语音识别原理与应用 洪青阳 第一章 概论
目录
第一章 语音识别概论
1.1 语音的产生和感知
1.2 语音识别过程
1.3语音识别发展历史
第一章 语音识别概论
语音识别的基础理论包括语音的产生和感知过程、语音信号基础知识、语音特征提取等。
关键技术包括高斯混合模型(Gaussian Mixture Model,GMM)、隐马尔科夫模型(Hidden Markov Model,HMM)、深度神经网络(Deep Neural Network,DNN),以及基于这些模型形成的GMM-HMM、DNN-HMM 和 端到端(End-to-End,E2E)系统。语言模型 和 解码器 也非常关键,直接影响语音识别实际应用的效果。
1.1 语音的产生和感知
人的发音器官包括肺、气管、声带、喉、咽、鼻腔、口腔、和唇。
肺部产生的气流冲击声带,产生振动。
声带每开启和闭合一次的时间是一个基音周期(Pitch period)T,其倒数为基音频率(F0=1/T,基频),范围在70HZ---450HZ。基频越高,声音越尖细。基频随时间的变化,也反映了声调的变化。
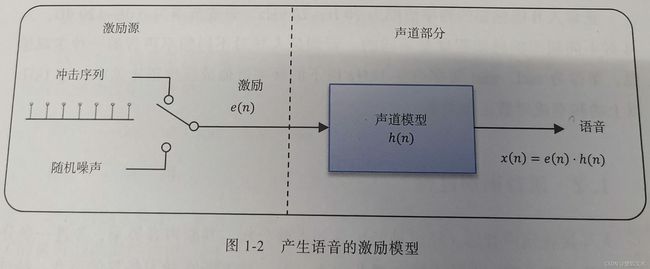
语音的产生过程可进一步抽象成如上图所示的激励的模型。包括激励源和声道部分。在激励源部分,冲击序列发生器以基音周期产生周期性信号,经过声带振动, 相当于经过声门波模型,肺部气流大小相当于振幅;随机噪声发生器产生非周期性信号。声道模型模拟口腔、鼻腔等声道器官,最后产生语音信号。我们要发浊音时,声带振动形成准周期的冲击序列。发清音时,声带松弛,相当于发出一个随机噪声。
1.2 语音识别过程
音素(phone)是构成语音的最小单位。英语中有48个音素(20个元音和28个辅音)。
若采用元音和辅音来分类,汉语普通话有32个音素,包括元音10个,辅音22个。但普通话的韵母多是复韵母,不是简单的元音,因此拼音一般分为声母(initial)和韵母(final)。
音节(syllable)是听觉能感受到的最自然的语音单位,由一个或多个音素按一定的规律组合而成。英语音节可由一个元音或元音和辅音构成。汉语的音节由声母、韵母和音调构成,其中音调信息包括在韵母中。所以,汉语音节结构可以简化为:声母+韵母。
注:音素(序列)组成音节(序列),从而识别出文字。
汉字与汉语音节并不是一一对应的。一个汉字可以对应多个音节,一个音节可对应多个汉字。
例如:
和 ----- he二声 he四声 huo二声 huo四声 hu二声
tian二声 ----- 填 甜
语音识别过程是个复杂的过程,但其最终任务归结为,找到对应观测值序列O的最可能的词序列W’。按贝叶斯准则转化为:
W' = arg max P(W|O) = arg max(P(O|W)P(W))/(P(O))
W' = arg max P(O|W)P(W)
其中,P(O)与P(W)没有关系,可认为是常量,因此P(W|O)的最大值可转换为P(O|W)和P(W)两项乘积的最大值,第一项P(O|W)由声学模型决定,第二项P(W)由语言模型决定。

上图是典型的语音识别过程。为了让机器识别语音,首先提取声学特征,然后通过解码器得到状态序列,并转换为对应的识别单元。一般是通过词典将音素序列(如普通话的声母和韵母),转换为词序列,然后用语言模型规整约束,最后得到句子识别结果。

如上图所示,对“今天天气很好”进行词序列、因素序列、状态序列的分解,并和观测值序列对应,其中每个音素对应一个HMM,并且其发射状态(深色)对应多帧观测值。

现在工业应用普遍要求大词汇量连续语音识别(LVCSR)。
1.3语音识别发展历史
解决任务:孤立词识别 → 大规模连续语音识别 → 复杂场景识别
技术发展:模板匹配(DTW) → 统计模型(GMM-HMM) → 深度学习(DNN-HMM,E2E)
DTW(Dynamic Time Warping)动态时间规整:使用动态规划算法将两段不同长度的语音在时间轴上进行了对齐。该算法把时间规整和距离的计算有机地结合起来,解决了不同时长语音的匹配问题。在一些要求资源占用率低、识别人比较特定的环境下,DTW是一种很经典很常用的模板匹配算法。
统计模型两项很重要的成果是声学模型和语言模型,语言模型以n元语言模型(n-gram)为代表,声学模型则以HMM为代表。
GMM-HMM:(1)用HMM对语音状态的转移概率建模;(2)用高斯混合模型(Gaussian Mixture Model,GMM)对语音状态的观测值概率建模。
HTK(Hidden Markov Tool Kit)是一款开源的基于HMM的语音识别工具包。
Ka1di,是DNN-HMM系统的基石,在工业界得到广泛应用。
大多数主流的语音识别解码器基于加权有限状态转换器(WFST),把发音词典、声学模型和语言模型编译成静态解码网络,这样可大大加快解码速度,为语音识别的实时应用奠定基础。
RNN可更有效、更充分地利用语音中的上下文信息。引入LSTM或其变体以解决梯度消失的问题。
CNN可通过共享权值来减少计算的复杂度,并且CNN被证明在挖掘语音局部信息的能力上更为突出。
Attention模型的对齐关系没有先后顺序的限制,完全靠数据驱动得到,对齐的盲目性会导致训练和解码时间过长。而CTC的前向后向算法可以引导输出序列和输入序列按时间顺序对齐。
Transformer架构:在Decoder和Encoder中均采用Attention机制。