canoco5主成分分析步骤_SPSS数据分析1——主成分分析
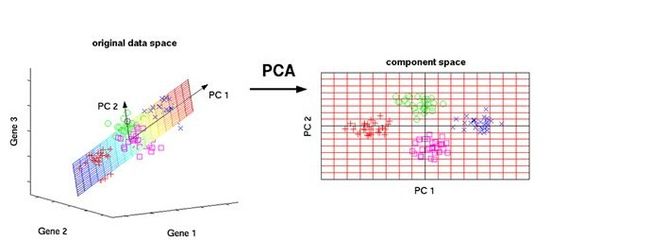
多变量分析中的最大问题莫过于多元线性问题,SPSS降维分析中的主成分分析可以很好地解决这个问题。所谓主成分分析(PCA)也称主分量分析,是有Karl Pearson在1901年提出的,它旨在利用把多个变量指标转化为为少数几个综合指标,是问题的分析变得更加容易。
未经许可请勿转载
更多数据分析内容参看这里
一. 相关理论
- 基本原理
将多个变量指标通过线性变换浓缩为少数几个主成分指标的多元统计方法。基本思想是把原来多个相关性较强的变量,重新整合为一组互不相关的新的综合指标来代替原来的变量。借助于一个正交变换,将其分量相关的原始随机向量转换成分量不相关的新随机向量。在代数上表现为将原随机向量的协方差阵变换成对角型阵,在几何上表现为将原坐标系变成新的正交坐标系,使之指向样本点散步最开的P个正交方向,然后对多维变量系统进行降维处理,使之能以一个较高的精度转换成低维变量系统,再通过构造适当的价值函数,进一步把低维系统转化为一维系统。方差较大的几个新变量能综合反映原来多个变量包含的主要信息。这几个新变量就是主成分。
2. 主成分数量筛选依据
(1)累积方差贡献率:当前m个主成分的累积方差贡献率达到某一特定值(一般80%以上),就可以保留前m个主成分
(2)特征值:一般选取特征值大于等于1的主成分
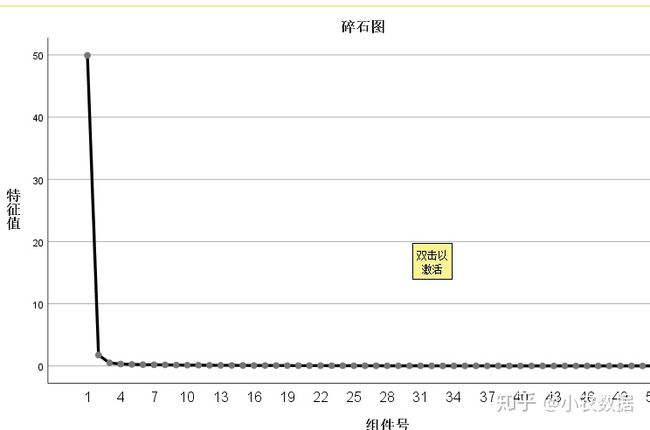
(3)碎石图:一般选取碎石图的曲线上由陡峭变为舒缓的结点前的碎石为主成分
3. 主成分分析中的主要统计量
(1)方差贡献率:指的是一个主成分所能够解释的方差占全部方差的比例,这个值越大,说明主成分综合原始变量的信息的能力越强。
方差贡献率的计算公式为:
相应的,主成分筛选中所确定的前m个主成分所能解释的全部方差占总方差的比例称为累计方差贡献率。其公式为:
第一主成分的方差贡献率最大,他能解释原始变量X1,X2....,Xp的能力最强,第2,第3,...第p个主成分的解释能力一次递减。
(2)特征值:衡量主成分影响力的重要指标,它代表引入该主成分可以解释平均多少原始标量的信息。求出特征值后要按大小予以排列:
4. 主成分分析中的适合度检验
(1)Bartlett球形检验
原始变量间存在相关性是进行主成分分析的首要条件,否则原始变量无法进行降维处理。为了检验变量之间是否存在相关性,Bartlett在1950年提出了著名的Bartlett球形检验方法,用于检验变量相关系数矩阵是否为单位矩阵。
设变量相关系数矩阵为R,Bartlett球形检验的统计量为:
如果原始变量之间相互独立,那么他们的相关系数矩阵R接近一个单位矩阵。此时|R|接近1,ln|R|约等于0;如果原始变量之间有相关关系,|R|接近于0,ln|R|趋向于负无穷。此时SPSS输出相关系数矩阵的行列式的值,即|R|值。
Bartlett球形检验的假设是:
H0:相关系数矩阵是单位矩阵(变量不相关)
H1:相关系数矩阵不是单位矩阵(变量相关)
SPSS将输出Bartlett球形检验的卡方统计量,自由度和显著性值。如果显著性值P≤0.05,则认为相关系数矩阵不是单位矩阵,可以进行主成分分析。同时卡方值越大,说明变量之间的相关性越强。
(2)KMO取样适合度检验统计量
KMO通过比较样本间的相关系数平方和和偏相关系数平方和的大小以检验赝本是否适合进行主成分分析。如果变量之间的相关系数绝对值较大,而偏相关系数绝对值较小,则表明变量之间高度相关可能与第三变量有关,存在多元线性相关的可能性较大,适合进行主成分分析或因子分析。KMO统计量的定义如下
KMO统计量MSA的取值为0-1,越接近1说明变量间的相关性越强而偏相关性度越低,样本数据越适合做主成分分析和因子分析。根据Kaiser的研究经验,MSA>0.9表示非常合适,0.8-0.9表示合适,0.7-0.8表示一般,0.6-0.7表示尚可,0.5-0.6表示不太合适,0.5以下表示极不合适。
二. 主成分分析案例应用
欢迎参加这次双十一狂欢节购物状况调查满意度调查,我们是一个专注于双十一狂欢节购物服务研究的团队。感谢您同意分享您关于双十一狂欢节购物服务的想法。这次调查需要您5-8分钟宝贵的时间。本问卷采用不记名的形式,请您按照实际感受如实回答以下问题。如果您对这次研究的总体报告感兴趣,请您在调查留下电子邮箱地址。谢谢! 本调查包括74个题目,从多方面,多角度对调查主题进行了评测。
现在以该调查为依据进行主成分分析,尝试从众多变量指标中抽取出能够包含原始便利阿宁大多数信息的少数综合指标,以简化问题的研究。
- 导入数据

