【无标题】针对MNIST数据集,构造卷积神经网络实现手写数字识别。
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
针对MNIST数据集,构造卷积神经网络实现手写数字识别。
- 一、 实验目的和要求
- 二、python实验代码
-
- data_loader.py
- network3.py
- main.py
- 三、实验过程
- 四、实验中参数和结果的分析
-
-
- 在原始训练集上设置10轮训练结果
- 在旋转训练集上设置10轮训练结果:
-
- 总结
一、 实验目的和要求
- 针对MNIST数据集,构造卷积神经网络实现手写数字识别。
- 利用Pytorch搭建神经网络。
- 创建一个项目文件夹,文件夹里面有一个文件夹以及三个文件,文件夹名为data,存放MNIST数据集,三个文件为: main.py、network3.py、 data_loader.py。其中main为主文件,通过运行main启动手写数字识别程序;network3.py存放神经网络类定义及相关函数;data_loader.py存放负责读入数据的相关方法。
- 在network3.py的神经网络类定义中,增加一个方法用于记录每一个卷积层输出的特征图。然后,在main.py中实现所有卷积层的卷积核、特征图的可视化
- 基于课堂讲授的数据增强思想,对模型进行改进。以原始数据集为基础,构造旋转90°、180°后的手写数字样本并加入到训练/验证/测试集中,然后对模型进行必要的改进,使得它能够准确识别旋转后的样本。
二、python实验代码
data_loader.py
import torch
import torchvision.datasets
import torchvision.transforms as transforms
import os
import matplotlib.pyplot as plt
import numpy as np
os.environ["KMP_DUPLICATE_LIB_OK"] = "True"
batch_size = 64 # 一个批次的大小,64张图片
transform = transforms.Compose([transforms.ToTensor(),
transforms.Normalize([0.1307], [0.3081])])
transform_r90 = transforms.Compose([transforms.ToTensor(), transforms.RandomRotation((90, 90)),
transforms.Normalize([0.1307], [0.3081])])
transform_r180 = transforms.Compose([transforms.ToTensor(), transforms.RandomRotation((180, 180)),
transforms.Normalize([0.1307], [0.3081])])
train_dataset = torchvision.datasets.MNIST(root=r'./data', # 文件存放路径
train=True,
transform=transform,
download=True)
train_dataset_r90= torchvision.datasets.MNIST(root=r'./data', # 文件存放路径
train=True,
transform=transform_r90,
download=True)
train_dataset_r180= torchvision.datasets.MNIST(root=r'./data', # 文件存放路径
train=True,
transform=transform_r180,
download=True)
all_train_dataset=train_dataset+train_dataset_r90+train_dataset_r180
all_train_data_loader = torch.utils.data.DataLoader(dataset=all_train_dataset,
batch_size=batch_size,
shuffle=True)
train_data_loader = torch.utils.data.DataLoader(dataset=train_dataset,
batch_size=batch_size,
shuffle=True)
# 加载测试数据集
test_dataset = torchvision.datasets.MNIST(root=r'./data',
train=False,
transform=transform,download=True)
test_dataset_r90 = torchvision.datasets.MNIST(root=r'./data',
train=False,
transform=transform_r90,download=True)
test_dataset_r180 = torchvision.datasets.MNIST(root=r'./data',
train=False,
transform=transform_r180,download=True)
all_test_dataset=test_dataset+test_dataset_r90+test_dataset_r180
# 训练数据集的加载器,自动将数据切分成批,顺序随机打乱
'''
将测试数据分成两部分,一部分作为校验数据,一部分作为测试数据。
校验数据用于检测模型是否过拟合并调整参数,测试数据检验整个模型的工作
'''
indices = range(len(test_dataset))
middle=len(test_dataset)//2
indices_val = indices[: middle]
indices_test = indices[middle:]
# 根据下标构造两个数据集的SubsetRandomSampler 采样器,它会对下标进行采样
sampler_val = torch.utils.data.sampler.SubsetRandomSampler(indices_val)
sampler_test = torch.utils.data.sampler.SubsetRandomSampler(indices_test)
# 根据两个采样器定义加载器
# 注意将sampler_val 和sampler_test 分别賦值给了 validation_loader 和 test_loader
all_validation_loader = torch.utils.data.DataLoader(dataset=all_test_dataset,
batch_size=batch_size,
shuffle=False,
