CVPR2020超分辨率方向论文整理笔记
CVPR2020超分辨率篇
CVPR(IEEE Conference on Computer Vision and Pattern Recognition)是世界顶级的计算机视觉会议(三大顶会之一,即IEEE国际计算机视觉与模式识别会议,另外两个是ICCV和ECCV),每年一次在美国本土召开。
CVPR2020超分方向共有21篇论文,本文主要介绍了图像超分方向的10篇论文,对其中五篇做了介绍。另五篇由于使用基于参考的超分(RefSR)、生成对抗网络、无监督学习超分等等不是本人的研究方向,因此只列出对应文章的链接和摘要。
相关笔记:
- ECCV2020超分辨率方向论文整理笔记
- ICCV2019超分辨率方向论文整理笔记
- NTIRE介绍和近年来超分SR结果展示
- 图像超分辨率SR的背景概念性知识总结和几篇重要论文介绍
文章目录
-
-
- CVPR2020超分辨率篇
-
- 1. Closed-loop Matters:DRN
- 2. Correction Filter:Robustifying Off-the-Shelf Deep Super-Resolvers
- 3. CSNLN: Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining
- 4. RFA: Residual Feature Aggregation
- 5. UDVD:Unified Dynamic Convolution Network with Variational Degradations
- CVPR2020共收录10篇,其余5篇
- 总结:
-
1. Closed-loop Matters:DRN
Closed-loop Matters: Dual Regression Networks for Single Image Super-Resolution,paper,code

配对数据的双回归方案(Dual Regression Scheme for Paired Data):
现有方法只关注学习LR到HR的映射,然而可能的映射函数空间极其庞大,这使得训练非常困难。通过对LR数据引入额外的约束,作者提出双回归方案。特别得,除了学习LR → \rightarrow → HR 的映射,同时还学习了从超分辨图像SR反馈到LR图像的逆/对偶映射。
假设 x ∈ X x \in \mathcal{X} x∈X 为LR图像, y ∈ Y y \in \mathcal{Y} y∈Y 为HR图像,网络同时学习原始映射 P P P 去重建HR图像,学习对偶映射 D D D 去重建LR图像。注意,对偶映射可以看作是对底层下采样核的估计。在一般情况下,我们将SR问题化为包含两个回归任务的对偶回归方案。
原始回归任务(Primal Regression Task):寻找一个函数 P : X → Y P: \mathcal{X} \rightarrow \mathcal{Y} P:X→Y ,使预测的 P ( x ) P(x) P(x) 与其对应的HR图像 y y y 相似。
对偶回归任务(Dual Regression Task):寻找一个函数 D : Y → X D: \mathcal{Y} \rightarrow \mathcal{X} D:Y→X ,使预测的 D ( y ) D(y) D(y) 与其原始输入LR图像 x x x 相似。
作者所指的约束:原始学习任务和对偶学习任务可以形成一个闭环,为训练模型 P P P 和 D D D 提供信息监督。如果 P ( x ) P(x) P(x) 为正确的HR图像,那么下采样图像 D ( P ( x ) ) D(P(x)) D(P(x)) 应该和LR图像 x x x 非常接近。
作者指出,在这种约束下,可以减少可能映射的函数空间,使得能够更容易学到更好的重建HR图像的映射。(理论分析在原文4.2节)
损失函数:

L \mathcal{L} L 表示 L1 损失。
未配对数据的双回归方案(Dual Regression for Unpaired Data):
算法流程:

未配对数据的比例为: ρ = m / ( m + n ) \rho = m / (m+n) ρ=m/(m+n) ,作者验证当 ρ = 30 % \rho = 30 \% ρ=30% 时可获得效果最佳。(讨论在6.3节)
实验结果
4倍和8倍超分参数比较:

结果对比:

