PaddleOCR文字识别实践(一)
1、PaddleOCR介绍
百度深度学习框架PaddlePaddle开源的OCR项目PaddleOCR旨在打造一套丰富、领先、且实用的OCR工具库,助力使用者训练出更好的模型,并应用落地。PaddleOCR包含丰富的文本检测、文本识别以及端到端算法。
PaddleOCR特性:
- 超轻量级中文OCR模型,总模型仅8.6M
- 单模型支持中英文数字组合识别、竖排文本识别、长文本识别
- 检测模型DB(4.1M)+识别模型CRNN(4.5M)
- 实用通用中文OCR模型
- 多种预测推理部署方案,包括服务部署和端侧部署
- 多种文本检测训练算法,EAST、DB、SAST
- 多种文本识别训练算法,Rosetta、CRNN、STAR-Net、RARE、SRN
- 可运行于Linux、Windows、MacOS等多种系统
PaddleOCR项目地址:https://github.com/PaddlePaddle/PaddleOCRGitHub - PaddlePaddle/PaddleOCR: Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices) https://github.com/PaddlePaddle/PaddleOCR
https://github.com/PaddlePaddle/PaddleOCR
2、PaddleOCR项目实践过程
2.1 运行环境
本次实践所用的测试环境为:
os:Win10;
Python:3.6.8;
2.2 运行依赖库安装
2.2.1 安装PaddlePaddle
PaddleOCR需在PaddlePaddle下才可以正常运行,开始之前请确保PaddlePaddle已经安装,具体安装过程如下:
如果机器上安装的是CUDA9或CUDA10,请运行以下命令安装GPU版:
python3 -m pip install paddlepaddle-gpu -i https://mirror.baidu.com/pypi/simple如果机器是CPU,请运行以下命令安装CPU版:
python3 -m pip install paddlepaddle -i https://mirror.baidu.com/pypi/simple本文采用的是CPU2.0版,可用以下命令直接安装:
python3 -m pip install paddlepaddle==2.0.0 -i https://mirror.baidu.com/pypi/simple(若要在GPU模式下使用除了有GPU外还需要安装CUDA 10.1和CUDNN对应文件,可自行上网百度。)
2.2.2 PaddleOCR安装
关于PaddleOCR的安装,可以直接在github上以压缩包的形式下载,如下图,然后解压到某一位置即可。项目地址:GitHub - PaddlePaddle/PaddleOCR: Awesome multilingual OCR toolkits based on PaddlePaddle (practical ultra lightweight OCR system, support 80+ languages recognition, provide data annotation and synthesis tools, support training and deployment among server, mobile, embedded and IoT devices)https://github.com/PaddlePaddle/PaddleOCR 亦可以用git clone命令把项目仓库直接下载到本地:
git clone https://github.com/PaddlePaddle/PaddleOCR本文中是直接下载的压缩包。
本文中选择的是PaddleOCR2.4,解压后的文件如下图所示:
2.2.3 第三方依赖库
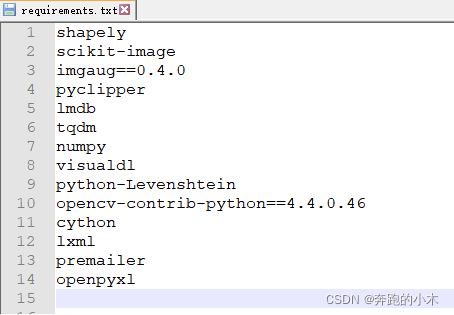
PaddleOCR的运行还需要一些第三方依赖库,在requirement.txt文件中,如下图所示,可执行以下命令进行安装:
pip3 install -r requirements.txt(个别的第三方库可能会下载失败或报错,可进行单独安装。)
2.2.4 模型下载
PaddleOCR提供的可下载模型包括推理模型、训练模型、预训练模型、slim模型,模型区别说明如下:

本项目中下载的均为推理模型,下载的是中英文通用PP-OCR server模型(143.4M),如图所示。

下载到本地之后分别进行解压,创建一个models文件夹,把下载好的模型文件解压到该models文件夹中,并将models文件夹放入到PaddleOCR根目录下。最终目录结构如下所示:

2.2.5 文字识别测试
测试程序如下所示:
from paddleocr import PaddleOCR
import cv2
import numpy as np
from PIL import Image, ImageDraw, ImageFont
from paddleocr import PaddleOCR, draw_ocr
font=cv2.FONT_HERSHEY_SIMPLEX
#Paddleocr目前支持中英文、英文、法语、德语、韩语、日语,可以通过修改lang参数进行切换
#参数依次为`ch`, `en`, `french`, `german`, `korean`, `japan`。
ocr = PaddleOCR(use_angle_cls=True, lang="ch",use_gpu=False,
rec_model_dir='./models/ch_ppocr_server_v2.0_rec_infer/',
cls_model_dir='./models/ch_ppocr_mobile_v2.0_cls_infer/',
det_model_dir='./models/ch_ppocr_server_v2.0_det_infer/') # need to run only once to download and load model into memory
img_path = './00077949.jpg'
result = ocr.ocr(img_path, cls=True)
# 显示结果
from PIL import Image
image = Image.open(img_path).convert('RGB')
boxes = [line[0] for line in result]
txts = [line[1][0] for line in result]
scores = [line[1][1] for line in result]
im_show = draw_ocr(image, boxes, txts, scores, font_path='./simfang.ttf')
im_show = Image.fromarray(im_show)
im_show.save('./result.png')测试结果如下:


参考文献:
- PaddleOCR,一款文本识别效果不输于商用的Python库! - 知乎
- 让OCR更简单 | PaddleOCR+OpenCV实现文字识别步骤与代码演示_Color Space的技术博客_51CTO博客