sampler=sampler_val)
all_test_loader = torch.utils.data.DataLoader(dataset=all_test_dataset,
batch_size=batch_size,
shuffle=False,
sampler=sampler_test)
validation_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False,
sampler=sampler_val)
test_loader = torch.utils.data.DataLoader(dataset=test_dataset,
batch_size=batch_size,
shuffle=False,
sampler=sampler_test)
def imshow(img,data_name):
img = img / 2 + 0.5
npimg = img.numpy()
plt.title(data_name)
plt.imshow(np.transpose(npimg, (1, 2, 0)))
plt.show()
def show_simple(data_to_loader,data_name="train_data"):
dataiter = iter(data_to_loader)
images, labels = dataiter.next()
imshow(torchvision.utils.make_grid(images),data_name=data_name)
print(' '.join('%2s' % labels[j].numpy() for j in range(len(labels))))
if __name__=="__main__":
show_simple(all_train_data_loader,"rotate_train_data")
network3.py
import torch.nn as nn
import torch.nn.functional as F
import torch.optim as optim
from torch.autograd import Variable
import data_loader3
import matplotlib.pyplot as plt
import pylab
image_size = 28 # 图像的总尺寸为 28x28
num_classes = 10 # 标签的种类数
# 定义卷积神经网络:6和16为人为指定的两个卷积层的厚度
depth = [6, 16]
class ConvNet(nn.Module):
def __init__(self):
super(ConvNet, self).__init__()
self.conv1 = nn.Conv2d(1, 6, 5, padding=2)
self.pool = nn.MaxPool2d(2, 2)
self.conv2 = nn.Conv2d(depth[0], depth[1], 5, padding=2)
self.fc1 = nn.Linear(image_size // 4 * image_size // 4 * depth[1], 512)
self.fc2 = nn.Linear(512, num_classes)
def forward(self, x):
x = self.conv1(x)
x = F.relu(x)
x = self.pool(x)
x = self.conv2(x)
x = F.relu(x)
x = self.pool(x)
x = x.view(-1, image_size // 4 * image_size // 4 * depth[1])
x = F.relu(self.fc1(x))
x = F.dropout(x, training=self.training)
x = self.fc2(x)
x = F.log_softmax(x, dim=1)
return x
def retrieve_features(self, x):
# 该函数用于提取卷积神经网络的特征图,返回feature_map1,feature_map2为前两层卷积层的特征图
feature_map1 = F.relu(self.conv1(x)) # 完成第一层卷积
x = self.pool(feature_map1) # 完成第一层池化
# 第二层卷积,两层特征图都存储到了 feature_map1,feature map2 中
feature_map2 = F.relu(self.conv2(x))
return (feature_map1, feature_map2)
# 开始训练循环
def rightness(output, target):
preds = output.data.max(dim=1, keepdim=True)[1]
return preds.eq(target.data.view_as(preds)).cpu().sum(), len(target)
def cycle_training(net,num_epochs,rotate=False):
if not rotate:
train_data_loader=data_loader3.train_data_loader
validation_loader=data_loader3.validation_loader
train_data_loader_dataset=data_loader3.train_data_loader.dataset
else:
train_data_loader = data_loader3.all_train_data_loader
validation_loader = data_loader3.all_validation_loader
train_data_loader_dataset = data_loader3.all_train_data_loader.dataset
batch_size = 64 # 一个批次的大小,64张图片
criterion = nn.CrossEntropyLoss() # Loss 函数的定义,交叉熵
optimizer = optim.SGD(net.parameters(), lr=0.001, momentum=0.9) # 定义优化器,普通的随机梯度下降算法
record = [] # 记录准确率等数值的容器
weights = [] # 每若干步就记录一次卷积核
for epoch in range(num_epochs):
train_rights = [] # 记录训练数据集准确率的容器
'''
下面的enumerate起到构道一个枚举器的作用。在对train_loader做循环选代时,enumerate会自动输出一个数宇指示循环了几次,
并记录在batch_idx中,它就等于0,1,2,...