小模型:DRN-S,RCAB=30,baseChannels=16,for 4x ;RCAB=30,baseChannels=8,for 8x。
大模型:DRN-L,RCAB=40,baseChannels=20,for 4x ;RCAB=36,baseChannels=10,for 8x。
数据集:DIV2K(训练800张,验证100张,测试100张,下载(7.1G))
Flicker2K(2650张,包含人物、动物、风景, 下载(20G))
2. Correction Filter:Robustifying Off-the-Shelf Deep Super-Resolvers
Correction Filter for Single Image Super-Resolution: Robustifying Off-the-Shelf Deep Super-Resolvers,paper,code
使用现成的超分方法,使用校正滤波器改变LR图像,然后把处理后的图像输入到现成方法已训练好的模型中,在非盲超分和盲超分上验证所提方案的有效性。
Non-blind Super-resolution:下采样核和标签核都是已知的(both the downscaling kernel k k k and the target kernel k b i c u b k_{bicub} kbicub are known)
Blind Super-resolution:下采样核未知(the kernel is unknown)
结果对比:
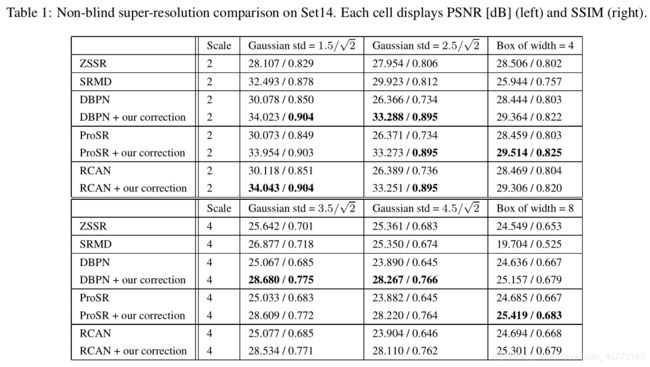
3. CSNLN: Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining
Image Super-Resolution with Cross-Scale Non-Local Attention and Exhaustive Self-Exemplars Mining,paper,code
在自然图像中,小的斑块倾向于在同一幅图像的范围内重复。因此,可以充分利用这些自相似性(Self-Similarity)提升性能。
问题:现有的方法忽略了自然图像的远距离特征相似性。最近的一些研究通过探索非局部注意模块,成功地利用了这种内在特征的相关性。然而,目前的深度模型还没有研究图像的另一个固有特性:跨尺度特征相关性。
作者提出跨尺度特征(Cross-Scale Non-Local, CS-NL)注意力模块,将其融合到循环神经网络(RNN)中。通过将新的CS-NL先验与局部和尺度内的非局部先验在一个强大的复发融合单元中结合,就可以在一张低分辨率(LR)图像中发现更多的跨尺度特征相关性。通过对所有可能先验的穷举积分,有效地提高了SISR的性能。
另外,作者提出一个强大的自样本挖掘(Self-Exemplar Mining, SEM)单元去反复融合信息。在这个单元中,通过合并局部、尺度内非局部和所提跨尺度非局部特征相关性,充分挖掘所有潜在的先验信息,并获取丰富的网络学习到的外部统计信息。
网络整体架构:

