【推荐系统】DIN源码分析(1)
数据样本构造
关于训练集和测试集合的划分(更为详细的介绍可以看这里:DIN论文官方实现解析)
Amazon Dataset2. Amazon Dataset contains product reviews and metadata from Amazon, which is used as benchmark dataset[13,18, 23]. We conduct experiments on a subset named Electronics, which contains 192,403 users, 63,001 goods, 801 categories and 1,689,188 samples. User behaviors in this dataset are rich, with more than 5 reviews for each users and goods. Features include
goods_id, cate_id, user reviewed goods_id_list and cate_id_list. Let all behaviors of a user be (b1,b2, . . . ,bk , . . . ,bn), the task is to predict the (k+1)-th reviewed goods by making use of the first k reviewed goods. Training dataset is generated with k = 1, 2, . . . ,n-2 for each user. In the test set, we predict the last one given the first n - 1 reviewed goods. For all models, we use SGD as the optimizer with exponential decay, in which learning rate starts at 1 and decay rate is set to 0.1. The mini-batch size is set to be 32.
样本分析
userid = 4
设 用户的历史行为:[1,2,4,5]
随机初始的itemid为 0.
train_set_pos 1 17 [(0, [1], 2, 1), (0, [1], 0, 0), (0, [1, 2], 4, 1), (0, [1, 2], 0, 0), (1, [1], 2, 1), (1, [1], 0, 0), (1, [1, 2], 4, 1), (1, [1, 2], 0, 0), (2, [1], 2, 1), (2, [1], 0, 0), (2, [1, 2], 4, 1), (2, [1, 2], 0, 0), (3, [1], 2, 1), (3, [1], 0, 0), (3, [1, 2], 4, 1), (3, [1, 2], 0, 0),
(4, [1], 2, 1)] # 生产一条正样本,假设用户在已点击1的情况下,如果预测点击为2,则是正样本
train_set_neg 1 18 [(0, [1], 2, 1), (0, [1], 0, 0), (0, [1, 2], 4, 1), (0, [1, 2], 0, 0), (1, [1], 2, 1), (1, [1], 0, 0), (1, [1, 2], 4, 1), (1, [1, 2], 0, 0), (2, [1], 2, 1), (2, [1], 0, 0), (2, [1, 2], 4, 1), (2, [1, 2], 0, 0), (3, [1], 2, 1), (3, [1], 0, 0), (3, [1, 2], 4, 1), (3, [1, 2], 0, 0),
(4, [1], 2, 1), (4, [1], 0, 0)] # 生产一条负样本,假设用户在已点击1的情况下,如果预测点击为0,则是负样本
train_set_pos 2 19 [(0, [1], 2, 1), (0, [1], 0, 0), (0, [1, 2], 4, 1), (0, [1, 2], 0, 0), (1, [1], 2, 1), (1, [1], 0, 0), (1, [1, 2], 4, 1), (1, [1, 2], 0, 0), (2, [1], 2, 1), (2, [1], 0, 0), (2, [1, 2], 4, 1), (2, [1, 2], 0, 0), (3, [1], 2, 1), (3, [1], 0, 0), (3, [1, 2], 4, 1), (3, [1, 2], 0, 0),
(4, [1], 2, 1), (4, [1], 0, 0), (4, [1, 2], 4, 1)] # 生产一条正样本,假设用户在已点击[1,2]的情况下,如果预测点击为4,则是正样本
train_set_neg 2 20 [(0, [1], 2, 1), (0, [1], 0, 0), (0, [1, 2], 4, 1), (0, [1, 2], 0, 0), (1, [1], 2, 1), (1, [1], 0, 0), (1, [1, 2], 4, 1), (1, [1, 2], 0, 0), (2, [1], 2, 1), (2, [1], 0, 0), (2, [1, 2], 4, 1), (2, [1, 2], 0, 0), (3, [1], 2, 1), (3, [1], 0, 0), (3, [1, 2], 4, 1), (3, [1, 2], 0, 0),
(4, [1], 2, 1), (4, [1], 0, 0), (4, [1, 2], 4, 1), (4, [1, 2], 0, 0)] # 生产一条负样本,假设用户在已点击[1,2]的情况下,如果预测点击为0,则是负样本
