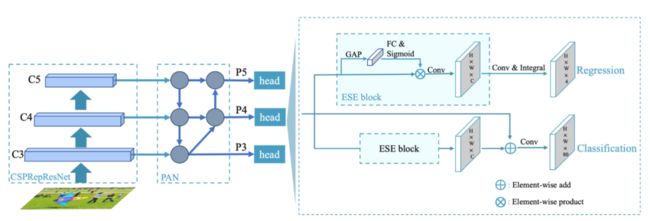
图1:PP-YOLOE网络结构
PP-YOLOE是一款高精度推理速度快的检测模型,包含骨干网络CSPRepResNet、特征融合CSPPAN、轻量级ET-Head和改进的动态匹配算法TAL(Task Alignment Learning)等模块, 并且根据不同的应用场景设计了一系列模型,即s/m/l/x。
PP-YOLOE的全系列模型从精度速度性价比来看达到工业界最优。具体来说,PP-YOLOE-l在COCO test-dev上AP可达51.4,在V100上速度可达78.1 FPS,使用TensorRT FP16进行推理,在V100上速度可达149FPS。
PP-YOLOE-l相较于PP-YOLOv2精度提升1.9AP、速度提升13.35%,相对于YOLOX-l精度提升1.3AP、速度提升24.96%。
此外,PP-YOLOE还避免使用诸如可变形卷积或者Matrix NMS之类的特殊算子,使PP-YOLOE全系列模型能轻松地部署在NVIDIA V100和T4这样的云端GPU架构、Jetson系列的移动端GPU和高性能的FPGA开发板上****。
具体的结构包括以下三大部分:
可扩展的backbone和neck
我们设计了CSPRepResNet作为backbone, neck部分也采用了新设计的CSPPAN结构,backbone和neck均以我们提出的CSPRepResStage为基础模块。新的backbone和neck在增强模型表征能力的同时提升了模型的推理速度,并且可以通过width multiplier和depth multiplier灵活地配置模型的大小。
TAL(Task Alignment Learning)
为了进一步提升模型的精度,我们选用了TOOD [1]中的动态匹配算法策略TAL。TAL同时考虑分类和回归,使得匹配结果同时获得了最优的分类和定位精度。
Efficient Task-aligned head
检测head方面,我们在TOOD的T-head基础上进行改进。
首先,使用ESE block替换掉了原文中比较耗时的layer attention,使得模型在保证精度不变的同时提升了速度。
其次,由于T-head使用了可变形卷积算子,对硬件部署不友好,我们在分类分支使用shortcut替换cls-align模块,回归分支使用积分层替换掉含有可变形卷积的reg-align模块,以上两个改进使得head变得更为高效、简洁且易部署。
最终,我们进一步使用VFL(VariFocal Loss)替换BCE作为分类分支Loss,达到了速度精度双高的目的。
PP-YOLOE+算法升级深度解读
本次PP-YOLOE+升级主要内容:
-
升级一:强大的Objects365预训练模型、升级版backbone等改动大幅提升PP-YOLOE系列模型的精度;
-
升级二:优化预处理,提升模型端到端推理速度,更贴近用户使用的真实场景;
-
升级三:完善多种环境下的推理部署能力。
精度
首先,我们使用Objects365大规模数据集对模型进行了预训练。Objects365数据集含有的数据量可达百万级,在大数据量下的训练可以使模型获得更强大的特征提取能力、更好的泛化能力,在下游任务上的训练可以达到更好的效果。
其次,我们在RepResBlock中的1x1卷积上增加了一个可学习的权重alpha,进一步提升了backbone的表征能力,获得了不错的效果提升。最后,我们调整了NMS的参数,在COCO上可以获得更好的评估精度。
训练速度
基于Objects365的预训练模型,将学习率调整为原始学习率的十分之一,训练的epoch从300降到了80,在大大缩短了训练时间的同时,获得了精度上的提升。
端到端推理速度