Cross-Scale NL Attention(CS-NL):与尺度内非局部模块测量像素间的相互相关性不同,CS-NL用于测量LR图像中低分辨率像素和较大尺度块之间的相关性。为了超解析LR图像,CS-NL直接利用小块去匹配这张LR图像里的每个像素。
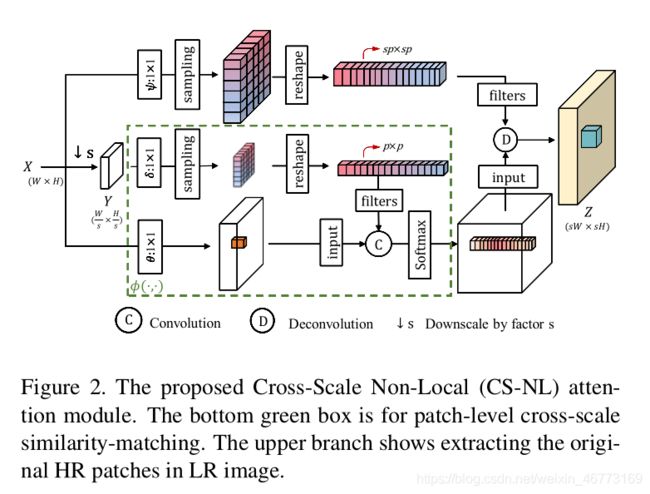
In-Scale NL Attention(IS-NL):包含一个非局部注意力模块和一个反卷积层用于放大模块的输出。本文的IS-NL是基于区域的,将特征映射划分为区域网格,在每个网格中独立地捕获相互依赖关系。这减少了计算负担。
Mutual-Projected Fusion:受到传统SR方法和DBPN的启发,采用反投影的方法,结合局部信息来规范特征,纠正重构误差。互投影操作(mutual-projected opreation)保证了融合不同特征源时的残差学习,与简单的添加或cat连接相比,使特征学习更具鉴别性。
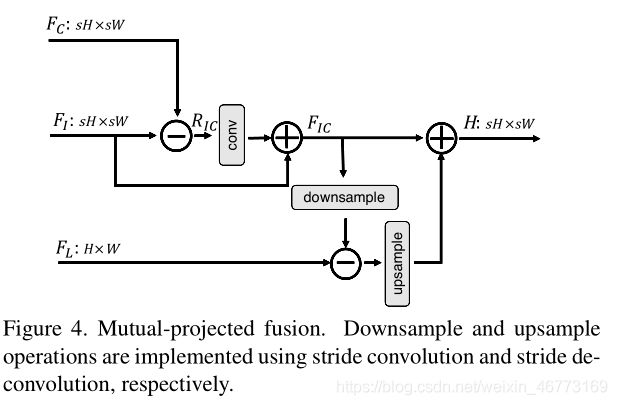
R I C = F I − F C R_{IC} = F_I - F_C RIC=FI−FC
F I C = c o n v ( R I C + F I ) F_{IC} = conv(R_{IC} + F_I) FIC=conv(RIC+FI)
d o w n s a m p l e downsample downsample:stride conv
u p s a m p l e upsample upsample:stride deconv
结果对比:


4. RFA: Residual Feature Aggregation
Residual Feature Aggregation Network for Image Super-Resolution,paper,code
文章核心:
残差特征聚合:充分利用残差分支的分级特征。RFA结构把几个残差块组合在一起,通过添加跳跃连接促进每个残差分支的特征的前向传播。
并且,为了最大化RFA结构的性能,作者进一步提出改进的空间注意力(enhanced spatial attention, ESA)块,以使残差特征更加集中于关键的空间内容。
作者的基本框架基于EDSR,只是将EDSR中残差块(residual block, RB)替换成了RFA与ESA的组合。EDSR基本框架如下:

EDSR中的RB块如Figure1(a),RFA块如Figure1(b):

RFA的细节如下:

为最大化RFA模块的有效性,作者提议将其与空域注意力机制相结合。为避免大幅增加推理耗时,轻量型注意力机制非常有必要,为确保图像复原的性能,大感受野也很有必要。结合所提两点约束,作者设计的ESA模块如下:

ESA首先通过1x1卷积进行降维以确保模块的轻量化;然后通过Stride2Conv+MaxPool(kernel=7, stride=3)进一步增大感受野;其次上采样层以回复空域分辨率;最后采用进行通道升维并通过Sigmoid层输出注意力Mask。最后,还使用跳过连接将高分辨率特征转发到空间尺寸缩小之前,直接到达块的末尾。
结果对比:


作者将RFA并入到EDSR和DenseNet,进行消融实验,结果如下:

5. UDVD:Unified Dynamic Convolution Network with Variational Degradations
Unified Dynamic Convolutional Network for Super-Resolution with Variational Degradations,paper,code
文章概述:
参考SRMD的训练数据制作方式,对训练数据进行重制作,模拟可变降质超分,提出采样多级损失的可变降质的动态卷积网络,来适应图像间(跨图像变化)和图像内(空间变化)的变化。重点:动态滤波器,多级损失。
问题描述:
现今的大多数方法都假定图像经过某种单一固定的退化,如模糊和双三次插值下采样。这种假设限制了这些方法处理多种退化方式的实际情况。而且每当退化方式改变时,例如跨图像不同的降级效果时,就必须出现训练网络。因此,SRMD提出一个单一网络去处理这种可变降质的问题,但实际上其降级方式的类型是预定义的,也即非盲设置。SFTMD是盲设置的最新方法之一,它提出了空间特征变换(Spatial Feature Transform, SFT)和迭代内核校正(Iterative Kernel Correction, IKC)来处理一组有限的盲降级问题。
网络整体结构如下:

网络的输入(Training with Variational Degradations):
为了处理降级效果的变化,希望一个统一的网络可以容纳两种类型的变化,即跨图像变化(图像间)和空间变化(图像内)。作者参考SRMD训练数据生成的方式,生成的LR和HR图像对方式为:
给定HR图像,将按以下步骤执行降级处理:应用大小为p×p的各向同性高斯模糊核,对图像进行双三次下采样,最后添加具有噪声水平σ的AWGN。生成的LR图像的尺寸为C×H×W。为了降低维数使用主成分分析(PCA)技术将模糊核投影到t维矢量。然后,我们将噪声级 σ 的额外维度连接起来以获得(1 + t)向量,再将此类矢量拉伸以获得大小为(1 + t)×H×W的退化图D。最后,将LR图像 I 0 I^0 I0 与大小为(C +1 + t)×H×W的退化图D连接起来。注意,默认情况下 t 设置为15。
特征提取(Feature Extraction Network):
采样EDSR中的特征提取结构,即残差块的叠加。
特征提纯和复原(Refinement Network):
这是本文的重点,也是和SRMD不同的地方。该部分包含三个动态滤波器卷积模块,每个模块以待处理图像、前一步提取的特征作为输入。首先,对待处理图通过三个卷积进一步提取特征;然后,将其与特征提取部分的特征Concat;其次,将前述特征分别进行残差图测试与动态滤波器卷积核预测;最后将签署预测动态滤波器卷积核与待处理图像进行逐点卷积计算并预测残差图相加得到输出。
动态滤波器

上图给出了两种类型的动态滤波器卷积,前者不涉及分辨率上采样,我们暂且称之为常规动态滤波器卷积,后者涉及分辨率上采样,我们暂且称之为上采样动态滤波器卷积。
对于常规动态滤波器卷积,其计算公式定义如下:

其中,表示位置处的卷积核。这也是它与常规卷积的不同之处,常规卷积的卷积核全局共享,而动态滤波器卷积中的卷积核则是逐点不同。与此同时,卷积核又可以根据计算方式的不同而有不同的配置方式(比如标准卷积模式、DepthwiseConv模式,作者默认选用DepthwiseConv)。
对于上采样动态滤波器卷积,其计算公式定义如下:
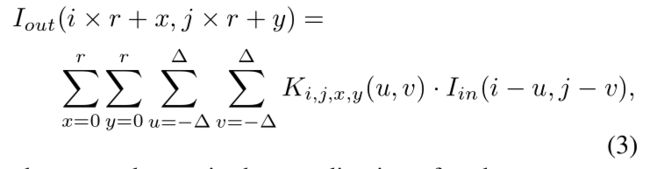
多级损失
在损失函数方面,类似LapSRN与ProSR,作者采用多阶段损失,即每个动态卷积模块的输出均需要计算损失。损失函数定义如下:

其中,M为动态滤波器的数量,F是损失函数,可以选择L2或者感知损失等。在这里选用了L2损失。
注意:从上述公式,其实可以确认:提纯复原部分的三个动态滤波器卷积模块的第一个为上采样动态滤波器卷积,后两个为常规动态滤波器卷积。
结果对比:

