python/pytorch中的一些函数介绍
看cvt代码,记录里面的一些不认识的函数或功能。
1 collections.OrderedDict
包含:from collections import OrderedDict
作用:建立有序的键值对集合,也就是有序字典,可以记录键值对插入的顺序,下面是我跑的代码,顺便揭露两个瞎搞的博客,误人子弟,写的就是错的!
https://www.cnblogs.com/notzy/p/9312049.html
https://blog.csdn.net/longshaonihaoa/article/details/108469859

运行结果:

cls_cvt中有这么个方法的定义,通过OrderedDict定义了一个序列,之前写代码没有用过这个,不知道为什么,但是知道是什么意思。
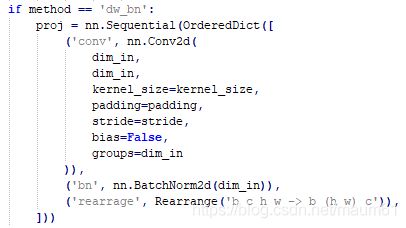
2 einops.Rearrange
大概意思能猜到,就是把对应维度重新编排。在pycharm中安装就直接进settings project interpreter,使用清华的源,搜到einops即可安装,换源或者pycharm到期请参考我博文:https://blog.csdn.net/maum61/article/details/91128782?spm=1001.2014.3001.5501
里面的字母不是固定的,只是对应维度的表示,可以随意起名
Rearrange('b c h w -> b (h w) c')

另外就是可以把对应图像块切片:

更详细的功能可参照博客:https://blog.csdn.net/csdn_yi_e/article/details/109143580
今天又尝试跑了一下rearrange,确实是优雅的操作张量,很方便:


3 torch.einsum
This function provides a way of computing multilinear expressions (i.e. sums of products) using the Einstein summation convention.
计算多维线性表达式的方法,计算确实很方便:


4 DropPath
DropPath是将深度学习模型中的多分支结构随机”删除“,
DropPath(drop_path),这里面的参数是随机dropout的概率。
5 LayerNorm
covariate shift 是分布不一致假设之下的一个分支问题,它是指源空间和目标空间的条件概率是一致的,但是其边缘概率不同。
而统计机器学习中的一个经典假设是 “源空间(source domain)和目标空间(target domain)的数据分布(distribution)是一致的”。





class LayerNorm(nn.Module):
"Construct a layernorm module (See citation for details)."
def __init__(self, features, eps=1e-6):
super(LayerNorm, self).__init__()
self.a_2 = nn.Parameter(torch.ones(features))
self.b_2 = nn.Parameter(torch.zeros(features))
self.eps = eps
def forward(self, x):
# mean(-1) 表示 mean(len(x)), 这里的-1就是最后一个维度,也就是hidden_size维
mean = x.mean(-1, keepdim=True)
std = x.std(-1, keepdim=True)
return self.a_2 * (x - mean) / (std + self.eps) + self.b_26 functools.partial
还是帮助文档的那句话,作用就是:New function with partial application of the given arguments and keywords,即:应用者给定了部分参数和关键字的新函数。注意,这是个新函数。
主要用在需要事先给定一些参数值的地方,比如,深度学习模型中,构建一个前向推理序列,有的函数需要给定一个参数,但是这个参数属于不疼不痒的,这就没必要把这个参数设置成整个模型的输入参数了,或者是你调用别人的一个功能函数,但是没注意他需要一个参数,这时候不想再改模型了,那就用这个partial自定义一个函数即可:
norm_layer = functools.partial(LayerNorm, eps=1e-5)
这个例子中,LayerNorm是torch.nn.LayerNorm,它需要设定一个很小的数,防止方差是0,但是整个定义里面也没有个初始值,这就很尴尬,那就重新写一下,把这个初始值固定为1e-5,函数名字另起为norm_layer。
7 f‘xx{i}’
这个就相当于是Qt里面的QString("xxsada %1").arg(xx) 或者是C++里面的fprintf("XXXXX %.1f", xx)等,是一个格式化的语句,{i}是个变量,用于显示的,i可以是各种数据,整型、浮点、张量等:
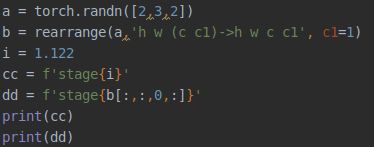
执行结果:

8 torch.squeeze
挤压掉多余的维度(只有一维的维度给去掉),并不改变有效形状,
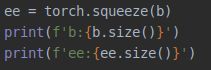
结果:
![]()
9 set()
一个新的集合对象:set() -> new empty set object

结果:
![]()
还记得最初的SSD,在caffe框架下,写模型就是用printf打印出来的模型,现在打印技术更迭了,使用f'xxx'即可,并且使用了set()集合,往里面添加。
10 torch.tensor的expand()
cls_token = nn.Parameter(torch.zeros(1, 1, 4))
print(cls_token.size())
cls_token = cls_token.expand(4,-1,-1)
print(cls_token.size())也就是沿着某一维度进行扩展,
![]()
貌似仅支持对维度为1的那一维进行扩展。
11 nn.ModuleList
这个还是很强大的,可以做一堆模块,可以枚举 enumerate访问, 也可以使用[]进行索引:
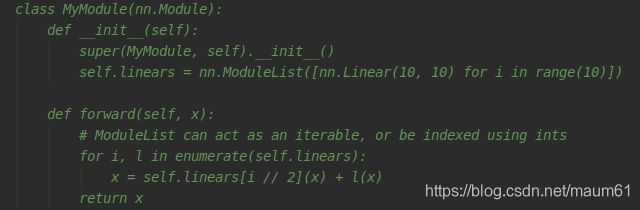
12 pytorch的类中的几个方法
class block(nn.Module):
def __init__(self, dim_in,xx,xxx):
super().__init__()
self.dim_in = 10
self.linear = nn.Linear(dim_in,xx)
def forward(self,x):
res = x
x = res + self.linear(x)
return x
每一个类都有一个初始化方法和前向推理方法,在声明类对象时需要初始化__init__方法的参数,在使用类对象时,需要输入forward方法的参数,
使用方法:
在需要调用的函数里的__init__方法里:
aa = block(4,10,10)
在需要调用的函数的forward
bb = aa(x)
13 nn.Identity()
A placeholder identity operator that is argument-insensitive

输入啥输出啥
14 nn.Linear()
带偏置的线性映射,其实就是个weight矩阵,加上一维bias。默认情况下是共享参数的,也就是[ B C H W],不管B C H 是否为1,weight的尺寸仅与W和输出维度有关:
a = torch.reshape(torch.tensor([[1., 2], [3, 4], [5, 6.],[1., 2], [3, 4], [5, 6.]]), [2, 1, 2, 3]) print(a) proj = nn.Linear(3, 1) # nn.Linear print(proj.weight) print(proj.bias) dd = proj(a) print(dd)
输出是:
tensor([[[[1., 2., 3.],
[4., 5., 6.]]],
[[[1., 2., 3.],
[4., 5., 6.]]]])
Parameter containing:
tensor([[0.0655, 0.0779, 0.1760]], requires_grad=True)
Parameter containing:
tensor([0.2570], requires_grad=True)
tensor([[[[1.0063],
[1.9644]]],
[[[1.0063],
[1.9644]]]], grad_fn=