MyDLNote-Transformer(for Low-Level): Uformer: U 型 Transformer 图像修复
论文阅读之 - 用 Transformer 做图像修复
Uformer: A General U-Shaped Transformer for Image Restoration

https://arxiv.org/pdf/2106.03106v1.pdf
https://github.com/ZhendongWang6/Uformer
目录
Abstract
Introduction
Method
Overall Pipeline
LeWin Transformer Block
Variants of Skip-Connection
Abstract
In this paper, we present Uformer, an effective and efficient Transformer-based architecture, in which we build a hierarchical encoder-decoder network using the Transformer block for image restoration.
Uformer has two core designs to make it suitable for this task. The first key element is a local-enhanced window Transformer block, where we use non-overlapping window-based self-attention to reduce the computational requirement and employ the depth-wise convolution in the feedforward network to further improve its potential for capturing local context. The second key element is that we explore three skip-connection schemes to effectively deliver information from the encoder to the decoder. Powered by these two designs, Uformer enjoys a high capability for capturing useful dependencies for image restoration.
Extensive experiments on several image restoration tasks demonstrate the superiority of Uformer, including image denoising, deraining, deblurring and demoireing. We expect that our work will encourage further research to explore Transformer-based architectures for low-level vision tasks.
Introduction
Since the rapid development of consumer and industry cameras and smartphones, the requirements of removing undesired degradation (e.g., noise, blur, rain, and moire pattern) in images are constantly growing. Recovering clear images from their degraded versions, i.e., image restoration, is a classic problem in computer vision. Recent state-of-the-art methods [1, 2, 3, 4] are mostly CNN-based, which achieve impressive results but show a limitation in capturing long-range dependencies. To address this problem, several recent works [5, 6, 7] start to employ single or few self-attention layers in low resolution feature maps due to the self-attention computational complexity being quadratic to the feature map size.
开门见山,直接表明里本文的动机:传统 CNN 方法在捕获长距离依赖关系时能力有限。而现有的改进方法采用的模型,由于图像上的 self-attention 计算量非常大,因此其通常使用中低分辨率的特征图上。
In this paper, we aim to leverage the capability of self-attention in feature maps at multi-scale resolutions to recover more image details. To achieve this, we present Uformer, an effective and efficient Transformer-based structure for image restoration. Uformer is built upon an elegant architecture, the so-called "UNet" [8]. We modify the convolution layers to Transformer blocks while keeping the same overall hierarchical encoder-decoder structure and the skip-connections.
本文的目标是利用自注意能力的特征图在多尺度分辨率恢复更多的图像细节。为了实现这一目标,提出了Uformer,采用 U-Net 结构。将卷积层修改为 Transformer 块,同时保持相同的分层编码器-解码器结构和跳过连接。
Uformer has two core designs to make it suitable for image restoration. The first key element is a local-enhanced window Transformer block. To reduce the large computational complexity of self-attention on high resolution feature maps, we use non-overlapping window-based self-attention instead of global self-attention for capturing long-range dependencies. Since we build hierarchical feature maps and keep the window size unchanged, the window-based self-attention at low resolution is able to capture more global dependencies. On the other hand, previous works [9, 10] suggest that self-attention has limitation to obtain local dependencies. To overcome this problem, inspired by the recent vision Transformers [10, 11], we leverage a depth-wise convolutional layer between two fully-connected layers of the feed-forward network in the Transformer block for better capturing local context.
