【生成对抗网络】GAN生成对抗网络理论知识
GAN生成对抗网络目录
-
- 引入Generator
-
- Network as Generator
- 为什么要训练Generator:需要输出是分布
- 引入GAN
-
- Basic Idea of GAN:
- 区分Unconditional generation 与 Conditional generation
-
- Unconditional generation
- Conditional generation
- 引入Discriminator
- Generator、Discriminator算法训练:
-
- Step 1:定住Generator,只 train Discriminator
- Step 2:定住Discriminator,只 train Generator
- Step 3:反复训练
- GAN理论部分(Theory behind GAN)
-
- 想minimize P d a t a P_{data} Pdata和 P G P_{G} PG的 Divergence
- 怎么计算Divergence(两个分布之间的某种距离)
- GAN理论部分(Theory behind GAN)小结:
- GAN训练的小Tips
-
- WGAN
-
- JS Divergence存在的问题
- 使用Wasserstein distance代替JS Divergence
- Wasserstein distance计算方法
- 其他Tips
- GAN应用于Sequence Generation的问题(生成文字)
- 其他Generative Models
-
- Variational Autoencoder(VAE)
- Flow-based Model
- 使用监督学习的方法
- GAN的评价指标(Evaluation of Generation)
-
- Mode Collapse 和 Mode Dropping 问题
- 衡量指标Incention Score和Incention Distance
- 衡量指标出现的其他问题
引入Generator
之前的 network 都是一个 function,给一个 x 输出一个 y
Network as Generator
network 的输入会加上一个 random 的 variable(Z),其中 Z 是从某一个 distribution sample 出来的。
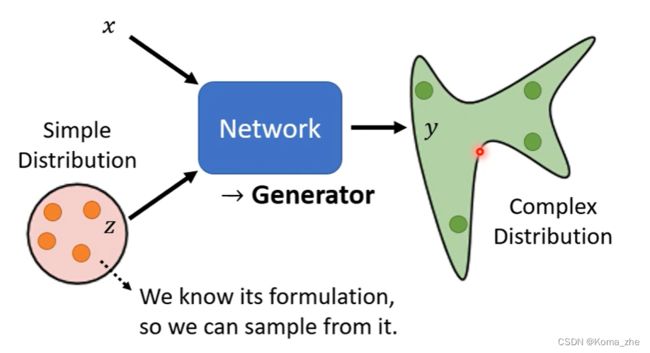
注:
1、可以 input 的一样长的 X、Z 相加或者向量连接为长向量也可以,输入到 network 。2、其中 Z 是不固定的,每一个使用 network 都会随机生成一个 Z(每次都不一样)。
3、其中的限制:distribution 够简单(知道公式),可以从 distribution 做 sample,distribution 可以是 gaussian distribution 或者 uniform distribution 。
4、可以输出一个 distribution 的 network 称为 Generator 。
为什么要训练Generator:需要输出是分布
当任务需要一点创造力的时候(想找一个 function ,在同样的输入有多种可能的输出,而且不同输出都是对的)例如:Drawing、Chatbot 。
引入GAN
Generator model 最出名就是 Generative Adversarial Network(GAN)。
GAN 有各式各样的变形:ACGAN、BGAN、CGAN、DCGAN、EBGAN、FGAN、GoGAN…(the-gan-zoo)
Basic Idea of GAN:
演化的故事:枯叶蝶对应就是Generator,它的天敌比比鸟就是Discriminator。Generator 要画出二次元人物骗过 Discriminator(对抗的关系)
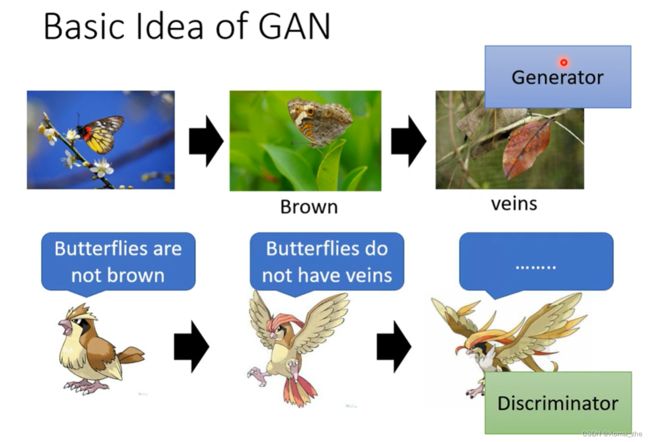
以生成动漫人物人脸为例子:
区分Unconditional generation 与 Conditional generation
Unconditional generation
举例:让机器生成动画二次元人物的脸(Unconditional generation)
Unconditional generation :先把 x 拿掉(Conditional generation再把 x 加回来),所以 Generator 的输入是 Z ,输出是 y (输入的 Z 是从一个 normal distribution (不一定得是这个)sample 出来的向量,通常是 Low-dim vector ,维度是自己定的;y 是一个二次元人物的脸,是 high-dim vector)。