上表总结了不同UDVD配置下的性能对比。其中baseline基本等同于EDSR。D表示常规动态滤波器卷积,U表示上采样动态滤波器卷积。从中可以看出:(1)动态滤波器卷积取得了优于EDSR类方法的性能;(2) UDD组合则具有最佳性能,说明Refinement模块还是有一些必要性的;(3)多阶段损失监督有助于提升模型性能。
CVPR2020共收录10篇,其余5篇
Robust Reference-based Super-Resolution with Similarity-Aware Deformable Convolution,paper
摘要: 在本文中,我们针对基于参考的超分辨率(RefSR)任务提出了一种新颖且高效的参考特征提取模块,称为相似性搜索和提取网络(SSEN)。所提出的模块从参考图像中提取对齐的相关特征,以提高单图像超分辨率(SISR)方法的性能。与利用蛮力搜索或光流估计的常规算法相比,所提出的算法无需任何额外的监督或繁重的计算即可端到端训练,并通过单个网络前向操作预测最佳匹配。此外,所提出的模块不仅知道最佳匹配位置,而且还知道最佳匹配的相关性。当给出不相关的参考图像时,这使我们的算法具有较强的鲁棒性,克服了使用现有RefSR方法时性能下降的主要原因。此外,如果没有参考图像可用,我们的模块可用于自相似性SR。实验结果证明了该算法在定量和定性上均优于以往的算法。
Learning Texture Transformer Network for Image Super-Resolution,paper
摘要: 我们研究图像超分辨率(SR),其目的是从低分辨率(LR)图像中恢复逼真的纹理。通过将高分辨率图像用作参考(Ref),已取得了最新进展,因此可以将相关纹理转移到LR图像。但是,现有的SR方法忽略了使用注意力机制从Ref图像转移高分辨率(HR)纹理的情况,这在挑战性情况下限制了这些方法。在本文中,我们提出了一种新颖的用于图像超分辨率的纹理变压器网络(TTSR),其中将LR和Ref图像分别表示为变压器中的查询和关键字。 TTSR由四个紧密相关的模块组成,这些模块针对图像生成任务进行了优化,包括DNN可学习的纹理提取器,相关性嵌入模块,用于纹理传输的硬注意力模块和用于纹理合成的软注意力模块。这种设计鼓励在LR和Ref图像之间进行联合特征学习,其中可以通过注意发现深层特征对应关系,从而可以传递准确的纹理特征。所提出的纹理变换器可以以交叉比例的方式进一步堆叠,这使得能够从不同级别(例如,从1x到4x放大)恢复纹理。大量的实验表明,TTSR在最新的定量和定性评估方面都取得了显着进步。可以从https://github.com/researchmm/TTSR下载源代码。
Deep Unfolding Network for Image Super-Resolution,paper
摘要: 基于学习的单图像超分辨率(SISR)方法比传统的基于模型的方法不断显示出卓越的有效性和效率,这在很大程度上是由于端到端的培训。但是,与基于模型的方法可以在不同的比例因子下处理SISR问题,在统一的MAP(最大后验)框架下模糊内核和噪声水平不同,基于学习的方法通常缺乏这种灵活性。为了解决这个问题,本文提出了一种端到端的可训练展开网络,该网络同时利用了基于学习的方法和基于模型的方法。具体地,通过经由半二次分裂算法展开MAP推断,可以获得由交替求解数据子问题和先前子问题组成的固定数量的迭代。然后可以使用神经模块解决这两个子问题,从而形成端到端的可训练迭代网络。结果,所提出的网络继承了基于模型的方法的灵活性,可以通过单个模型超级分辨不同比例因子的模糊,嘈杂的图像,同时保持基于学习的方法的优势。大量的实验证明了所提出的深度展开网络在灵活性,有效性以及通用性方面的优越性。