Uformer 用于图像修复,设计了两个关键方法:
1. local-enhanced window (LeWin) Transformer block:非重叠的 window-based 自注意力,可以降低计算复杂度;由于在 U-Net 的不同层中,窗口的尺度不变,因此,在低分辨率特征图上可以捕获更多的全局相关性。
另外,为了捕获局部上下文信息,在两个全连接层增加了一个 depth-wise 卷积层。
The second key element is that we explore how to achieve better information delivering in the Transformer-based encoder-decoder structure. First, similar to U-Net, we concatenate the features from the l-th stage of the encoder and the (l-1)-th stage of the decoder firstly, and use the concatenated features as the input to the Transformer block in the decoder. Besides, we formulate the problem of delivering information from the encoder to the decoder as a process of self-attention computing: the features in the decoder play the role of queries and seek to estimate their relationship to the features in the encoder which play the role of keys and values. To achieve this, we design another two schemes. In the first one, we add a self-attention module into the Transformer block in the decoder, and use the features from the encoder as the keys and values, and the features in the decoder as the queries. In the second scheme, we combine the keys and values in the encoder and decoder together, and only use the queries from the decoder to find related keys. These three connection schemes can achieve competitive results under constrained computational complexity.
2. Three connection schemes:编码器输出特征到解码器的过程看作是自注意力的方式,即 1)当前层的编码器输出特征作为 key 和 value,上一层的解码器输出特征为 query。2)将编码器中的 key 和 value 和解码器组合在一起,只使用解码器中的 query 来查找相关的 key。(这一句理解可能有困难,读到最后 ConcatCross-Skip 的方法,就明白了。)
Method
In this section, we first describe the overall pipeline and the hierarchical structure of Uformer for image restoration. Then, we provide the details of the LeWin Transformer block which is the basic component of Uformer. After that, we introduce three variants of skip-connection for bridging the information flow between the encoder and the decoder.
第一小节 Uformer: U-Net 和 Transformer 结合的整体形式;
第二小节 LeWin Transformer block: 关键设计 1;
第三小节 Three variants of skip-connection:关键设计 2。
Overall Pipeline
- Encoder:
To be specific, given a degraded image I∈R^{3×H×W}, Uformer firstly applies a 3 × 3 convolutional layer with LeakyReLU to extract low-level features X0∈R^{C×H×W}.
Next, following the design of the U-shaped structures [8, 45], the feature maps X0 are passed through K encoder stages. Each stage contains a stack of the proposed LeWin Transformer blocks and one down-sampling layer.
The LeWin Transformer block takes advantage of the self-attention mechanism for capturing long-range dependencies, and also cuts the computational cost due to the usage of self-attention through non-overlapping windows on the feature maps.
In the down-sampling layer, we first reshape the flattened features into 2D spatial feature maps, and then down-sample the maps and double the channels using 4 × 4 convolution with stride 2.
- bottleneck stage
Then, a bottleneck stage with a stack of LeWin Transformer blocks is added at the end of the encoder. In this stage, thanks to the hierarchical structure, the Transformer blocks capture longer (even global when the window size equals the feature map size) dependencies.
- Decoder
For feature reconstruction, the proposed decoder also contains K stages. Each consists of an upsampling layer and a stack of LeWin Transformer blocks similar to the encoder.
We use 2 × 2 transposed convolution with stride 2 for the up-sampling . This layer reduces half of the feature channels and doubles the size of the feature maps.
After that, the features inputted to the LeWin Transformer blocks are the up-sampled features and the corresponding features from the encoder through skip-connection.
Next, the LeWin Transformer blocks are utilized to learn to restore the image. After the K decoder stages, we reshape the flattened features to 2D feature maps and apply a 3 × 3 convolution layer to obtain a residual image R∈R^{3×H×W}.
Finally, the restored image is obtained by I 0 = I + R.
In our experiments, we empirically set K = 4 and each stage contains two LeWin Transformer blocks.
We train Uformer using the Charbonnier loss.