Conditional generation
Conditional generation再把 x 加回来,根据Condition x 和 z 来产生 y。
应用:Text-to-image(文字对图片的生成)、Image Traslation (也称为pix2pix)根据图片生成图片…
Text-to-image也是一个 Supervised Learning 的问题。
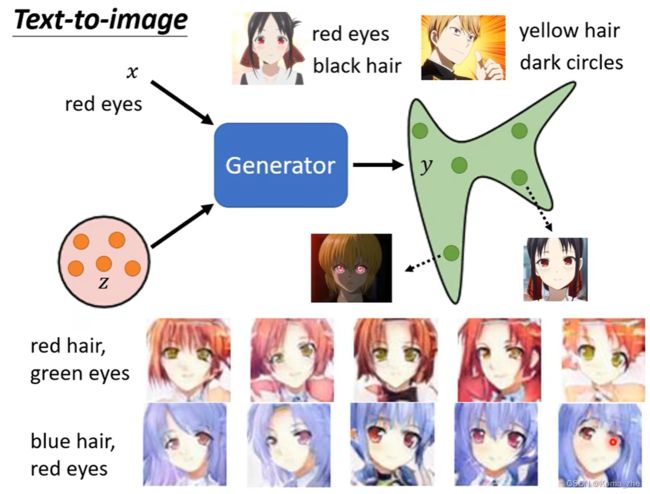
Conditional generation 出现的问题
Generator只要产生图片骗过Discriminator,不必管 x 的文字是什么。

解决方法:输入到Discriminator不只是图片 y ,还有 x。训练这样的Discriminator需要文字跟影像成对的资料(Pair Data)

引入Discriminator
GAN 中,除了 Generator,还需多训练一个 Discriminator。
Discriminator:(本身也是一个 network ,也是一个 function )
它会拿一张图片作为输入,输出是一个 Scalar(数值),Scalar 越大说明输入的图片越像真实的二次元人物的图像。
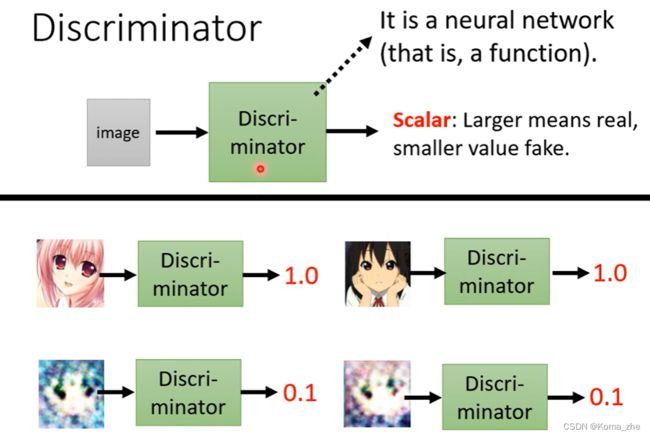
注:
Generator、Discriminator 的 neural network 架构都是可以自己设计(可以用CNN、Transformer都可以)
Generator、Discriminator算法训练:
Generator、Discriminator就是两个network,network在训练前需对参数进行初始化。
Step 1:定住Generator,只 train Discriminator
一开始Generator的参数是随机初始化的,此时固定住等于啥也没做,此时输入一堆向量,输出乱七八糟的图片(杂讯),从gaussian distribution里去random sample一堆vector输入到Generator(这些图片与正常二次元人物非常不像);database有很多二次元人物头像sample一些头像,拿真正的与Generator产生的结果去训练Discriminator。Discriminator训练的目标就是分辨真正的二次元人物与Generator产生的之间的差异。(可能会将真正的标为1,Generator产生的标位0,Discriminator做分类或回归)
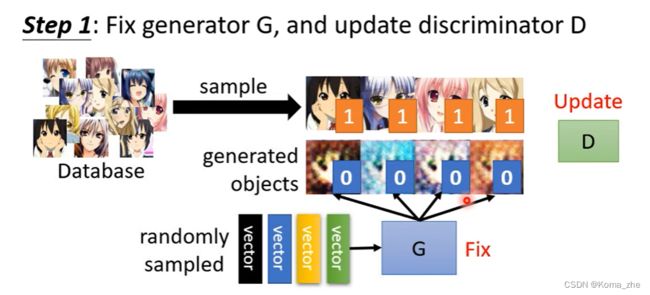
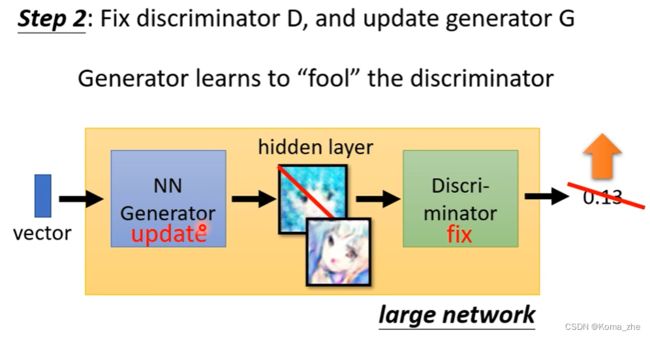
Step 2:定住Discriminator,只 train Generator
目标:让Generator想方法去骗过Discriminator。
Generator从gaussian distribution sample 一个vector作为输入,产生一个图片,然后丢到 Discriminator给一个Scalar (Discriminator 参数是固定的,只会调整Generator的参数)
Generator调整参数使得输出的让Discriminator给高分(训练 Generator 调整参数也是使用 gradient descent 的方法)
Step 3:反复训练

