基于逻辑回归模型的信用卡欺诈检测
基于逻辑回归模型的信用卡欺诈检测
1. 项目概况
某银行为提升信用卡反欺诈检测能力,提供了脱敏后的一份个人交易记录。考虑数据本身的隐私性,数据提供之初已经进行了类似PCA的处理,并得到了若干数据特征。在不需要做额外特征提取工作的情况下,本项目意在通过逻辑回归模型的调优,得到较为准确可靠的反欺诈检测方法,分析过程中使用到了Python Pandas, Numpy, Matplotlib, Seaborn以及机器学习库Scikit-Learn等。
2. 数据前处理
import pandas as pd
import numpy as np
import matplotlib.pyplot as plt
%matplotlib inline
import seaborn as snsdata = pd.read_csv('creditcard.csv')信用卡数据预览
data.head()
.dataframe tbody tr th:only-of-type { vertical-align: middle; } .dataframe tbody tr th { vertical-align: top; } .dataframe thead th { text-align: right; }
| Time | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | … | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Amount | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | 0.0 | -1.359807 | -0.072781 | 2.536347 | 1.378155 | -0.338321 | 0.462388 | 0.239599 | 0.098698 | 0.363787 | … | -0.018307 | 0.277838 | -0.110474 | 0.066928 | 0.128539 | -0.189115 | 0.133558 | -0.021053 | 149.62 | 0 |
| 1 | 0.0 | 1.191857 | 0.266151 | 0.166480 | 0.448154 | 0.060018 | -0.082361 | -0.078803 | 0.085102 | -0.255425 | … | -0.225775 | -0.638672 | 0.101288 | -0.339846 | 0.167170 | 0.125895 | -0.008983 | 0.014724 | 2.69 | 0 |
| 2 | 1.0 | -1.358354 | -1.340163 | 1.773209 | 0.379780 | -0.503198 | 1.800499 | 0.791461 | 0.247676 | -1.514654 | … | 0.247998 | 0.771679 | 0.909412 | -0.689281 | -0.327642 | -0.139097 | -0.055353 | -0.059752 | 378.66 | 0 |
| 3 | 1.0 | -0.966272 | -0.185226 | 1.792993 | -0.863291 | -0.010309 | 1.247203 | 0.237609 | 0.377436 | -1.387024 | … | -0.108300 | 0.005274 | -0.190321 | -1.175575 | 0.647376 | -0.221929 | 0.062723 | 0.061458 | 123.50 | 0 |
| 4 | 2.0 | -1.158233 | 0.877737 | 1.548718 | 0.403034 | -0.407193 | 0.095921 | 0.592941 | -0.270533 | 0.817739 | … | -0.009431 | 0.798278 | -0.137458 | 0.141267 | -0.206010 | 0.502292 | 0.219422 | 0.215153 | 69.99 | 0 |
5 rows × 31 columns
查看各字段统计值
data.describe()| Time | V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | … | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Amount | Class | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| count | 284807.000000 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | … | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 2.848070e+05 | 284807.000000 | 284807.000000 |
| mean | 94813.859575 | 3.919560e-15 | 5.688174e-16 | -8.769071e-15 | 2.782312e-15 | -1.552563e-15 | 2.010663e-15 | -1.694249e-15 | -1.927028e-16 | -3.137024e-15 | … | 1.537294e-16 | 7.959909e-16 | 5.367590e-16 | 4.458112e-15 | 1.453003e-15 | 1.699104e-15 | -3.660161e-16 | -1.206049e-16 | 88.349619 | 0.001727 |
| std | 47488.145955 | 1.958696e+00 | 1.651309e+00 | 1.516255e+00 | 1.415869e+00 | 1.380247e+00 | 1.332271e+00 | 1.237094e+00 | 1.194353e+00 | 1.098632e+00 | … | 7.345240e-01 | 7.257016e-01 | 6.244603e-01 | 6.056471e-01 | 5.212781e-01 | 4.822270e-01 | 4.036325e-01 | 3.300833e-01 | 250.120109 | 0.041527 |
| min | 0.000000 | -5.640751e+01 | -7.271573e+01 | -4.832559e+01 | -5.683171e+00 | -1.137433e+02 | -2.616051e+01 | -4.355724e+01 | -7.321672e+01 | -1.343407e+01 | … | -3.483038e+01 | -1.093314e+01 | -4.480774e+01 | -2.836627e+00 | -1.029540e+01 | -2.604551e+00 | -2.256568e+01 | -1.543008e+01 | 0.000000 | 0.000000 |