2. 选择变量
选择“分析”|“降维”|“因子分析”,打开因子分析对话框。选择左侧框中变量,单击=》箭头,将其选入“变量”列表框。注意主成分分析和因子分析适用的是数值型变量,因此选入分类数据。
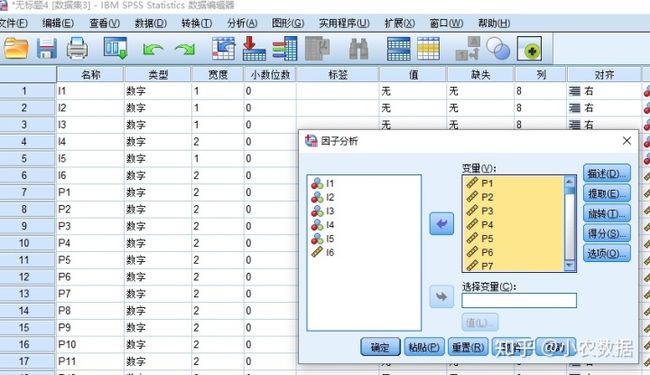
3. 统计量设置
单击“描述”按钮,打开“因子分析:描述统计”对话框。该对话框包括“统计”和"相关性矩阵”两个选项组。本例子选择默认设置“原始分析结果”和“KMO和Bartlett 球形检验”。单击“继续”按钮返回。