train_loader 每选代一次,就会输出一对数据data和target,分别对应一个批中的手写数宇图及对应的标签。
'''
for batch_idx, (data, target) in enumerate(train_data_loader): # 针对容器中的每一个批进行循环
# 将 Tensor 转化为 Variable, data 为一批图像,target 为一批标签
data, target = Variable(data), Variable(target)
# 给网络模型做标记,标志着模型在训练集上训练
# 这种区分主要是为了打开关闭net的training标志,从而决定是否运行dropout
net.train()
output = net(data) # 神经网络完成一次前馈的计算过程,得到预测输出output
loss = criterion(output, target) # 将output与标签target比较,计算误差
optimizer.zero_grad() # 清空梯度
loss.backward() # 反向传播
optimizer.step() # 一步随机梯度下降算法
right = rightness(output, target) # 计算准确率所需数值,返回数值为(正确样例数,总样本数)
train_rights.append(right) # 将计算结果装到列表容器train_rights中
if batch_idx % 100 == 0: # 每间隔100个batch 执行一次打印操作
net.eval() # 给网络楧型做标记,标志着模型在训练集上训练
val_rights = [] # 记录校验数据集准确率的容器
# 开始在校验集上做循环,计算校验集上的准确度
for (data, target) in validation_loader:
data, target = Variable(data), Variable(target)
# 完成一次前馈计算过程,得到目前训练得到的模型net在校验集上的表现
output = net(data)
# 计算准确率所需数值,返回正确的数值为(正确样例数,总样本数)
right = rightness(output, target)
val_rights.append(right)
# 分别计算目前已经计算过的测试集以及全部校验集上模型的表现:分类准确率
# train_r为一个二元组,分别记录经历过的所有训练集中分类正确的数量和该集合中总的样本数
# train_r[0]/train_r[1]是训练集的分类准殖度,val_[0]/val_r[1]是校验集的分类准确度
train_r = (sum([tup[0] for tup in train_rights]), sum([tup[1] for tup in train_rights]))
# val_r为一个二元组,分别记录校验集中分类正确的数量和该集合中总的样本数
val_r = (sum([tup[0] for tup in val_rights]), sum([tup[1] for tup in val_rights]))
# 打印准确率等数值,其中正确率为本训练周期epoch 开始后到目前批的正确率的平均值
print(val_r,train_r)
print('训练周期: {} [{}/{} ({:.0f}%)]\tLoss: {:.6f}\t训练正确率: {:.2f}%\t校验正确率: {:.2f}%'.format(
epoch, batch_idx * batch_size, len(train_data_loader_dataset),
100. * batch_idx / len(train_data_loader),
loss.data,
100. * train_r[0].numpy() / train_r[1],
100. * val_r[0].numpy() / val_r[1]))
# 将准确率和权重等数值加载到容器中,方便后续处理
record.append((100 - 100. * train_r[0] / train_r[1], 100 - 100. * val_r[0] / val_r[1]))
weights.append([net.conv1.weight.data.clone(), net.conv1.bias.data.clone(),
net.conv2.weight.data.clone(), net.conv2.bias.data.clone()])
return record, weights
def show_error_rate(record):
# 绘制训练过程的误差曲线,校验集和测试集上的错误率。
plt.figure(figsize=(10, 7))
plt.title('Training loss curve')
plt.plot(record) # record记载了每一个打印周期记录的训练和校验数据集上的准确度
plt.xlabel('Steps')
plt.ylabel('Error rate')
pylab.show()
def show_convolution_kernel(net):
''' 可视化第一层卷积核与特征图 '''
# 提取第一层卷积层的卷积核
plt.figure(figsize=(10, 7))
for i in range(4):
plt.subplot(1, 4, i + 1)
# 提取第一层卷积核中的权重值,注意conv1是net的属性
plt.imshow(net.conv1.weight.data.numpy()[i, 0, ...])
plt.title('Convolution kernel of the first convolution layer')
pylab.show()
idx = 56
input_x = data_loader3.test_dataset[idx][0].unsqueeze(0)
feature_maps = net.retrieve_features(Variable(input_x))
plt.figure(figsize=(10, 7))
# 打印出6个特征图
for i in range(6):
plt.subplot(1, 6, i + 1)
plt.imshow(feature_maps[0][0, i, ...].data.numpy())
plt.title('Characteristic diagram of the first layer of convolution')
pylab.show()
''' 可视化第二层卷积核与特征图 '''
# 绘制第二层的卷积核,每一列对应一个卷积核,一共有16个卷积核
plt.figure(figsize=(15, 10))
plt.title('Characteristic diagram of the second layer of convolution')
for i in range(6):
for j in range(16):
plt.subplot(6, 16, i * 16 + j + 1)
plt.imshow(net.conv2.weight.data.numpy()[j, i, ...])