| 25% | 54201.500000 | -9.203734e-01 | -5.985499e-01 | -8.903648e-01 | -8.486401e-01 | -6.915971e-01 | -7.682956e-01 | -5.540759e-01 | -2.086297e-01 | -6.430976e-01 | … | -2.283949e-01 | -5.423504e-01 | -1.618463e-01 | -3.545861e-01 | -3.171451e-01 | -3.269839e-01 | -7.083953e-02 | -5.295979e-02 | 5.600000 | 0.000000 |
| 50% | 84692.000000 | 1.810880e-02 | 6.548556e-02 | 1.798463e-01 | -1.984653e-02 | -5.433583e-02 | -2.741871e-01 | 4.010308e-02 | 2.235804e-02 | -5.142873e-02 | … | -2.945017e-02 | 6.781943e-03 | -1.119293e-02 | 4.097606e-02 | 1.659350e-02 | -5.213911e-02 | 1.342146e-03 | 1.124383e-02 | 22.000000 | 0.000000 |
| 75% | 139320.500000 | 1.315642e+00 | 8.037239e-01 | 1.027196e+00 | 7.433413e-01 | 6.119264e-01 | 3.985649e-01 | 5.704361e-01 | 3.273459e-01 | 5.971390e-01 | … | 1.863772e-01 | 5.285536e-01 | 1.476421e-01 | 4.395266e-01 | 3.507156e-01 | 2.409522e-01 | 9.104512e-02 | 7.827995e-02 | 77.165000 | 0.000000 |
| max | 172792.000000 | 2.454930e+00 | 2.205773e+01 | 9.382558e+00 | 1.687534e+01 | 3.480167e+01 | 7.330163e+01 | 1.205895e+02 | 2.000721e+01 | 1.559499e+01 | … | 2.720284e+01 | 1.050309e+01 | 2.252841e+01 | 4.584549e+00 | 7.519589e+00 | 3.517346e+00 | 3.161220e+01 | 3.384781e+01 | 25691.160000 | 1.000000 |
8 rows × 31 columns
查看欺诈类别的具体分布
plt.figure(figsize=(7,5))
sns.countplot(x='Class', data=data)
plt.title('Fraud Class Histogram')
plt.xlabel('Class')
plt.ylabel('Frequency')
print('正常用户数 :', data.Class.value_counts()[0])
print('欺诈用户数 :', data.Class.value_counts()[1]) 正常用户数 : 284315
欺诈用户数 : 492
可以看到样本数据存在很大的不均衡性,欺诈用户数明显少于正常用户。样本的不均衡对后续的模型评估效果存在较大影响,因此将会采用下采样及上采样两种方式调整样本的均衡
样本特征归一化
data1 = data.copy()from sklearn.preprocessing import StandardScaler
data1['NormAmount'] = StandardScaler().fit_transform(data1['Amount'].reshape(-1,1))
data1.drop(['Time', 'Amount'], axis=1, inplace=True)
data1.head()| V1 | V2 | V3 | V4 | V5 | V6 | V7 | V8 | V9 | V10 | … | V21 | V22 | V23 | V24 | V25 | V26 | V27 | V28 | Class | NormAmount | |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 0 | -1.359807 | -0.072781 | 2.536347 | 1.378155 | -0.338321 | 0.462388 | 0.239599 | 0.098698 | 0.363787 | 0.090794 | … | -0.018307 | 0.277838 | -0.110474 | 0.066928 | 0.128539 | -0.189115 | 0.133558 | -0.021053 | 0 | 0.244964 |
| 1 | 1.191857 | 0.266151 | 0.166480 | 0.448154 | 0.060018 | -0.082361 | -0.078803 | 0.085102 | -0.255425 | -0.166974 | … | -0.225775 | -0.638672 | 0.101288 | -0.339846 | 0.167170 | 0.125895 | -0.008983 | 0.014724 | 0 | -0.342475 |
| 2 | -1.358354 | -1.340163 | 1.773209 | 0.379780 | -0.503198 | 1.800499 | 0.791461 | 0.247676 | -1.514654 | 0.207643 | … | 0.247998 | 0.771679 | 0.909412 | -0.689281 | -0.327642 | -0.139097 | -0.055353 | -0.059752 | 0 | 1.160686 |
| 3 | -0.966272 | -0.185226 | 1.792993 | -0.863291 | -0.010309 | 1.247203 | 0.237609 | 0.377436 | -1.387024 | -0.054952 | … | -0.108300 | 0.005274 | -0.190321 | -1.175575 | 0.647376 | -0.221929 | 0.062723 | 0.061458 | 0 | 0.140534 |
| 4 | -1.158233 | 0.877737 | 1.548718 | 0.403034 | -0.407193 | 0.095921 | 0.592941 | -0.270533 | 0.817739 | 0.753074 | … | -0.009431 | 0.798278 | -0.137458 | 0.141267 | -0.206010 | 0.502292 | 0.219422 | 0.215153 | 0 | -0.073403 |
5 rows × 30 columns
3. 下采样
获取未经采样的特征与类别标签
X = data1.loc[:, data1.columns!='Class']
y = data1.loc[:, data1.columns=='Class']获取下采样后的特征与类别标签
num_fraud_class = data1[data1.Class == 1].shape[0] # 欺诈用户数
fraud_indices = np.array(data1[data1.Class == 1].index) # 欺诈用户的index