注(其他):
StyleGAN(19年)产生的动漫头像很逼真,ProgressiveGAN产生真实的人脸。
GAN的Generator就是输入一个向量输出一张图片,还可以把输入的向量做内插(interpolation),可以看到两张图片之间连续的变化。
GAN理论部分(Theory behind GAN)
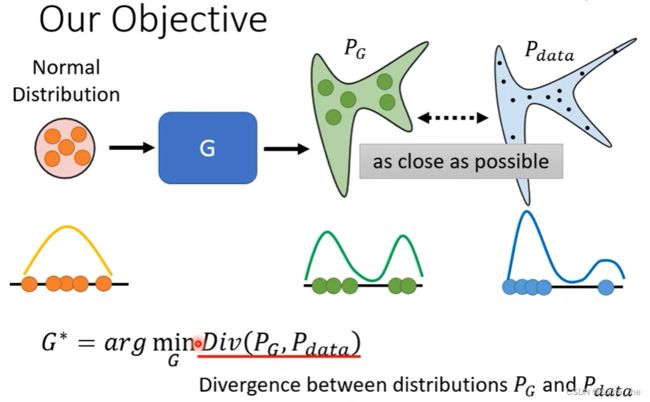
想minimize P d a t a P_{data} Pdata和 P G P_{G} PG的 Divergence
vector 通过 Normal Distribution ——> Generators ——> Distribution(复杂,称为 P G P_G PG)
P G P_G PG 与真正的data形成的 Distribution (称为 P d a t a P_{data} Pdata)求Divergence(期待 P G P_G PG 和 P d a t a P_{data} Pdata 越接近越好 Divergence(两个分布之间的某种距离))
实质:找一个
Loss function(找一个 G G G 使得 P G P_G PG 和 P d a t a P_{data} Pdata 的 Divergence 越小越好)(例如KL Divergence、JS Divergence)
怎么计算Divergence(两个分布之间的某种距离)
GAN很好的突破了怎么计算Divergence的问题。
GAN思路:只要知道怎么从 P G P_G PG , P d a t a P_{data} Pdata 这两个Distribution Sample东西出来,就有办法计算Divergence。不需要实际知道 P G P_G PG , P d a t a P_{data} Pdata的公式。

