知识图谱系统课程笔记(二)——知识抽取与挖掘
知识图谱系统课程笔记(二)——知识抽取与挖掘
文章目录
-
- 知识图谱系统课程笔记(二)——知识抽取与挖掘
-
- OWL、RDF与RDFS关系
- 知识抽取任务定义和相关比赛
- 知识抽取技术
-
- 知识获取关键技术与难点
- 知识抽取的子任务
- 实体抽取
-
- 命名实体识别
- 非结构化数据的实体抽取
-
- 序列标注方法
-
- HMM(隐马尔可夫模型)
- 面向结构化数据的知识抽取
- 面向半结构化数据的知识抽取
- 实践展示:基于百科数据的知识抽取


OWL、RDF与RDFS关系
RDF是数据模型,定义了知识图谱的图结构,以主谓宾来表示的三元组,对应很多序列化格式。
RDFS也可以用RDF来表示,只是这里的调语和宾语是一些预定 义的词汇,如谓语是rdf:type, rdfs:subClass或rdfs subProperty , domain, range,宾语rdfs:Class和rdfs:Property等.在此基础上, OWL也可以用RDF来表示为三元组,他会增加更多的预定义的词汇.这些词汇使得我们有了更严格并支持本体推理的schema层或称为概念层。
对于了解一些常用的缩写是有价值的,这种多看几个我们说的知识库,并用- -下他们的SPARQL查询接口或浏览界面就会慢慢熟悉了,不要强行去背。
知识抽取任务定义和相关比赛
知识抽取技术
定义:知识抽取是自动地从文本中发现和抽取相关信息。
● 实体抽取
● 关系抽取
● 事件抽取.
(行业)知识图谱数据来源
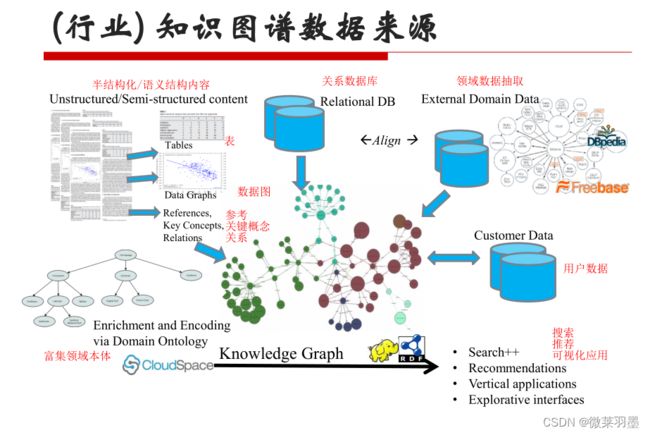
知识抽取的数据类型
从不同来源、不同结构的数据中进行知识提取,形成知识存入到知识图谱。

示例:
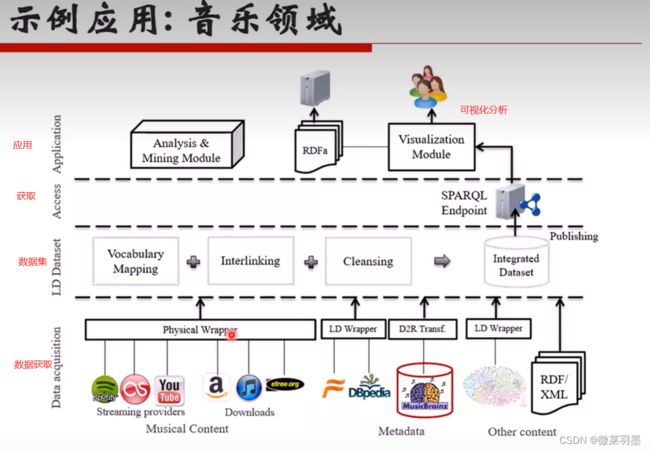
知识获取关键技术与难点
●) 从结构化数据库中获取知识: D2R
●难点:复杂表数据的处理
●从链接数据 中获取知识:图映射
●难点:数据对齐
●从半结构化 (网站)数据中获取知识:使用包装器
●难点:方便的包装器定义方法,包装器自动生成、更新与维护
●从文本中获取知识:信息抽取
● 难点:结果的准确率与覆盖率
知识抽取的子任务
1.命名实体识别
检测:西瓜书的作者是周志华。→[西瓜书]:实体
分类:西瓜书的作者是周志华。→[西瓜书]:书籍

2.术语抽取
从语料中发现多个单词组成的相关术语。
3.关系抽取
抽取出实体、属性等之间的关系。
例子:王思聪是万达集团董事长王健林的独子。→[王健林] <父子关系> [王思聪]
4.事件抽取
相当于多元关系抽取
例子:

5.共指消解


其他
- 实体检测与识别
例如:人、组织、地点、工具等。

- 数值检测与识别

- 实体发现与链接
人 person(PER)