normal_indices = np.array(data1[data1.Class == 0].index) # 正常用户的index
# 从正常用户中随机抽取与欺诈用户数相等的正常用户
random_normal_indices = np.random.choice(normal_indices, num_fraud_class, replace=False)
random_normal_indices = np.array(random_normal_indices)
# 将随机抽取的正常用户与欺诈用户结合,形成均衡的下采样数据集
undersampled_indices = np.concatenate([random_normal_indices, fraud_indices])
X_undersampled = X.loc[undersampled_indices, :]
y_undersampled = y.loc[undersampled_indices, :]
# 显示下采样后用户类别占比
print('Percentage of normal transaction : ', len(random_normal_indices) / X_undersampled.shape[0])
print('Percentage of fraud transaction : ', len(fraud_indices) / X_undersampled.shape[0])
print('Total number of transactions in undersampled dataset : ',X_undersampled.shape[0])Percentage of normal transaction : 0.5
Percentage of fraud transaction : 0.5
Total number of transactions in undersampled dataset : 984
划分训练集和测试集
from sklearn.model_selection import train_test_split
# 原始数据集
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.3, random_state=1)
print('Number of transactions in training dataset : ', X_train.shape[0])
print('Number of transactions in test dataset : ', X_test.shape[0])
print('Percentage of fraud transactions in the whole dataset : ', y[y.Class == 1].shape[0] / y.shape[0])
print('Percentage of fraud transactions in the training dataset : ', y_train[y_train.Class == 1].shape[0] / y_train.shape[0])Number of transactions in training dataset : 199364
Number of transactions in test dataset : 85443
Percentage of fraud transactions in the whole dataset : 0.001727485630620034
Percentage of fraud transactions in the training dataset : 0.0017906944082181336
# 原始数据集
X_train_undersampled, X_test_undersampled, y_train_undersampled, y_test_undersampled = train_test_split(X_undersampled, y_undersampled, test_size=0.3, random_state=1)
print('Number of transactions in training dataset : ', X_train_undersampled.shape[0])
print('Number of transactions in test dataset : ', X_test_undersampled.shape[0])
print('Percentage of fraud transactions in the undersampled dataset : ', y_undersampled[y_undersampled.Class == 1].shape[0] / y_undersampled.shape[0])
print('Percentage of fraud transactions in the undersampled training dataset : ', y_train_undersampled[y_train_undersampled.Class == 1].shape[0] / y_train_undersampled.shape[0])Number of transactions in training dataset : 688
Number of transactions in test dataset : 296
Percentage of fraud transactions in the undersampled dataset : 0.5
Percentage of fraud transactions in the undersampled training dataset : 0.49127906976744184
交叉验证与参数调优
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import KFold, cross_val_score
from sklearn.metrics import recall_score, confusion_matrix, classification_reportdef print_KFold_scores(X_train, y_train):
fold = KFold(y_train.shape[0], n_folds=5, random_state=1, shuffle=False)
# 尝试不同的c parameter
c_params = [0.01, 0.1, 1, 10, 100]
df_results = pd.DataFrame(columns=['C_parameters','Mean_Recall_Score'])
# KFold会返回两个list,train_indices = indices[0], test_indices = indices[1]
j = 0
for c_param in c_params:
print('----------------------------------------')
print('C parameter : ', c_param)
print('----------------------------------------')
print('')
recallScores = []
for i, indices in enumerate(fold, start=1):
lr = LogisticRegression(C=c_param, penalty='l1')