借助 Discriminator 计算 Divergence:
一大堆的real data(从 P d a t a P_{data} Pdata Sample出来的结果),也有一大堆 generative data(从 P G P_G PG Sample出来的结果)。根据real data和generative data训练一个Discriminator,目标:看到real data就给比较高的分数,看到generative data给低分。
上述过程可以视为一个 Optimization 的问题,这个问题就是要训练一个Discriminator,可以去maximize某一个function(Objective Function)(minimize的function称为Loss Function)。
希望从 P d a t a P_{data} Pdata Sample的 D ( y ) D(y) D(y) 越大越好,希望从 P G P_{G} PG Sample的 D ( y ) D(y) D(y) 越小越好。原来的 Objective Function 写成这样是为了Discriminator和二元分类扯上关系,这个 Objective Function 就是 cross entropy 乘一个负号。
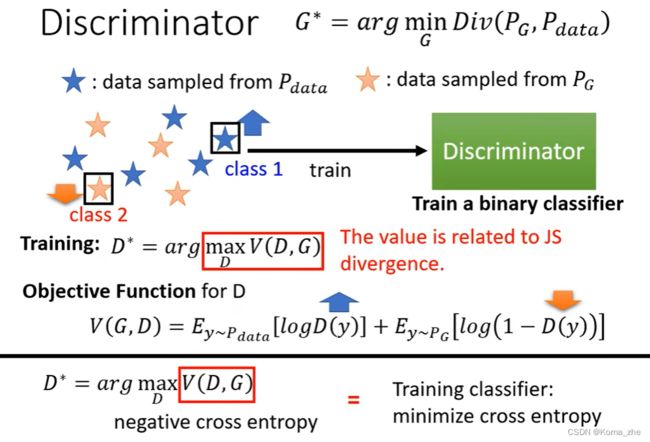
注:
Objective Function的最大值跟JS Divergence有关。
总结:不知道怎么计算 Divergence,但是train Discriminator,train完后看看 Objective Function 可以到多大,这个值就跟 Divergence 有关。
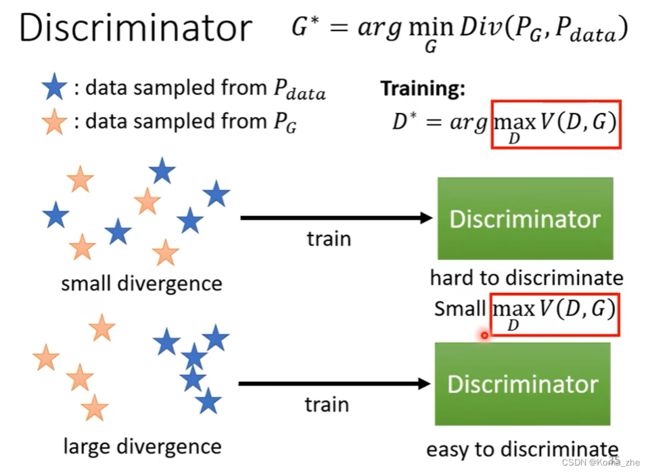
GAN理论部分(Theory behind GAN)小结:
本来的目标:找一个 Generator 去minimize P G P_G PG 和 P d a t a P_{data} Pdata 的 Divergence
因为不知道怎么计算 Divergence :训练一个 Discriminator,训练完后 Objective Function 的最大值就是跟JS Divergence有关。
注:可以改Objective Function 来换为其他的 Divergence。
paper:f-GAN: Training Generative Neural Samplers using Variational Divergence Minimization 列举了不同的 Divergence 需如何设计 Objective Function 去找 maximum value)

GAN训练的小Tips
GAN is difficult to train.
WGAN
WGAN就是使用Wasserstein distance取代JS Divergence的 GAN 。
JS Divergence存在的问题
JS Divergence的问题: P G P_G PG 和 P d a t a P_{data} Pdata 往往重叠的部分非常少 !
理由1、data本身特性( P G P_G PG 和 P d a t a P_{data} Pdata 是高维空间的低维的manifold,例如二维空间的线,重叠的很少)。
理由2、 P G P_G PG 和 P d a t a P_{data} Pdata 都是Sample出来的,可能Sample得不合理。

注:两个没有重叠的分布,
JS Divergence算出来永远都是 l o g 2 log2 log2(不管分布长什么样)。
当使用JS Divergence时,训练 binary classifier 去分辨 real image 和 generative image 的时候,正确率是100%,所以在GAN训练过程binary classifier的 loss 或者 accuracy 都没有意义。