Unpaired Image Super-Resolution using Pseudo-Supervision,paper
摘要: 在关于基于学习的图像超分辨率(SR)的大多数研究中,通过使用预定操作(例如双三次)对高分辨率(HR)图像按比例缩小来创建配对的训练数据集。但是,这些方法无法超分辨真实世界的低分辨率(LR)图像,对于这些图像,其降级过程更加复杂且未知。在本文中,我们提出了一种使用生成对抗网络的不成对SR方法,该方法不需要成对/对齐的训练数据集。我们的网络由不成对的内核/噪声校正网络和伪成对的SR网络组成。校正网络去除噪声并调整输入的LR图像的内核;然后,通过SR网络将校正后的干净LR图像放大。在训练阶段,校正网络还从输入的HR图像生成伪清洁的LR图像,然后SR网络以配对的方式学习从伪清洁的LR图像到输入的HR图像的映射。由于我们的SR网络独立于校正网络,因此可以将经过充分研究的现有网络体系结构和逐点丢失函数与提出的框架集成在一起。在各种数据集上进行的实验表明,该方法优于现有的解决方案,适用于不成对的SR问题。
EventSR: From Asynchronous Events to Image Reconstruction, Restoration, and Super-Resolution via End-to-End Adversarial Learning,paper
摘要: 事件相机感应强度变化,并且比传统相机具有许多优势。为了利用事件摄像机,已经提出了一些从事件流中重建强度图像的方法。但是,输出仍处于低分辨率(LR),嘈杂且不切实际的情况。低质量的输出限制了事件相机的广泛应用,其中需要高空间分辨率(HR)以及高时间分辨率,动态范围和无运动模糊。当没有地面真实(GT)HR图像和下采样内核可用时,我们考虑从LR事件重构和超分辨强度图像的问题。为了解决这些挑战,我们提出了一种新颖的端到端方法,该方法可从事件流中重建LR图像,增强图像质量并对增强的图像进行升采样,称为EventSR。如果没有真实的GT图像,我们的方法主要是无监督的,部署对抗性学习。为了训练EventSR,我们创建了一个包含真实场景和模拟场景的开放数据集。使用这两个数据集可提高网络性能,并且每个阶段的网络体系结构和各种损失函数有助于提高图像质量。整个流程分为三个阶段进行训练。虽然每个阶段主要用于三个任务之一,但早期阶段的网络将通过端到端的方式分别通过损耗功能进行微调。实验结果表明,EventSR可从事件中为模拟数据和真实数据重建高质量的SR图像。有关实验的视频,请访问https://youtu.be/OShS_MwHecs。
总结:
第一篇论文DRN采样UNet结构,创新的一点是将主网络生成的图再进行下采样,学习从超分辨图像SR反馈到LR图像的逆/对偶映射,损失为计算主网络SR与HR损失和计算回归网络对SR进行下采样的图像与其原始输入LR图像 ,形成一个闭环。个人感觉这其实可以将双监督学习,分别监督网络的输出和输入。
第二篇论文是现成方法已训练好的模型中,仅仅是通过使用校正滤波器改变LR图像(网络的输入),就获得性能的提升,是一个不错的工作。
第三篇论文创新点在于提出了跨尺度非局部注意力和自样本挖掘机制,作者并非是跟以前方法一样,在残差块后面添加一个注意力块,而是直接将注意力块作为基本块,这个想法很新颖。网络仅用3M参数就获得比拟SAN的性能。
第四篇论文网络框架基于EDSR,其将EDSR中多个残差块加入块间的残差连接,然后加入空间注意力模块,没有过于新颖的地方,性能超过了RCAN和SAN。
第五篇论文网络框架类似于EDSR,借鉴SRMD的数据制作方式,对LR图像注入多级高斯噪声以模拟可变降质图像,对训练数据进行重制作,然后在重建部分采样动态滤波器提高其对可变降质图像的特征提取灵活性,并对每个动态滤波器的输出计算损失,这种多级损失的方式也是本文的亮点。