lr.fit(X_train.iloc[indices[0],:].values, y_train.iloc[indices[0],:].values.reshape(-1,1))
y_pred = lr.predict(X_train.iloc[indices[1],:].values)
recallScore = recall_score(y_train.iloc[indices[1],:].values, y_pred)
recallScores.append(recallScore)
print("Iteration ", i, ": recall score = ", recallScore)
df_results.loc[j, 'C_parameters'] = c_param
df_results.loc[j, 'Mean_Recall_Score'] = np.mean(recallScores)
j += 1
print("Mean Recall Score = ", np.mean(recallScores))
best_c_param = df_results[df_results.Mean_Recall_Score == np.max(df_results.Mean_Recall_Score)]['C_parameters'].values[0]
print('*****************************************************')
print('Best C parameter chosen by cross validation = ', best_c_param)
print('*****************************************************')
return best_c_parambest_c = print_KFold_scores(X_train_undersampled, y_train_undersampled)----------------------------------------
C parameter : 0.01
----------------------------------------
Iteration 1 : recall score = 0.9538461538461539
Iteration 2 : recall score = 0.9558823529411765
Iteration 3 : recall score = 0.9402985074626866
Iteration 4 : recall score = 0.9710144927536232
Iteration 5 : recall score = 0.927536231884058
Mean Recall Score = 0.9497155477775395
----------------------------------------
C parameter : 0.1
----------------------------------------
Iteration 1 : recall score = 0.8
Iteration 2 : recall score = 0.9411764705882353
Iteration 3 : recall score = 0.8955223880597015
Iteration 4 : recall score = 0.9565217391304348
Iteration 5 : recall score = 0.8115942028985508
Mean Recall Score = 0.8809629601353844
----------------------------------------
C parameter : 1
----------------------------------------
Iteration 1 : recall score = 0.8307692307692308
Iteration 2 : recall score = 0.9411764705882353
Iteration 3 : recall score = 0.9104477611940298
Iteration 4 : recall score = 0.9710144927536232
Iteration 5 : recall score = 0.7971014492753623
Mean Recall Score = 0.8901018809160963
----------------------------------------
C parameter : 10
----------------------------------------
Iteration 1 : recall score = 0.8461538461538461
Iteration 2 : recall score = 0.9411764705882353
Iteration 3 : recall score = 0.9104477611940298
Iteration 4 : recall score = 0.9855072463768116
Iteration 5 : recall score = 0.8115942028985508
Mean Recall Score = 0.8989759054422948
----------------------------------------
C parameter : 100
----------------------------------------
C:\Users\user\Anaconda3\lib\site-packages\sklearn\utils\validation.py:578: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
Iteration 1 : recall score = 0.8307692307692308
Iteration 2 : recall score = 0.9411764705882353
Iteration 3 : recall score = 0.9104477611940298
Iteration 4 : recall score = 0.9855072463768116
Iteration 5 : recall score = 0.8115942028985508
Mean Recall Score = 0.8958989823653717
*****************************************************
Best C parameter chosen by cross validation = 0.01
*****************************************************
定义混淆矩阵绘制函数
import itertools
def plot_confusion_matrix(conf_mat, classes, title='Confusion Matrix', cmap=plt.cm.Blues):
plt.imshow(conf_mat, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=0)
plt.yticks(tick_marks, classes)
thresh = conf_mat.max() / 2
for i, j in itertools.product(range(conf_mat.shape[0]), range(conf_mat.shape[1])):