使用Wasserstein distance代替JS Divergence
解决方法:既然是JS Divergence的问题,换一个衡量两个 distribution 的相似程度的方式(换一种Divergence)
,使用Wasserstein distance(也称为Earth Mover Distance(EMD))
注:
Wasserstein distance会穷举所有的 Moving Plans ,看哪一个 “推土” 的方法让平均距离最小,取最小值。(一个 Optimization 问题)
Wasserstein distance计算方法
max D ∈ 1 − L i p s c h i t z { E y ∼ P d a t a [ D ( y ) ] − E y ∼ P G [ D ( y ) ] } \max\limits_{D\in1-Lipschitz} {\{ ~E_{y\sim P_{data}}[D(y)]-E_{y\sim P_{G}}[D(y)]~\}} D∈1−Lipschitzmax{ Ey∼Pdata[D(y)]−Ey∼PG[D(y)] }
解上述式子解完就是 P d a t a P_{data} Pdata 和 P G P_{G} PG 的Wasserstein distance。
对式子进行解释:
其中 y y y 如果从 P d a t a P_{data} Pdata 中来的,要计算 D ( y ) D(y) D(y) 的期望值, y y y 如果从 P G P_{G} PG中来的,要计算 D ( y ) D(y) D(y) 的期望值,再乘上一个负号。
D D D 不能是一个随便的 Function,必须是一个1-Lipschitz 的 Function,意思就是 D D D 是一个足够平滑的 Function。
若 D D D 不是一个足够平滑的 Function。只看大括号中,只想要 D ( y ∼ d a t a ) D({y_{\sim data})} D(y∼data) 越大越好, D ( y ∼ G ) D({y_{\sim G})} D(y∼G) 越小越好(没有重叠),Discriminator会给 real image 打 ∞ ∞ ∞,给 generated image 打 − ∞ -∞ −∞,导致 training 无法收敛,算出来 max D ∈ 1 − L i p s c h i t z { E y ∼ P d a t a [ D ( y ) ] − E y ∼ P G [ D ( y ) ] } \max\limits_{D\in1-Lipschitz} {\{ ~E_{y\sim P_{data}}[D(y)]-E_{y\sim P_{G}}[D(y)]~\}} D∈1−Lipschitzmax{ Ey∼Pdata[D(y)]−Ey∼PG[D(y)] }就是无限大。

怎么确保 Discriminator 一定符合 D ∈ 1 − L i p s c h i t z D\in1-Lipschitz D∈1−Lipschitz :
思路:
一、最早的WGAN paper(Original WGAN思路是修改 Weight): 训练网络时,训练的参数 w w w 放于 c c c 与 − c -c −c 之间, i f if if w > c w>c w>c, w = c w=c w=c; i f if if w < − c w<-c w<−c; w = − c w=-c w=−c(不一定真的能使Discriminator变成 1-Lipschitz 的 Function )。
二、paper:Improved WGAN :思路是 Gradient Penalty:使用方法Spectral Normalization( SNGAN ) 限制 D ∈ 1 − L i p s c h i t z D\in1-Lipschitz D∈1−Lipschitz ( Keep gradient norm smaller than 1 everywhere )。
其他Tips
- Tips from Soumith
https://github.com/soumith/ganhacks- Tips in DCGAN: Guideline for network architecture designfor image generation
https://arxiv.org/abs/1511.06434.- lmproved techniques for training GANs
https://arxiv.org/abs/1606.03498.- Tips from BigGAN
https://arxiv.org/abs/1809.11096
GAN应用于Sequence Generation的问题(生成文字)
训练 GAN 最难的就是拿 GAN 来生成文字
生成文字是一个 Seq2seq 模型 Decoder会产生一段文字(Seq2seq 模型就是Generator,Decoder扮演Generator角色)
问题难点:若用 gradient descent 去训练Generator(Decoder),让 Discriminator 输出分数越大越好做不到。因为小小变化改变了Decoder的参数,输出的 Distribution也会小小变化,但是对取 max 分布的 Token 无影响,对Discriminator 的输出没有影响。
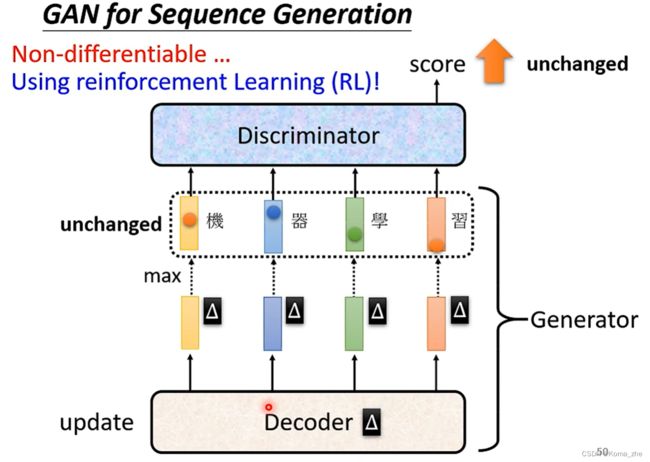
注:遇到 gradient descent 的问题可以使用
reinforcement Learning(RL)硬做,但是在此问题上,二者都比较难训练。
解决方法:Training language GANs from Scratch ( paper ) 不用预训练,但需大量调参和 tips。引入 SeqGAN-step 技术,需要很大的 batch size…
其他Generative Models
Variational Autoencoder(VAE)
Flow-based Model
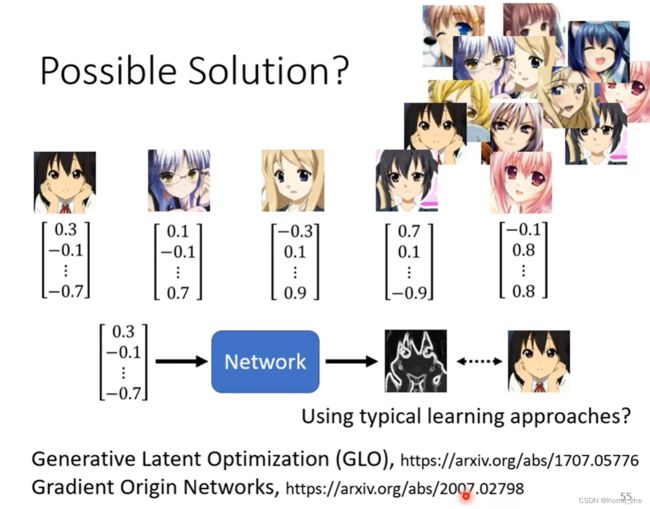
使用监督学习的方法
重点是图片对应随机的 vector 训练起来结果比较差。要特殊的方法处理这些 vector 。
GAN的评价指标(Evaluation of Generation)
思路:训练一个影像的分类器。