- 槽填充
发现并填充 实体的属性。

其他

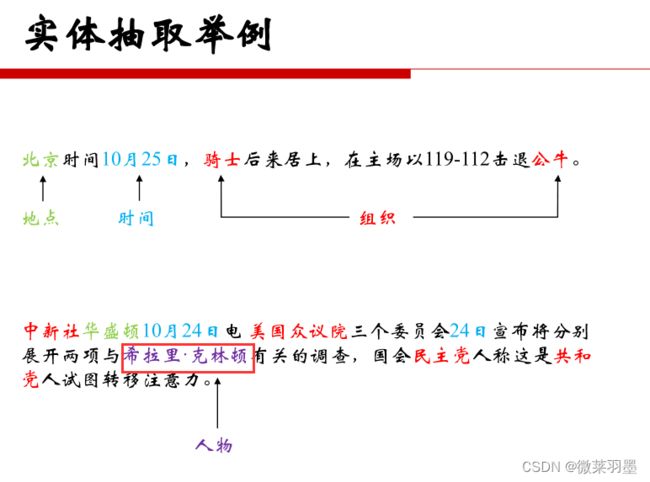
实体抽取
定义:抽取文本中的原子信息元素。
实体:包括人名、组织/机构名、地理位置、时间/日期、字符值、金额值等(原子根据场景来定义)。
例子:
命名实体识别
**定义:**识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
**功能:**命名实体识别是信息提取、问答系统、句法分析、机器翻译、面向Semantic Web的元数据标注等应用领域的重要基础工具,在自然语言处理技术走向实用化的过程中占有重要地位。一般来说,命名实体识别的任务就是识别出待处理文本中三大类(实体类、时间类和数字类)、七小类(人名、机构名、地名、时间、日期、货币和百分比)命名实体。
标签类型:进行命名实体识别时,通常需要对每个字进行标注,中文为单个字,英文为单词,空格分割。标注的标签类型如下表所示
————————————————
原文链接:https://blog.csdn.net/scgaliguodong123_/article/details/121303421
非结构化数据的实体抽取
非结构化数据的实体抽取可以认为是一个序列标注问题,于是我们可以使用序列标注的方法,例如使用HMM、CRF等方法,也可以使用LSTM+CRF的方法,
序列标注方法
序列标注定义:序列标注(Sequence Tagging)是NLP中最基础的任务,应用十分广泛,如分词、词性标注(POS tagging)、命名实体识别(Named Entity Recognition,NER)、关键词抽取、语义角色标注(Semantic Role Labeling)、槽位抽取(Slot Filling)等实质上都属于序列标注的范畴。
原文链接:https://blog.csdn.net/scgaliguodong123_/article/details/121303421
- 简述序列标注的三种方法
实体识别三种常见的序列标注方法如下:
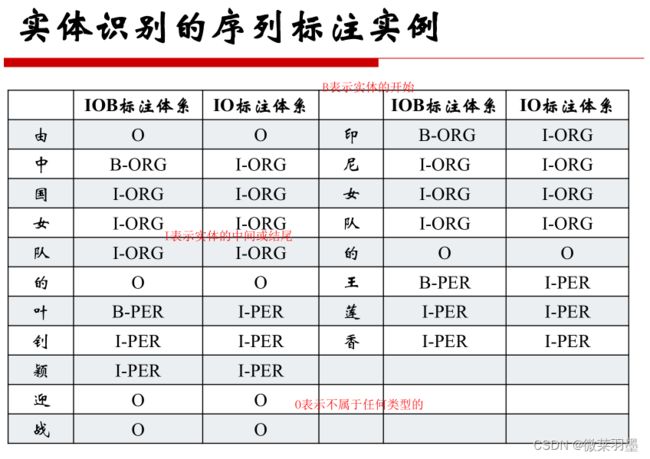
**BIO:**标识实体的开始,中间部分和非实体部分
**BMES:**增加S单个实体情况的标注
**BIOSE:**增加E实体的结束标识
1.BIO-三位序列标注法(B-begin,I-inside,O-outside)
B-X代表实体X的开头
I-X代表实体X的中间或结尾
O代表不属于任何类型的
样例:
我是李果冻,我爱中国,我来自四川。
我 O
是 O
李 B-PER
果 I-PER
冻 I-PER
, O
我 O
爱 O
中 B-ORG
国 I-ORG
, O
我 O
来 O
自 O
四 B-LOC
川 I-LOC
。 O
2.BMES-四位序列标注法(B-begin,M-middle,E-end,S-single)
B 表示一个词的词首位值
M 表示一个词的中间位置
E 表示一个词的末尾位置
S 表示一个单独的字词
样例:
我是四川人
我 S
是 S
四 B
川 M
人 E
3.BIOES-四位序列标注法(B-begin,I-inside,O-outside,E-end,S-single)
B表示开始
I表示内部
O表示非实体
E表示实体尾部
S表示改词本身就是一个实体
样例:
我是李果冻,我爱中国,我来自四川。
我 O
是 O
李 B-PER
果 I-PER
冻 E-PER
, O
我 O
爱 O
中 B-LOC
国 E-LOC
, O
我 O
来 O
自 O
四 B-LOC
川 E-LOC
。 O
————————————————
原文链接:https://blog.csdn.net/scgaliguodong123_/article/details/121303421

序列标注的实例:
序列标注的经典方法:HMM,MEMM,CRF
参考序列标注的经典方法:HMM,MEMM,CRF
HMM(隐马尔可夫模型)
HMM(Hidden Markov Model,隐马尔可夫模型)是一个生成模型,它假设每一个时间点系统会由一个状态随机转移到另一个状态,并且随机发射出一个观测值。我们不能观测到系统的状态,只能看到发射出的一连串的观测值。用HMM来解决序列问题,观测序列为x ,而状态序列即为 y 。为了方便,下文就沿用来指代观测序列和状态序列。HMM的状态序列就是一个Markov Chain(马尔可夫链),遵循如下两个假设:
几种方法通过F1值的比较如下:

HMM模型
https://zhuanlan.zhihu.com/p/533866352