plt.text(j, i, conf_mat[i,j], horizontalalignment='center', color='white' if conf_mat[i,j] > thresh else 'black')
plt.tight_layout()
plt.xlabel('Predicted Label')
plt.ylabel('True Label')
基于下采样数据创建LR,并对下采样测试集进行预测
lr = LogisticRegression(C=best_c, penalty='l1')
lr.fit(X_train_undersampled, y_train_undersampled)
y_pred_undesampled = lr.predict(X_test_undersampled)# 绘制混淆矩阵
cnf_matrix = confusion_matrix(y_test_undersampled, y_pred_undesampled)
np.set_printoptions(precision=2)
print('Recall score in the undersampled test dataset : ', cnf_matrix[1,1] / (cnf_matrix[1,0] + cnf_matrix[1,1]))
classes = [0,1]
plt.figure()
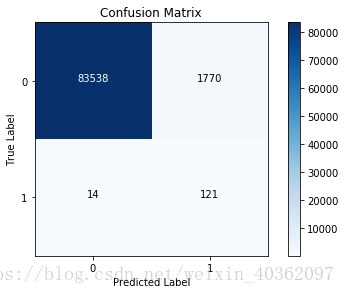
plot_confusion_matrix(cnf_matrix, classes)Recall score in the undersampled test dataset : 0.922077922077922

基于下采样数据创建LR,并对总测试集进行预测
lr = LogisticRegression(C=best_c, penalty='l1')
lr.fit(X_train_undersampled, y_train_undersampled)
y_pred = lr.predict(X_test)
cnf_matrix = confusion_matrix(y_test, y_pred)
np.set_printoptions(precision=2)
print('Recall score in the whole test dataset : ', cnf_matrix[1,1] / (cnf_matrix[1,0] + cnf_matrix[1,1]))
classes = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix, classes)C:\Users\user\Anaconda3\lib\site-packages\sklearn\utils\validation.py:578: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
Recall score in the whole test dataset : 0.9185185185185185
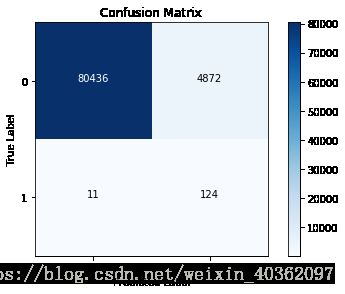
基于原始总数据集建立LR,并对总测试集进行预测
best_c = print_KFold_scores(X_train, y_train)----------------------------------------
C parameter : 0.01
----------------------------------------
C:\Users\user\Anaconda3\lib\site-packages\sklearn\utils\validation.py:578: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
Iteration 1 : recall score = 0.5342465753424658
Iteration 2 : recall score = 0.625
Iteration 3 : recall score = 0.5897435897435898
Iteration 4 : recall score = 0.5588235294117647
Iteration 5 : recall score = 0.5
Mean Recall Score = 0.5615627388995641
----------------------------------------
C parameter : 0.1
----------------------------------------
Iteration 1 : recall score = 0.589041095890411
Iteration 2 : recall score = 0.6805555555555556
Iteration 3 : recall score = 0.6153846153846154
Iteration 4 : recall score = 0.6323529411764706
Iteration 5 : recall score = 0.5454545454545454
Mean Recall Score = 0.6125577506923195
----------------------------------------
C parameter : 1
----------------------------------------
Iteration 1 : recall score = 0.6164383561643836
Iteration 2 : recall score = 0.6805555555555556
Iteration 3 : recall score = 0.6410256410256411
Iteration 4 : recall score = 0.6617647058823529
Iteration 5 : recall score = 0.5606060606060606
Mean Recall Score = 0.6320780638467987
----------------------------------------
C parameter : 10
----------------------------------------
Iteration 1 : recall score = 0.6301369863013698
Iteration 2 : recall score = 0.6666666666666666
Iteration 3 : recall score = 0.6538461538461539
Iteration 4 : recall score = 0.6617647058823529
Iteration 5 : recall score = 0.5606060606060606
Mean Recall Score = 0.6346041146605208
----------------------------------------
C parameter : 100
----------------------------------------
Iteration 1 : recall score = 0.6301369863013698
Iteration 2 : recall score = 0.6666666666666666