pylab.show()
# 绘制第二层的特征图,一共有16个
plt.figure(figsize=(10, 7))
plt.title('Characteristic diagram of the second layer of convolution')
for i in range(16):
plt.subplot(2, 4, i + 1)
plt.imshow(feature_maps[1][0, i, ...].data.numpy())
pylab.show()
if __name__=="__main__":
net=ConvNet()
print(net)
main.py
import network3
import torch
if __name__=="__main__":
net = network3.ConvNet()
record, weights = network3.cycle_training(net,num_epochs=10,rotate=False)
network3.show_error_rate(record)
network3.show_convolution_kernel(net)
torch.save(net.state_dict(), 'model_new902')
三、实验过程
- 在pycharm上面编写data_loader.py的代码,如项目文件里的data_loader.py所示。
该代码主要是先从MNIST数据集加载数据,train_dataset 表示加载的训练集数据有6万份,而test_dataset表示加载的测试集数据有1万份.把train_dataset放到train_data_loader上,将又将train_dataset测试数据分成两部分,一部分作为校验数据,一部分作为测试数据。校验数据用于检测模型是否过拟合并调整参数,测试数据检验整个模型的工作。之后再编写函数imshow()和show_simple()来查看数据集的一部分数据。查看数据如下图

数据标签:
1 6 0 7 1 0 4 3
3 0 2 8 2 2 8 5
4 3 1 5 4 6 0 8
7 3 3 2 9 7 3 0
9 4 1 9 6 9 1 7
9 3 4 0 7 8 9 6
0 1 0 3 9 8 0 7
2 0 0 5 1 6 7 7
- 利用Pytorch在network3.py里面编写神经网络类ConvNet(nn.Module)该类在forward函数里面完成神经网络的前向传播的过程。神经网络的结构如下:
ConvNet(
(conv1): Conv2d(1, 6, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(pool): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(conv2): Conv2d(6, 16, kernel_size=(5, 5), stride=(1, 1), padding=(2, 2))
(fc1): Linear(in_features=784, out_features=512, bias=True)
(fc2): Linear(in_features=512, out_features=10, bias=True)
)
我们编写函数cycle_training(num_epochs,rotate=False)来循环批量训练数据,为此,定义一个损失函数和优化器 ,我们使用分类交叉熵Cross-Entropy 作损失函数,动量SGD做优化器。接下来便是不断训练,在训练时,将计算分类结果顺便装到列表容器train_rights中。每间隔100个batch 执行一次打印操作,方便知悉训练的进度和情况,并且在校验集上做循环,计算校验集上的准确度,记录到val_rights上。这样子就分别得到目前已经计算过的测试集以及全部校验集上模型的表现:分类准确率。编写show_error_rate(record)函数,让其绘制训练过程的误差曲线,校验集和测试集上的错误率。 - 编写main.py,新建一个卷积神经网络的实例,即调用network3中的ConvNet()类。然后network3.cycle_training(num_epochs=10,rotate=False)开始训练过程。
为了展示卷积层的卷积核、特征图的情况,在network3.py的神经网络类定义中,增加一个方法show_convolution_kernel(net)用于记录每一个卷积层输出的特征图。然后,在main.py中实现所有卷积层的卷积核、特征图的可视化。 - 以原始数据集为基础,在data_loader.py里面,构造旋转90°、180°后的手写数字样本并加入到训练/验证/测试集中,创建包含旋转90°、180°和原始数据集的all_train_dataset训练数据集(180000份)和all_test_dataset测试数据集(30000份),然后在main.py中network3.cycle_training(num_epochs=1,rotate=True),让,rotate=True使得它能使用上新的训练集。