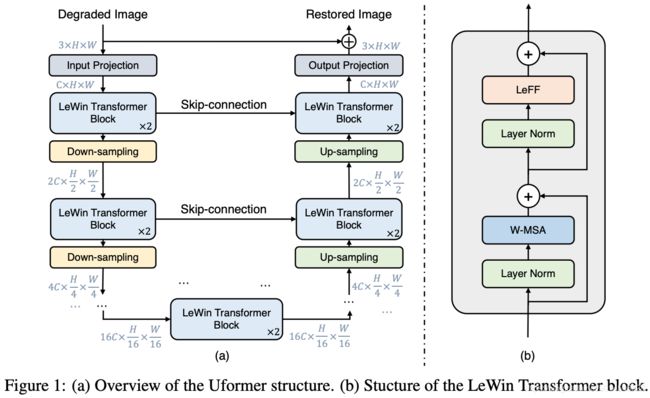
关于网络结构的描述,就像小学课本里面介绍某个建筑的课文一样,按照空间顺序逐个介绍,必要时介绍一下这个结构的作用是什么。注意几点:
1. 第一层 3x3 卷积 + LeakyReLU;
2. 编码器一共 K 层,每层编码器包括 1 个 LeWin Transformer block 层和 1 个下采样层;
3. LeWin Transformer block 捕获长距离相关性信息;
4. 下采样层采用 4x4 卷积,步进为 2;
5. bottleneck 层是由几个 LeWin Transformer block 堆叠组成;
6. 编码器一共 K 层,每层编码器包括 1 个上采样层 和 1 个 LeWin Transformer block 层;
7. 上采样层采用 2x2 去卷积层,步进为 2;
8. 网络的末端是一个图像修复层,即一个 3x3 的卷积层;
9. 网络采用残差修复形式,即网络本体学习的是图像修复过程中残差的部分;
10. K = 4;每个 LeWin Transformer block 层包括 2 个 LeWin Transformer block。
11. 训练采用 Charbonnier loss:
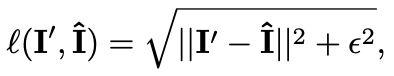
LeWin Transformer Block
传统 Transformer 不足:应用 Transformer 进行图像恢复主要有两个问题。首先,标准的 Transformer 体系结构在所有 tokens 之间计算全局自注意,这导致了与 tokens 数量二次的计算代价。在高分辨率特征图上应用全局自注意是不合适的。其次,局部上下文信息对于图像恢复任务至关重要,因为可以利用退化像素的邻域来恢复其版本,但以前的工作表明 Transformer 在捕获局部依赖方面存在局限性。
为了解决上面提到的两个问题,提出了一个 LeWin Transformer 块,如图 1(b) 所示,其得益于Transformer 中的自注意力来捕获长期依赖关系,还涉及到 Transformer 中的卷积算子来捕获有用的局部上下文。具体来说,考虑到第 (l-1) 个块 X_{l−1} 的特征,构建了具有两个核心设计的块:(1) 基于非重叠 Window-based Multi-head Self-Attention (W-MSA) 和 (2) Locally-enhanced Feed-Forward Network (LeFF)。LeWin Transformer 块的计算表示为:

LN 表示 layer normalization。
- Window-based Multi-head Self-Attention (W-MSA).
Given the 2D feature maps X∈ R^{C×H×W} with H and W being the height and width of the maps, we split X into non-overlapping windows with the window size of M × M, and then get the flattened and transposed features X_i ∈ R^{M2×C} from each window i.
Next, we perform self-attention on the flattened features in each window. Suppose the head number is k and the head dimension is d_k = C/k.
Then computing the k-th head self-attention in the non-overlapping windows can be defined as:
where W^Q_k , W^K_k , W^V_k ∈ R^{C×d_k} represent the projection matrices of the queries, keys, and values for the k-th head, respectively. Xˆ_k is the output of the k-th head. Then the outputs for all heads {1, 2, . . . , k} are concatenated and then linearly projected to get the final result. Inspired by previous works [48, 41], we also apply the relative position encoding into the attention module, so the attention calculation can be formulated as:
where B is the relative position bias, whose values are taken from Bˆ∈ R (2M−1)×(2M−1) with learnable parameters [48, 41].