Iteration 3 : recall score = 0.6538461538461539
Iteration 4 : recall score = 0.6617647058823529
Iteration 5 : recall score = 0.5606060606060606
Mean Recall Score = 0.6346041146605208
*****************************************************
Best C parameter chosen by cross validation = 10
*****************************************************
lr = LogisticRegression(C=best_c, penalty='l1')
lr.fit(X_train, y_train)
y_pred = lr.predict(X_test)
cnf_matrix = confusion_matrix(y_test, y_pred)
np.set_printoptions(precision=2)
print('Recall score in the whole test dataset : ', cnf_matrix[1,1] / (cnf_matrix[1,0] + cnf_matrix[1,1]))
classes = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix, classes)Recall score in the whole test dataset : 0.5777777777777777
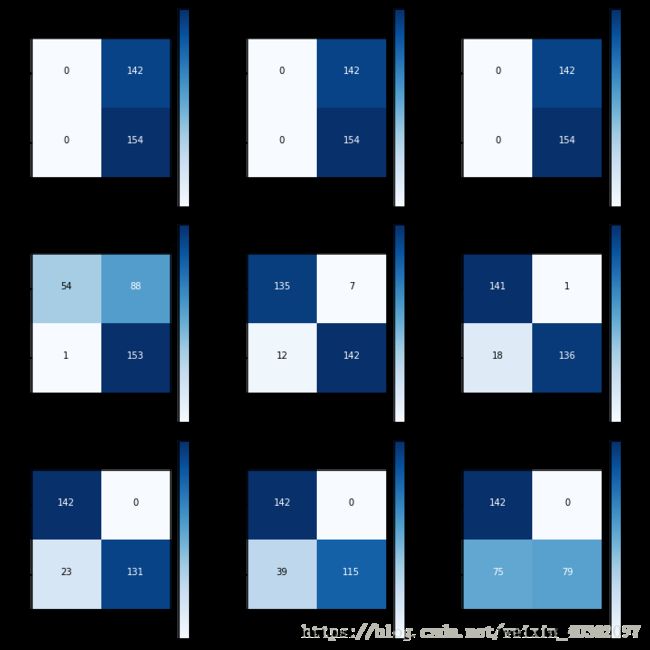
基于下采样数据集建立LR,并分析threshold对于recall_score的影响
lr = LogisticRegression(C=0.01, penalty='l1')
lr.fit(X_train_undersampled, y_train_undersampled)
y_pred_undersampled_proba = lr.predict_proba(X_test_undersampled)
thresholds = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9]
plt.figure(figsize=[10,10])
j = 1
for threshold in thresholds:
y_pred_undersampled_high_recall = y_pred_undersampled_proba[:,1] > threshold
plt.subplot(3,3,j)
j += 1
cnf_matrix = confusion_matrix(y_test_undersampled, y_pred_undersampled_high_recall)
np.set_printoptions(precision=2)
print('Recall score : %.3f, Precision score : %.3f' % (cnf_matrix[1,1] / (cnf_matrix[1,0] + cnf_matrix[1,1]),
cnf_matrix[1,1] / (cnf_matrix[0,1] + cnf_matrix[1,1])))
classes = [0,1]
plot_confusion_matrix(cnf_matrix, classes, title='Threshold >= %f' % threshold)Recall score : 1.000, Precision score : 0.520
Recall score : 1.000, Precision score : 0.520
Recall score : 1.000, Precision score : 0.520
Recall score : 0.994, Precision score : 0.635
Recall score : 0.922, Precision score : 0.953
Recall score : 0.883, Precision score : 0.993
Recall score : 0.851, Precision score : 1.000
Recall score : 0.747, Precision score : 1.000
Recall score : 0.513, Precision score : 1.000
4. 上采样
from imblearn.over_sampling import SMOTEoversampler = SMOTE(random_state=1)利用SOMTE对训练集数据进行上采样
X_train_oversampled, y_train_oversampled = oversampler.fit_sample(X_train, y_train)C:\Users\user\Anaconda3\lib\site-packages\sklearn\utils\validation.py:578: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
X_train_oversampled = pd.DataFrame(X_train_oversampled, columns=X_train.columns)
y_train_oversampled = pd.DataFrame(y_train_oversampled, columns=y_train.columns)print('No. of fraud transactions in oversampled training dataset : ', y_train_oversampled[y_train_oversampled.Class == 1].shape[0])
print('No. of normal transactions in oversampled training dataset : ', y_train_oversampled[y_train_oversampled.Class == 0].shape[0])No. of fraud transactions in oversampled training dataset : 199007
No. of normal transactions in oversampled training dataset : 199007
利用之前定义的print_KFold_scores函数得到最优C parameter值
best_c = print_KFold_scores(X_train_oversampled, y_train_oversampled)----------------------------------------
C parameter : 0.01
----------------------------------------
C:\Users\user\Anaconda3\lib\site-packages\sklearn\utils\validation.py:578: DataConversionWarning: A column-vector y was passed when a 1d array was expected. Please change the shape of y to (n_samples, ), for example using ravel().