Mode Collapse 和 Mode Dropping 问题
光使用这个做法会让Mode Collapse的问题骗过去
Mode Collapse:Generative model 输出的图片来来去去都是那几张。

Mode Dropping的问题:产生出来的资料的分布只是真实资料分布的一部分。

评估的参数:
Quality:只看一个图片,一个图片输入进Classifier的时候,分布有没有非常集中,越集中 Quality 越大
Diversity:看一堆图片,看分布的平均,总的越平均 Diversity 越大。
衡量指标Incention Score和Incention Distance
Incention Score(IS):分类器 CNN 是用一个 Trip 来做的, Quality 高且 Diversity 大, Incention Score就越大。
Frechet Incention Distance :
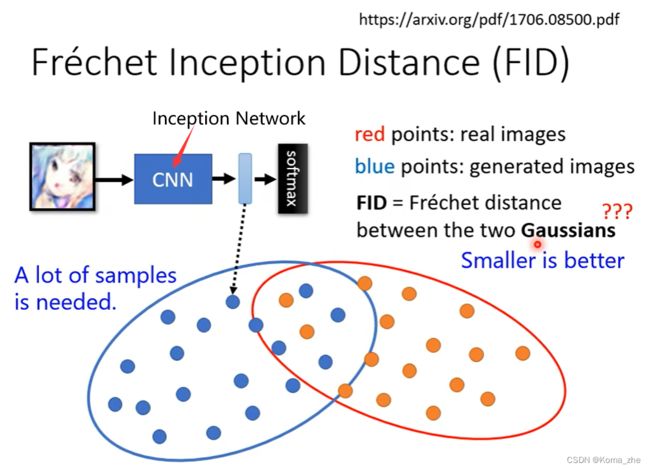
paper:Are GANs Created Equal? A Large-Scale Study
注:
FID存在的问题:
一、输出的分布当做 Gaussians Distribution 可能存在问题。
二、要准确得到 Network 的分布,可能需要大量 Sample 。
三、实际操作可能会参考FID和例如动漫人物人脸检测出的数目等其他指标。
衡量指标出现的其他问题
Real Data 和 Generated Data 一模一样(计算的FID非常小,或者人脸辨识系统也打高分)

paper:Pros and cons of GAN evalustion measures 列举了20几种GAN Generator的评估方式