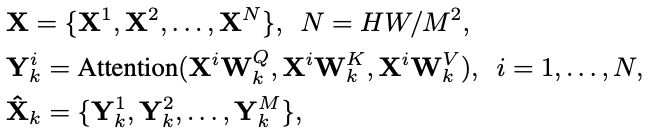

1. 将输入特征图分割成窗口大小为 MxM 的不重叠块,然后排列成 M2×C 的维度;
2. 多头自注意力,k 个 head,则每个 head 包含 d_k=C/k 个通道;
3. 自注意力模型中,包括了 位置偏差 参数的学习。
Window-based self-attention can significantly reduce the computational cost compared with global self-attention. Given the feature maps X ∈ R C×H×W , the computational complexity drops from O(H^2 W^2 C) to O( (HW/M^2) M^4 C) = O(M^2 HWC). As shown in Figure 2(a), since we design Uformer as a hierarchical architecture, our window-based self-attention at low resolution feature maps works on larger receptive fields and is sufficient to learn long-range dependencies. We also try the shifted window strategy [41] in the even LeWin Transformer block of each stage in our framework, which gives only slightly better results.
本文采用的 Window-based self-attention 有效地降低了计算复杂度。
本文也尝试采用不同的窗口大小,但带来了较小的增益。
- Locally-enhanced Feed-Forward Network (LeFF).
As pointed out by previous works [9, 10], the Feed-Forward Network (FFN) in the standard Transformer presents limited capability to leverage local context. However, neighboring pixels are crucial references for image restoration [49, 50]. To overcome this issue, we add a depth-wise convolutional block to the FFN in our Transformer-based structure following the recent works [51, 10, 11].
As shown in Figure 2(b), we first apply a linear projection layer to each token to increase its feature dimension.
Next, we reshape the tokens to 2D feature maps, and use a 3 × 3 depth-wise convolution to capture local information.
Then we flatten the features to tokens and shrink the channels via another linear layer to match the dimension of the input channels.
We use GELU [52] as the activation function after each linear/convolution layer.
1. 目的:增加局部学习能力;
2. 方法:1)linear projection layer,增加每个 token 的维度;2)reshape token 到 2D 特征图;3)然后 3x3 的 depth-wise 卷积;4)再 reshape 到 token;5)linear projection layer,缩减每个 token 的维度;6)每个 linear 和 卷积层后面,采用 GELU 激活函数。
Variants of Skip-Connection

- Concatenation-based Skip-connection (Concat-Skip).
Concatenation-based skip-connection is based on the widely-used skip-connection in U-Net [8, 4, 3]. To build our network, firstly, we concatenate the l-th stage flattened features E_l and each encoder stage with the features D_{l−1} from the (l-1)-th decoder stage channel-wisely. Then, we feed the concatenated features to the W-MSA component of the first LeWin Transformer block in the decoder stage, as shown in Figure 2(c.1).
传统的 U-Net方法,即将编 / 解码器的特征 concatenated,然后对其直接做自注意力。
- Cross-attention as Skip-connection (Cross-Skip).
Instead of directly concatenating features from the encoder and the decoder, we design Cross-Skip inspired by the decoder structure in the language Transformer [36]. As shown in Figure 2(c.2), we first add an additional attention module into the first LeWin Transformer block in each decoder stage. The first self-attention module in this block (the shaded one) is used to seek the self-similarity pixel-wisely from the decoder features D_{l−1}, and the second attention module in this block takes the features E_l from the encoder as the keys and values, and uses the features from the first module as the queries.
在该方法中,有两个自注意力模型。第一个直接对解码器对输出做自注意力,用来学习像素级的自相似性;第二个是将编码器的输出作为 keys and values,编码器的输出作为 queries。
- Concatenation-based Cross-attention as Skip-connection (ConcatCross-Skip).
Combining above two variants, we also design another skip-connection. As illustrated in Figure 2(c.3), we concatenate the features E_l from the encoder and D_{l−1} from the decoder as the keys and values, while the queries are only from the decoder.
该方法是上面两种方法的结合,即首先将编 / 解码器的特征 concatenated,作为 keys and values,然后原来的解码器输出特征作为 queries。