python爬虫爬取房源信息
目录
一、数据获取与预处理
二、csv文件的保存
三、数据库存储
四、爬虫完整代码
五、数据库存储完整代码
写这篇博客的原因是在我爬取房产这类数据信息的时候,发现csdn中好多博主写的关于此类的文章代码已经不适用,因为好多房产网站代码已经更改,使用老的代码明显爬取不到所需要的房产信息。这篇博客是根据58同城中的二手房源代码进行爬取的,有遇到问题的伙伴可以借鉴一下,由于博主水平有限,所以有什么错误的地方还望各位伙伴评论区指正,谢谢~
一、数据获取与预处理
1、导入模块
python爬取网站信息采用的几种库和方法分别问beautifulsoup、Xpath、正则表达式,而此处我使用的是xpath。原因很简单,房源网站源代码使用xpath比较好提取数据,建议所有python学习者将爬虫方法都学一遍,这样的话遇到不同的网站就可以使用不同的方法来达到简单爬取所需信息的目的。
代码如下所示:
import csv
from lxml import etree
import requests其中csv模块是用来将爬取的信息存入到Excel表格中
而从lxml中导入的etree模块是用来接下来进行的xpath提取
requests模块是用来向网站进行请求
2、请求头
众所周知,大部分比较完善的网站会有反爬虫机制,所以如果想要爬取该类网站信息,就必须模拟浏览器向网站发送请求,这样才能得到网站回应,爬取到所需要的数据信息。
代码如下所示:
head = {
"Cookie": "f=n; commontopbar_new_city_info=556%7C%E6%B4%9B%E9%98%B3%7Cluoyang; commontopbar_ipcity=luoyang%7C%E6%B4%9B%E9%98%B3%7C0; userid360_xml=63226CD4C488B4612A7CCA415FEE6165; time_create=1661081634551; id58=CocIJ2LOv3m4X1fRhY/DAg==; aQQ_ajkguid=3EDCDC81-7B5E-4F6F-8C2F-7DABDAFD1348; sessid=ABBD4809-9E9F-45ED-95C1-862EEAFB53D7; ajk-appVersion=; ctid=556; fzq_h=91e3ec8f25dd1406bc61b2a97f769b73_1658489614032_98fa3aa955c544e78ef3d56396c75d7b_47896385561765975701177718252511739399; 58tj_uuid=94e99d7b-f5fd-490e-9527-8d4e7244e894; new_uv=1; utm_source=; spm=; init_refer=; als=0; 58home=luoyang; f=n; new_session=0; xxzl_cid=44f564fa5d724ccd91387882f148211b; xzuid=fbd94eca-007c-4a45-b357-3f5c108e2646",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.7062 SLBChan/103"
}3、提取网站信息
代码如下所示:
baseurl = "https://{0}.58.com/ershoufang/p{1}/?PGTID=0d200001-0022-c260-609a-771473e6f2e5&ClickID=1".format(city,page)
req = requests.get(baseurl, headers = head)
req_xpath = etree.HTML(req.text)4、数据清洗
代码如下所示:
# 获取名字
housename = req_xpath.xpath('//h3[@class="property-content-title-name"]/@title')
# 获取房产链接
houselink = req_xpath.xpath('//a[@data-action="esf_list"]/@href')
# 获取建造时间
housedate = req_xpath.xpath('//p[@class="property-content-info-text"]/text()')
Housedate = ','.join(housedate)
Housedate = Housedate.replace('\n', '')
Housedate = Housedate.replace(' ', '')
HouseData = []
HouseDataend = []
hstring = ''
for i in Housedate:
hstring += i
if i == ',':
HouseData.append(hstring)
hstring = ''
for k in range(0, len(HouseData), 3):
for j in range(k+3, len(HouseData), 3):
HouseData1 = ''.join(HouseData[k:j])
HouseDataend.append(HouseData1)
break
# 获取户型
housetype = req_xpath.xpath('//p[@class="property-content-info-text property-content-info-attribute"]/span[@data-v-f11722e6]/text()')
allhousetype = []
temp = ''
for i in housetype:
temp += i
if len(temp) == 6:
allhousetype.append(temp)
temp = ''
# 获取价格
houseprice = req_xpath.xpath('//p[@class="property-price-average"]/text()')
# 获取房地产名称
houseName = req_xpath.xpath('//p[@class="property-content-info-comm-name"]/text()')
# 获取房地产地段
houseaddress = req_xpath.xpath('//p[@class="property-content-info-comm-address"]/span[@data-v-f11722e6]/text()')
Houseaddress = []
for k in range(0, len(houseaddress), 3):
for j in range(k+3, len(houseaddress),3):
houseaddress1 = "-".join(houseaddress[k:j])