我们可以改变network3.py中show_simple()的参数,来展示旋转90°、180°后的手写数字样本。如图:

数据标签:
6 2 6 1 4 5 2 3
9 8 2 2 9 6 1 8
6 8 1 8 6 0 5 4
9 7 5 7 4 7 3 0
4 6 5 0 1 6 2 3
1 8 3 6 7 9 0 4
9 2 2 1 0 6 4 9
6 3 2 3 9 6 2 3
四、实验中参数和结果的分析
在原始训练集上设置10轮训练结果
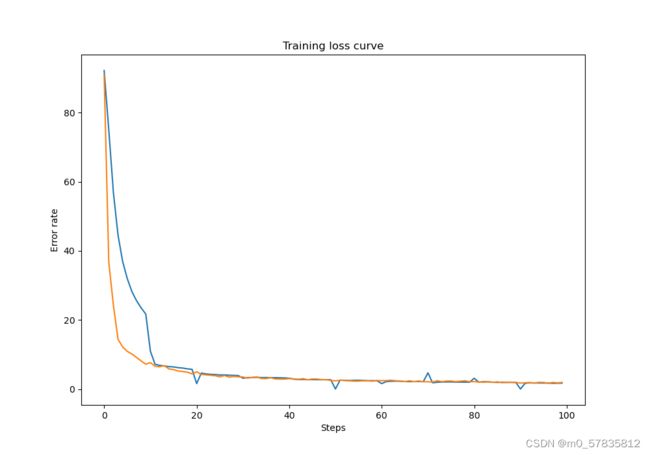
其中橙色为训练集的损失率,蓝色的为测试集的损失率;
训练集的损失率和测试集的损失率在前两轮快速下降,之后再小范围的逐步减小到0.006左右。
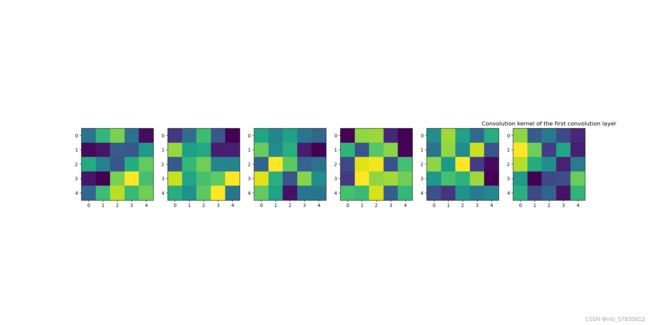
第一层的卷积核

第一层卷积核结果
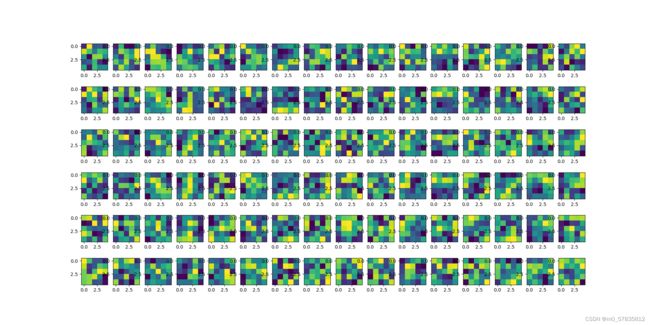
第二层的卷积核
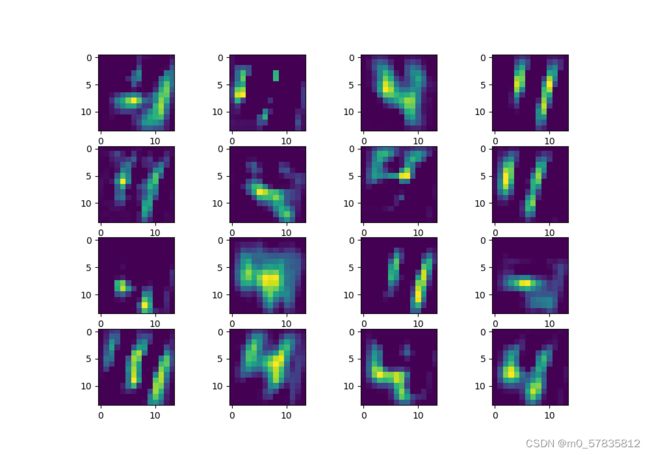
第二层卷积核作用结果
第一层卷积提取的特征是从原图像提取,而第二层的卷积核是再第一层的卷积核的基础上再提取,可见第一层的卷积结果还能看到数字的样子,而第二层卷积结果则是提取更加多的特征,包括主体轮廓,边缘轮廓,背景,背景轮廓,等等。
在旋转训练集上设置10轮训练结果:
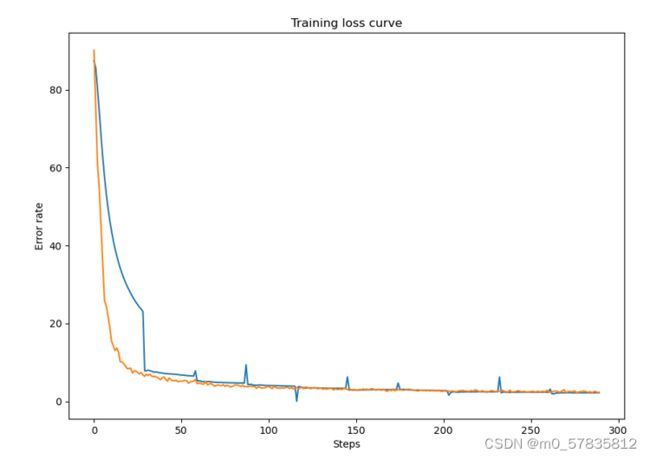
其中橙色为训练集的损失率,蓝色的为测试集的损失率;
训练集的损失率和测试集的损失率在前3轮快速下降,之后再小范围的逐步减小到0.01左右。
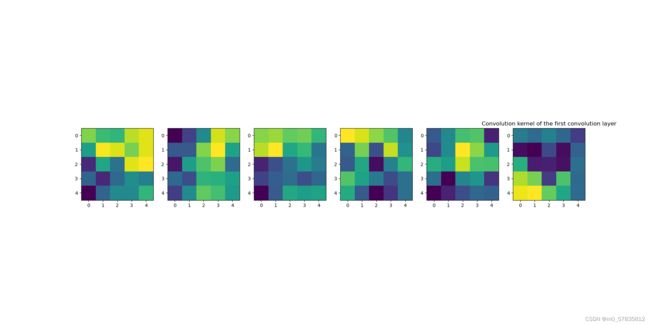
第一层的卷积核
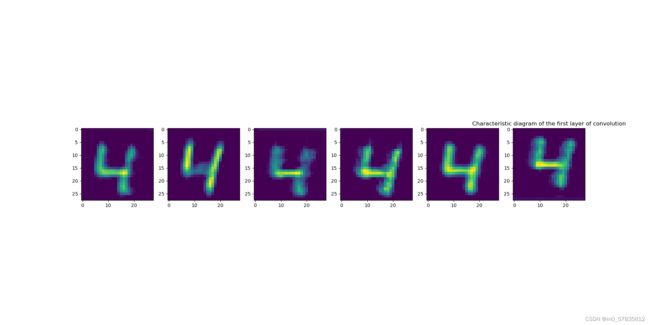
第一层卷积核结果
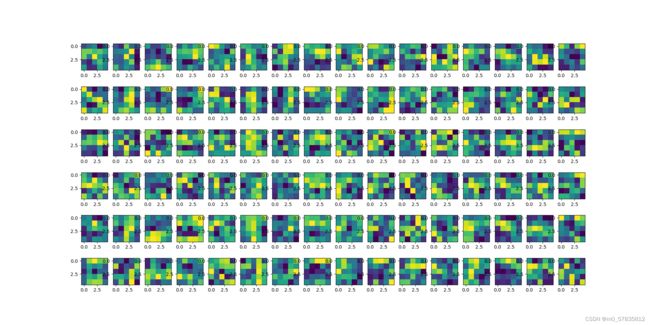
第二层卷积核
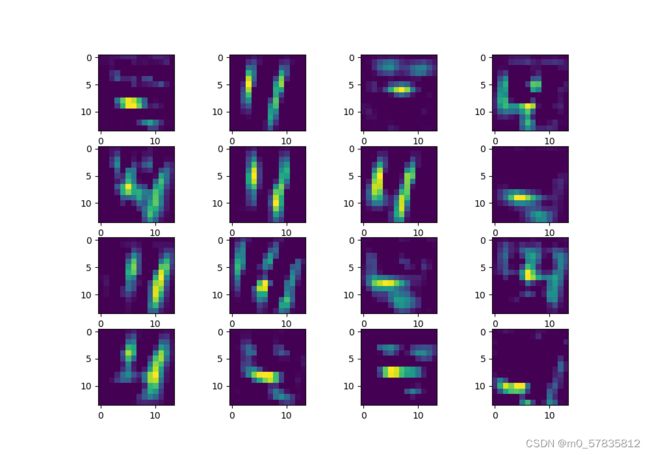
第二层卷积核结果
第一层卷积核好像在提取数字的特征点,而第二层则好像在把握住数字的形态。
总结
以pytorch构建的两层卷积核,一层池化层,两层全连接层的神经网络,在Mninst数据 集上训练,准确率达到98%,而且在增加旋转的Mninst数据集上达到97%的准确率。