4. 主成分抽取设置
单击“提取”按钮,打开“因子分析:提取”对话框,如下设置,然后返回。

5. 旋转方式设置
单击“旋转”按钮,打开“因子分析:旋转”对话框,该对话框用于因子分析时的旋转方式设置。因此本例子不做选择,保持默认选择无。

6. 得分保存设置
单击“得分”按钮,打开“因子分析:因子得分”对话框。选中“保存为变量”复选框,将主成分分析得分保存于工作数据中,方法选择“回归”;然后选中“显示因子得分系数矩阵”复选框,单击“继续”返回。

7. 选项设置
单击“选项”按钮,打开“因子分析:选项”对话框,该对话框用于对缺失值的处理和系数显示格式的设置。单击“继续”按钮,返回“因子分析”。

8。 输出分析结果
对话框设置完毕,单击“确定”按钮,SPSS输出分析结果
9. 分析结果解读
(1)下表是KMO和Bartlett检验结果。从中可以看出,KMO取样适合度检验统计量为0.941的高水平,说明案例中变量之间的信息重叠程度很高,相关度很大。Bartlett检验卡方值16104.441,p值0.000,达到及其显著的水平。两种检验都表明,该例子适合主成分分析。

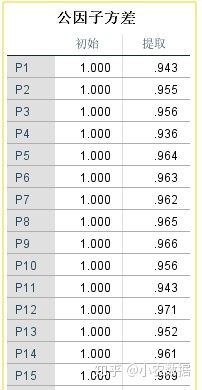
(2)公因子方差表示各变量所包含的信息能够被提取的主成分所表示的程度,也称为“共同度”。“初始值”表示每个变量演示信息均为1,即100%。而“提取”栏表示该变量的方差能被主成分所表示的程度,可以看出,变量的方差能被主成分解释在90%以上。
(3)下表给出了提取的主成分的方差总解释量。可以看出,每个主成分能解释的方差的比例不同。第1主成分特征值为61.78,解释原始变量的方差比例为90.853.

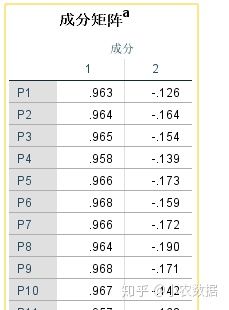
(4) 下表给出了2个主成分的成分矩阵,也称为因子载荷,实质是指个主成分和个原始变量的相关系数。通过因子载荷矩阵可以得到原始指标变量的线性组合,如P1=a11*F1+a12*F2其中P1为指标变量1,a11、a12分别为与变量P1在同一行的因子载荷,F1、F2分别为提取的公因子。主成分表达式中相关系数值越大,表示该主成分对原始变量的代表性越大。可以看出,第一主成分y1与个原始变量的关系是2个主成分中较大的,说明它对原始变量的解释量最多。
(5)下表是2个主成分的得分系数。根据主成分得分系数,就可以计算出每个受访者在2个主成分上的得分。假设用X1,X2, ....X74表示所有标准化的原始变量,用F1,F2表示主成分得分。那么就可以得出如下的得分函数 F1=0.019X1+0.019X2+......0.019X74. 简单来说,因子载荷和得分的区别,前者使用主成分来表示原始变量,而后者是用原始变量表示主成分。

(6)下表是成分得分的协方差矩阵,由于2个主成分互不相关,经过标准化,因此成分得分的协方差矩阵为单位矩阵,即主成分之间的协方差均为0,每个主成分的方差均为1.

(7)最后我们看一下碎石图。它显示了各个主成分的重要程度,横轴为主成分序号,纵轴为特征值大小。系统选取特征值大于1的前两个成分。
总之,主成分分析本质上是一种矩阵变换,通过矩阵变换,获得主成分的载荷矩阵,并据此推导出主成分的共同度,方差贡献率等统计量,她并不要求各个主成分具有实际意义。