# 每一个user,用前n-1个item,去预测第n个item.
# 这里每一个用户的历史行为都是[1,2,4,5], 都用前3次行为,去预测第4次行为,这里第4次真实的行为是点击了5, 0是没有点击的
test_set 3 5 [(0, [1, 2, 4], (5, 0)), (1, [1, 2, 4], (5, 0)), (2, [1, 2, 4], (5, 0)), (3, [1, 2, 4], (5, 0)),
(4, [1, 2, 4], (5, 0))] # 测试集,(5, 0) # (pos_id, neg_id)
推荐模型之用户行为序列处理 - billlee的文章 - 知乎(很实用的一些方法)
DIN网络结构
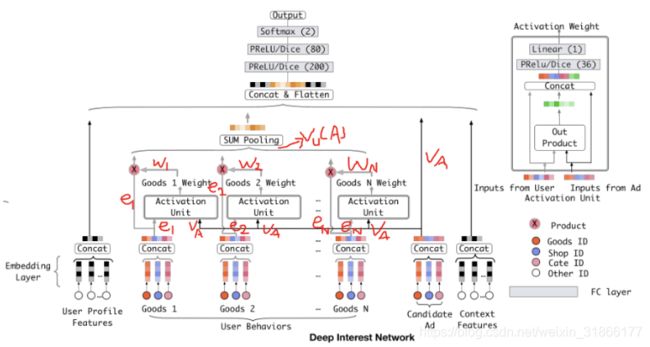
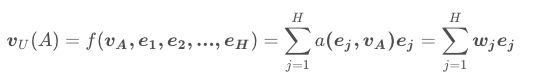
class Model(object):
def __init__(self, user_count, item_count, cate_count, cate_list, predict_batch_size, predict_ads_num):
# shape: [B], user id (B: batch size)
self.u = tf.placeholder(tf.int32, [None,])
# shape: [B] i: 正样本的item
self.i = tf.placeholder(tf.int32, [None,])
# shape: [B] j: 负样本的item
self.j = tf.placeholder(tf.int32, [None,])
# shape: [B], y: label
self.y = tf.placeholder(tf.float32, [None,])
# shape: [B, T] # 用户行为特征(User Behavior)中的item序列, T为序列长度
self.hist_i = tf.placeholder(tf.int32, [None, None])
# shape: [B]; sl: sequence length, User Behavior中序列的真实序列长度
self.sl = tf.placeholder(tf.int32, [None,])
# learning rate
self.lr = tf.placeholder(tf.float64, [])
hidden_units = 128
# shape: [U, H], user_id的embedding weight. U是user_id的hash bucket size
user_emb_w = tf.get_variable("user_emb_w", [user_count, hidden_units])
# shape: [I, H//2], item_id的embedding weight. I是item_id的hash bucket size
# [I, H//2]
item_emb_w = tf.get_variable("item_emb_w", [item_count, hidden_units // 2])
# shape: [I], bias
item_b = tf.get_variable("item_b", [item_count],
initializer=tf.constant_initializer(0.0))
# shape: [C, H//2], cate_id的embedding weight.
cate_emb_w = tf.get_variable("cate_emb_w", [cate_count, hidden_units // 2])
# shape: [C, H//2]
cate_list = tf.convert_to_tensor(cate_list, dtype=tf.int64)
# 从cate_list中取出正样本的cate
ic = tf.gather(cate_list, self.i)
# 正样本的embedding,正样本包括item和cate
i_emb = tf.concat(values = [
tf.nn.embedding_lookup(item_emb_w, self.i),
tf.nn.embedding_lookup(cate_emb_w, ic),
], axis=1)
i_b = tf.gather(item_b, self.i)
# 从cate_list中取出负样本的cate
jc = tf.gather(cate_list, self.j)
# 负样本的embedding,负样本包括item和cate
j_emb = tf.concat([
tf.nn.embedding_lookup(item_emb_w, self.j),
tf.nn.embedding_lookup(cate_emb_w, jc),
], axis=1)
# 偏置b
j_b = tf.gather(item_b, self.j)
# 用户行为序列(User Behavior)中的cate序列
hc = tf.gather(cate_list, self.hist_i)
# 用户行为序列(User Behavior)的embedding,包括item序列和cate序列
h_emb = tf.concat([
tf.nn.embedding_lookup(item_emb_w, self.hist_i),
tf.nn.embedding_lookup(cate_emb_w, hc),
], axis=2)
# attention操作
# 返回用户行为的每个商品的兴趣分布
hist_i = attention(i_emb, h_emb, self.sl)
#-- attention end ---
hist_i = tf.layers.batch_normalization(inputs = hist_i)
hist_i = tf.reshape(hist_i, [-1, hidden_units], name='hist_bn')
hist_i = tf.layers.dense(hist_i, hidden_units, name='hist_fcn')
u_emb_i = hist_i
hist_j = attention(j_emb, h_emb, self.sl)
#-- attention end ---
参考:
DIN(Deep Interest Network):核心思想+源码阅读注释
https://blog.csdn.net/weixin_47364682/article/details/109210534?utm_medium=distribute.pc_relevant.none-task-blog-baidujs_baidulandingword-7&spm=1001.2101.3001.4242
DIN算法代码详细解读 - 小2小M的文章 - 知乎
关于构造正负样本的trick:都说数据是上限,推荐系统ctr模型中,构造正负样本有哪些实用的trick? - 知乎