Houseaddress.append(houseaddress1)
break
爬取结果如下所示:

二、csv文件的保存
一般我们从网站上爬取到的信息都要存入Excel这种表格中,才能够再存入数据库,至少我是这么做的,可能有更高明的技术人员会更简单的方法。
代码如下所示:
headers = ['房产相关信息', '房产名称' , '房产链接','户型', '价格', '建造岁月和面积等', '地段']
rows = zip(housename, houseName,houselink, allhousetype, houseprice, HouseDataend, Houseaddress)
with open(csvfilepath, 'w', encoding='utf-8', newline= '') as f:
f_csv = csv.writer(f) # 创建csv.writer对象
f_csv.writerow(headers)
for row in rows:
f_csv.writerow(row)在此我使用的是csv文件存储,当然也可以使用别的如xlwt模块等等。
三、数据库存储
1、模块导入
代码如下所示:
import pymysql
import pandas as pd
由于我使用的是mysql数据库存储,所以导入了pymysql模块,当然如果有人使用sqlite3也是可以的,没有太大影响。
而pandas模块则是用来从csv文件中提取信息存储到数据库中去的。
2、数据库连接
connect = pymysql.connect(host = "127.0.0.1", port = 3306, user = "root", 密码(password) = " ", database = "housedata", charset = "utf8" )
cursor = connect.cursor()数据库存储必须先进行数据库的连接,一般的框架和我的差不多,大家只需要按此输入自己的mysql信息即可。
3、csv文件读取
# 读取csv文件数据
csv_name = r'E:\pythonProjectSpider\house.csv'
data = pd.read_csv(csv_name, encoding = "utf-8")
data = data.where(data.notnull(), None)
Data = list(data.values)4、数据库表头创建
# 创建数据库表头
query = "drop table if exists house" # 若已有数据表hose,则删除
cursor.execute(query)
sql = "create table if not exists house(description varchar (100), housename varchar (100), houselink varchar (1000), housetype varchar (100), houseprice varchar (100), mainmessage varchar (100), houseaddree varchar (100)) default charset=utf8;"
cursor.execute(sql)
connect.commit()5、数据库信息导入
# 写入数据库
for data in Data:
for index in range(len(data)):
data[index] = '"' + str(data[index]) + '"'
sql = """insert into house values(%s)""" % ",".join(data)
cursor.execute(sql)
connect.commit()
print("植入成功")所有操作完成后记得关闭数据库,这是必要操作。
# 关闭数据库
connect.close()
cursor.close()四、爬虫完整代码
import csv
from lxml import etree
import requests
def main():
csvfilepath = 'E:\pythonProjectSpider\house.csv'
getData(csvfilepath)
def getData(csvfilepath):
head = {
"Cookie": "f=n; commontopbar_new_city_info=556%7C%E6%B4%9B%E9%98%B3%7Cluoyang; commontopbar_ipcity=luoyang%7C%E6%B4%9B%E9%98%B3%7C0; userid360_xml=63226CD4C488B4612A7CCA415FEE6165; time_create=1661081634551; id58=CocIJ2LOv3m4X1fRhY/DAg==; aQQ_ajkguid=3EDCDC81-7B5E-4F6F-8C2F-7DABDAFD1348; sessid=ABBD4809-9E9F-45ED-95C1-862EEAFB53D7; ajk-appVersion=; ctid=556; fzq_h=91e3ec8f25dd1406bc61b2a97f769b73_1658489614032_98fa3aa955c544e78ef3d56396c75d7b_47896385561765975701177718252511739399; 58tj_uuid=94e99d7b-f5fd-490e-9527-8d4e7244e894; new_uv=1; utm_source=; spm=; init_refer=; als=0; 58home=luoyang; f=n; new_session=0; xxzl_cid=44f564fa5d724ccd91387882f148211b; xzuid=fbd94eca-007c-4a45-b357-3f5c108e2646",
"user-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/92.0.4515.131 Safari/537.36 SLBrowser/8.0.0.7062 SLBChan/103"
}
city = input("请输入你要查看的城市: ")
page = input("请属于你要查询的页数: ")
baseurl = "https://{0}.58.com/ershoufang/p{1}/?PGTID=0d200001-0022-c260-609a-771473e6f2e5&ClickID=1".format(city,page)
req = requests.get(baseurl, headers = head)
req_xpath = etree.HTML(req.text)