我们精简了预处理的计算方式,由于减均值除方差的方式在CPU上极其耗时,所以我们在优化时直接去除掉了这部分的预处理操作,使得PP-YOLOE+系列模型在端到端的速度上能获得40%以上的加速提升。
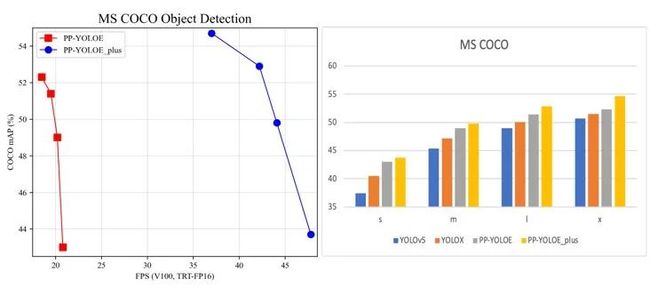
图2:PP-YOLOE+模型效果
下游泛化性增强
我们验证了PP-YOLOE+模型强大的泛化能力,在农业、低光、工业等不同场景下游任务检测效果稳定提升。
农业数据集采用Embrapa WGISD,该数据集用于葡萄栽培中基于图像的监测和现场机器人技术,提供了来自5种不同葡萄品种的实地实例。
- 链接
https://github.com/thsant/wgisd
低光数据集使用ExDark,该数据集是一个专门在低光照环境下拍摄出针对低光目标检测的数据集,包括从极低光环境到暮光环境等10种不同光照条件下的图片。
- 链接
https://github.com/thsant/wgisd
工业数据集使用PKU-Market-PCB,该数据集用于印刷电路板(PCB)的瑕疵检测,提供了6种常见的PCB缺陷。
- 链接
https://robotics.pkusz.edu.cn/resources/dataset/
精度
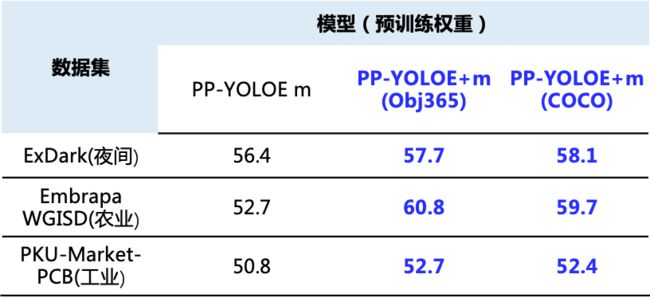
表格2:PP-YOLOE+在不同场景数据集的效果
可视化效果
图3:可视化效果
全面升级的部署支持
在推理部署方面,本次升级给大家带来了较为完备的部署能力,包括Python、C++、Serving、ONNX Runtime、ONNX-TRT、INT8量化等部署能力。具体的使用文档可以到PaddleDetection的GitHub上获取。
- 文档链接
https://github.com/PaddlePaddle/PaddleDetection/tree/release/2.5/deploy
总的来说,PP-YOLOE+希望真正的站在用户的角度去解决训练慢、泛化性差、部署难的问题。通过使用大规模数据集Objects365对模型进行预训练,使得模型在下游任务上表现更鲁棒、泛化能力更强。通过优化推理过程,完善推理链条,使得PP-YOLOE+不但在端到端预测速度上得到极大的提升,还拓展了Python、C++、Serving、ONNX Runtime以及TensorRT等多种推理环境下的部署能力,提升模型可扩展性,从而提升用户的使用体验。
飞桨端到端开发套件PaddleDetection
PaddleDetection为基于飞桨的端到端目标检测套件,内置30+模****型算法及300+预训练模型,覆盖目标检测、实例分割、跟踪、关键点检测等方向,其中包括服务器端和移动端高精度、轻量化产业级SOTA模型、冠军方案和学术前沿算法,并提供即插即用的垂类场景预训练模型,覆盖人、车等20+场景,提供配置化的网络模块组件、十余种数据增强策略和损失函数等高阶优化支持和多种部署方案,在打通数据处理、模型开发、训练、压缩、部署全流程的基础上,提供丰富的案例及教程,加速算法产业落地应用。
图4:PaddleDetection全景图
-
项目链接
https://github.com/PaddlePaddle/PaddleDetection -
参考文献
[1] Feng C , Zhong Y , Gao Y , et al. TOOD: Task-aligned One-stage Object Detection[C]// 2021.
10月18日晚20:15,飞桨PP-YOLO系列作者——百度高级研发工程师将带来目标检测YOLO全系列算法详解,深度解析每一代YOLO算法的特点,并重点介绍PP-YOLO系列的研发心得与技术特性,千万不可错过!
关注【飞桨PaddlePaddle】公众号
获取更多技术内容~