y = column_or_1d(y, warn=True)
Iteration 1 : recall score = 0.9103448275862069
Iteration 2 : recall score = 0.9655172413793104
Iteration 3 : recall score = 0.9215934399676048
Iteration 4 : recall score = 0.9044633996206173
Iteration 5 : recall score = 0.9036707620411547
Mean Recall Score = 0.9211179341189789
----------------------------------------
C parameter : 0.1
----------------------------------------
Iteration 1 : recall score = 0.9172413793103448
Iteration 2 : recall score = 0.9655172413793104
Iteration 3 : recall score = 0.923744685158939
Iteration 4 : recall score = 0.9061341909224526
Iteration 5 : recall score = 0.9055048868118891
Mean Recall Score = 0.9236284767165872
----------------------------------------
C parameter : 1
----------------------------------------
Iteration 1 : recall score = 0.9172413793103448
Iteration 2 : recall score = 0.9655172413793104
Iteration 3 : recall score = 0.9236687588580684
Iteration 4 : recall score = 0.9061844402849139
Iteration 5 : recall score = 0.9055802618024673
Mean Recall Score = 0.9236384163270209
----------------------------------------
C parameter : 10
----------------------------------------
Iteration 1 : recall score = 0.9172413793103448
Iteration 2 : recall score = 0.9655172413793104
Iteration 3 : recall score = 0.9237193763919822
Iteration 4 : recall score = 0.9061718779442985
Iteration 5 : recall score = 0.9058063867742017
Mean Recall Score = 0.9236912523600275
----------------------------------------
C parameter : 100
----------------------------------------
Iteration 1 : recall score = 0.9172413793103448
Iteration 2 : recall score = 0.9655172413793104
Iteration 3 : recall score = 0.923744685158939
Iteration 4 : recall score = 0.9062346896473751
Iteration 5 : recall score = 0.905831511771061
Mean Recall Score = 0.923713901453406
*****************************************************
Best C parameter chosen by cross validation = 100
*****************************************************
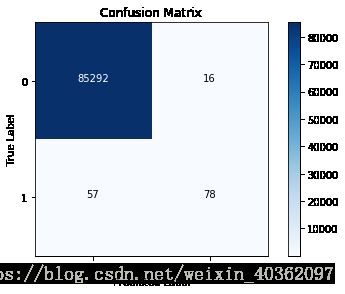
基于上采样训练集数据建立LR模型,并对原始测试集进行预测
lr = LogisticRegression(C=best_c, penalty='l1')
lr.fit(X_train_oversampled, y_train_oversampled)
y_pred = lr.predict(X_test)
cnf_matrix = confusion_matrix(y_test, y_pred)
np.set_printoptions(precision=2)
print('Recall score in the whole test dataset : ', cnf_matrix[1,1] / (cnf_matrix[1,0] + cnf_matrix[1,1]))
classes = [0,1]
plt.figure()
plot_confusion_matrix(cnf_matrix, classes)Recall score in the whole test dataset : 0.8962962962962963