# 获取名字
housename = req_xpath.xpath('//h3[@class="property-content-title-name"]/@title')
print(housename)
# 获取房产链接
houselink = req_xpath.xpath('//a[@data-action="esf_list"]/@href')
print(houselink)
# 获取建造时间
housedate = req_xpath.xpath('//p[@class="property-content-info-text"]/text()')
Housedate = ','.join(housedate)
Housedate = Housedate.replace('\n', '')
Housedate = Housedate.replace(' ', '')
HouseData = []
HouseDataend = []
hstring = ''
for i in Housedate:
hstring += i
if i == ',':
HouseData.append(hstring)
hstring = ''
for k in range(0, len(HouseData), 3):
for j in range(k+3, len(HouseData), 3):
HouseData1 = ''.join(HouseData[k:j])
HouseDataend.append(HouseData1)
break
print(HouseDataend)
# 获取户型
housetype = req_xpath.xpath('//p[@class="property-content-info-text property-content-info-attribute"]/span[@data-v-f11722e6]/text()')
allhousetype = []
temp = ''
for i in housetype:
temp += i
if len(temp) == 6:
allhousetype.append(temp)
temp = ''
print(allhousetype)
# 获取价格
houseprice = req_xpath.xpath('//p[@class="property-price-average"]/text()')
print(houseprice)
# 获取房地产名称
houseName = req_xpath.xpath('//p[@class="property-content-info-comm-name"]/text()')
print(houseName)
# 获取房地产地段
houseaddress = req_xpath.xpath('//p[@class="property-content-info-comm-address"]/span[@data-v-f11722e6]/text()')
Houseaddress = []
for k in range(0, len(houseaddress), 3):
for j in range(k+3, len(houseaddress),3):
houseaddress1 = "-".join(houseaddress[k:j])
Houseaddress.append(houseaddress1)
break
print(Houseaddress)
# csv文件保存
headers = ['房产相关信息', '房产名称' , '房产链接','户型', '价格', '建造岁月和面积等', '地段']
rows = zip(housename, houseName,houselink, allhousetype, houseprice, HouseDataend, Houseaddress)
with open(csvfilepath, 'w', encoding='utf-8', newline= '') as f:
f_csv = csv.writer(f) # 创建csv.writer对象
f_csv.writerow(headers)
for row in rows:
f_csv.writerow(row)
if __name__ == '__main__':
main()
五、数据库存储完整代码
import pymysql
import pandas as pd
def saveDB():
connect = pymysql.connect(host = "127.0.0.1", port = 3306, user = "root", 密码(password) = "", database = "housedata", charset = "utf8" )
cursor = connect.cursor()
# 读取csv文件数据
csv_name = r'E:\pythonProjectSpider\house.csv'
data = pd.read_csv(csv_name, encoding = "utf-8")
data = data.where(data.notnull(), None)
Data = list(data.values)
# 创建数据库表头
query = "drop table if exists house" # 若已有数据表hose,则删除
cursor.execute(query)
sql = "create table if not exists house(description varchar (100), housename varchar (100), houselink varchar (1000), housetype varchar (100), houseprice varchar (100), mainmessage varchar (100), houseaddree varchar (100)) default charset=utf8;"
cursor.execute(sql)
connect.commit()
# 写入数据库
for data in Data:
for index in range(len(data)):
data[index] = '"' + str(data[index]) + '"'
sql = """insert into house values(%s)""" % ",".join(data)
cursor.execute(sql)
connect.commit()
print("植入成功")
# 关闭数据库
connect.close()
cursor.close()
if __name__ == '__main__':
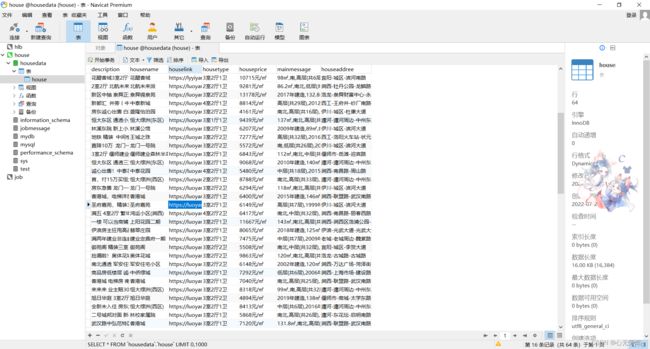
saveDB()数据库存储结果: