Vision Transformer 必读系列之图像分类综述
号外号外:awesome-vit 上新啦,欢迎大家 Star Star Star ~
https://github.com/open-mmlab/awesome-vitgithub.com/open-mmlab/awesome-vit
Vision Transformer 必读系列之图像分类综述(一):概述
Vision Transformer 必读系列之图像分类综述(二): Attention-based
Vision Transformer 必读系列之图像分类综述(三): MLP、ConvMixer 和架构分析
Pytorch版 Vision Transformer(VIT)模型的复现详解
ViT详解
Self-Attention以及Multi-Head Attentio详解
0 前言
随着 Vision Transformer 不断刷新各个领域的 SOTA,其优异的性能和广阔的发展前景使其得到了越来越多的关注。前段时间 OpenMMLab 也进行专项开发,对各个 repository 进行了一致性支持,具体可见:
OpenMMLab:做 Transformer, OpenMMLab 了解一下?96 赞同 · 1 评论文章正在上传…重新上传取消
鉴于大家对 Vision Transformer 如此关注,我们特推出了 Vision Transformer 必读系列文章,希望可以给大家带来一定的思考和启发。
按目前规划,该系列将覆盖图像分类、目标检测和语义分割三大方向,共计约5篇文章。后续还将对某篇或者某类主流算法结合 OpenMMLab 开源库的具体实现进行更加深入的解读,欢迎大家持续关注。
不仅如此,我们还特意新开了一个开源库,所有关于 Vision Transformer 相关的资料都会在这里持续更新,大家也可以在这里直接获取相关源文件。邀请大家共同来改进和维护,如果觉得 repository 对你有帮助,欢迎 Star ,感谢支持~
https://github.com/open-mmlab/awesome-vitgithub.com/open-mmlab/awesome-vit
本文是图像分类方向的开篇,将对 Transformer 和 Vision Transformer (ViT) 进行解读,同时还将对 ViT 后续发展进行系统性概述,方便大家把握方向,是本系列文章的重点内容(由于图像分类内容众多,本文仅仅是全局概述,不涉及思维导图中每篇论文,具体分析在系列二和系列三中描述)。
需要强调的是 MMClassification 框架中已经复现了 ViT 和 TnT 等视觉 Transformer 算法,并且也在不断地完善,有兴趣的朋友可以 Star,感谢支持~
https://github.com/open-mmlab/mmclassificationgithub.com/open-mmlab/mmclassification
ViT 进展汇总思维导图如下图所示:
接下来就让我们进入正文吧~
1 Transformer 和 Vision Transformer 简要说明
Transformer 结构是 Google 在 2017 年为解决机器翻译任务(例如英文翻译为中文)而提出,从题目 Attention is All You Need 中可以看出主要是靠 Attention 注意力机制,其最大特点是抛弃了传统的 CNN 和 RNN,整个网络结构完全是由 Attention 机制组成。为此需要先解释何为注意力机制,然后再分析模型结构。
Attention 注意力机制不是啥新鲜概念,视觉算法中早已广泛应用,典型的如 SENet。
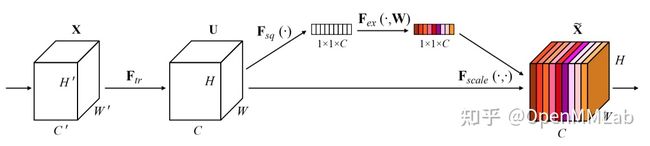
利用 Squeeze-and-Excitation 模块计算注意力权重概率分布,然后作用于特征图上实现对每个通道重加权功能。
人生来就有 Attention 注意力机制,看任何画面,我们会自动聚焦到特定位置特定物体上。对于输入给网络的任何模态,不管是图像、文本、点云还是其他,我们都希望网络通过训练能够自动聚焦到有意义的位置,例如图像分类和检测任务,网络通过训练能够自动聚焦到待分类物体和待检测物体上。一个典型的 Transformer 结构如下图所示:
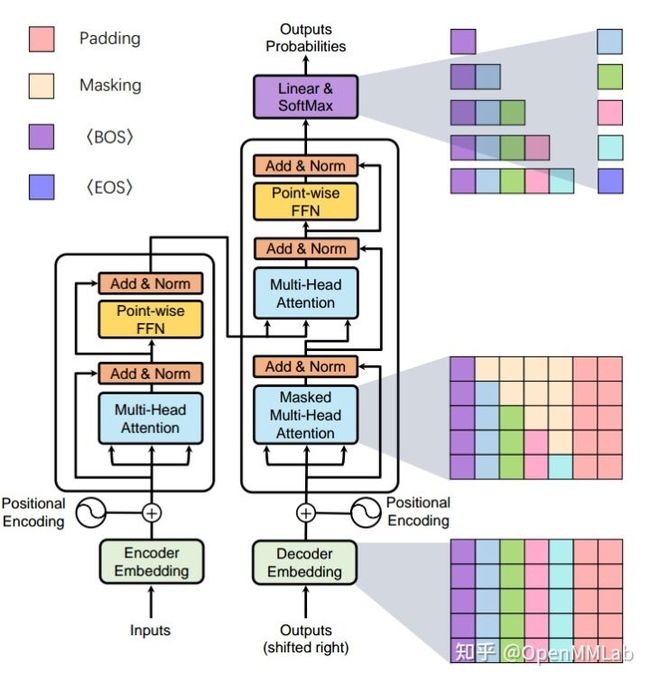
上图来自 A Survey of Visual Transformers 文章。
通常来说,标准的 Transformer 包括 6 个编码器和 6 个解码器串行。
- 编码器内部接收源翻译输入序列,通过自注意力模块提取必备特征,通过前向网络对特征进行进一步抽象。
- 解码器端输入包括两个部分:一是目标翻译序列经过自注意力模块提取的特征,二是编码器提取的全局特征。这两个输入特征向量会进行交叉注意力计算,抽取有利于目标序列分类的特征,然后通过前向网络对特征进行进一步抽象。
- 堆叠多个编码器和解码器,下一个编解码器接收来自上一个编解码的输出,构成串行结构不断抽取,最后利用解码器输出进行分类即可。
图片分类中通常不需要解码器模块,所以我们只需要关注编码器部分,其中主要是位置编码模块 Positional Encoding、多头自注意力模块 Muti-Head Attention、前向网络模块 Feed Forward 以及必要的 Norm、Dropout 和残差模块。
- 位置编码模块 Positional Encoding 用于给输入的序列增加额外的位置信息。
- 多头自注意力模块 Muti-Head Attention 用于计算全局空间注意力。
- 前向网络模块 Feed Forward 用于对通道维度信息进行混合。
- 必要的 Norm、Dropout 和残差模块提供了更好的收敛速度和性能。
ViT 是第一次成功将 Transformer 引入到视觉领域的尝试,开辟了视觉 Transformer 先河。其结构图如下所示:
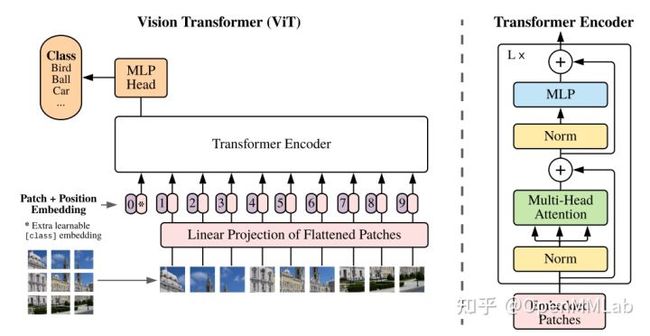
其做法非常简单,简要概况为:
- 将图片分成无重叠的固定大小 Patch (例如 16x16),然后将每个 Patch 拉成一维向量, n 个 Patch 相当于 NLP 中的输入序列长度(假设输入图片是 224x224,每个 patch 大小是 16x16,则 n 是 196),而一维向量长度等价于词向量编码长度(假设图片通道是 3, 则每个序列的向量长度是 768)。
- 考虑到一维向量维度较大,需要将拉伸后的 Patch 序列经过线性投影 (nn.Linear) 压缩维度,同时也可以实现特征变换功能,这两个步骤可以称为图片 Token 化过程 (Patch Embedding)。
- 为了方便后续分类,作者还额外引入一个可学习的 Class Token,该 Token 插入到图片 token 化后所得序列的开始位置。
- 将上述序列加上可学习的位置编码输入到 N 个串行的 Transformer 编码器中进行全局注意力计算和特征提取,其中内部的多头自注意模块用于进行 Patch 间或者序列间特征提取,而后面的 Feed Forward(Linear+ GELU+Dropout+ Linear+ Dropout) 模块对每个 Patch 或者序列进行特征变换。
- 将最后一个 Transformer 编码器输出序列的第 0 位置( Class Token 位置对应输出)提取出来,后面接 MLP 分类后,然后正常分类即可。
ViT 证明纯 Transformer 也可以取得非常好的效果,相比 CNN 在数据量越大的情况下优势更加明显,但是 ViT 也存在如下问题:
- 不采用超大的 JFT-300M 数据集进行预训练,则效果无法和 CNN 媲美,原因应该是 Transformer 天然的全局注意力计算,没有 CNN 这种 Inductive Bias 能力,需要大数据才能发挥其最大潜力。
- ViT 无法直接适用于不同尺寸图片输入,因为 Patch 大小是固定的,当图片大小改变时,序列长度就会改变,位置编码就无法直接适用了,ViT 解决办法是通过插值,这种做法一般会造成性能损失,需要通过 Finetune 模型来解决,有点麻烦。
- 因为其直筒输出结构,无法直接应用于下游密集任务。
上述仅仅是对 Transformer 和 ViT 进行简要分析,在下一篇文章中会进行更加细致的解释。
2 全局概述
简单来说,可以分成 3 大块以及 1 个额外部分,ViT 发展可以分成三个大方向:
- Attention-based, 这类算法是目前主流研究改进方向,包括了 Transformer 中最核心的自注意力模块。
- MLP-based,这类算法不需要核心的自注意力模块,而是简单的通过 MLP 代替,也可以取得类似效果。
- ConvMixer-based,这类算既不需要自注意力模块,也不是单纯依靠 MLP,而是内部混合了部分 Conv 算子来实现类似功能。
除了三个大方向,从其他视角出发,又包括一个额外的重要部分:General architecture analysis,在这三类算法基础上也有很多学者在探讨整个 Transformer 架构,其站在一个更高的维度分析问题,不局限于是否包括自注意力模块,属于整体性分析。
注意:本文为概述性总结,所以不会对思维导图中包括的每篇论文进行分析,其具体分析会在后续综述文章中详细说明。
2.1 Attention-based
Attention-based 是指改进论文中依然包括 Transformer 所提的 Attention 模块,可以认为 Attention 是核心。结构图如下所示:

从 ViT 出发,可以分成两个部分:
- 训练策略方面改进
- 模型方面改进
2.1.1 训练策略方面改进
如果说 ViT 开创了 Transformer 在视觉任务上面的先河,那么 DeiT 的出现则解决了 ViT 中最重要的问题:如果不采用超大的 JFT-300M 数据集进行预训练,则效果无法和 CNN 媲美。DeiT 核心是引入蒸馏手段加上更强的 Aug 和更优异的超参设置。其蒸馏的核心做法如下图所示:

额外引入一个蒸馏 Token 用于蒸馏学习,通过大量实验,作者总结了如下结论:
- 蒸馏做法确实有效,且 Hard 蒸馏方式效果会更好,泛化性能也不错。
- 使用 RegNet 作为教师网络可以取得更好的性能表现,也就是说相比 Transformer,采用卷积类型的教师网络效果会更好。
除了上述蒸馏策略,还需要特别注意 DeiT 引入了非常多的 Aug 并且提供了一套更加优异的超参,这套参数也是后续大部分分类模型直接使用的训练参数,非常值得学习,如下图:

DeiT 不是唯一一个解决 ViT 需要大数据量问题的算法,典型的还有 Token Labeling,其在 ViT 的 Class Token 监督学习基础上,还对编码器输出的每个序列进行额外监督,相当于将图片分类任务转化为多个输出 Token 识别问题,并为每个输入 Patch 的预测 Token 分配由算法自动生成的基于特定位置的监督信号,简要图如下所示:

从上图可以看出,相比 ViT 额外多了输出 Token 的监督过程,这些监督可以当做中间监督,监督信息是通过 EfficientNet 或者 NFNet ( F6 86.3% Top-1 accuracy) 这类高性能网络对训练图片提前生成的显著图,最终实验结果表明性能比 DeiT 更优异,而且由于这种密集监督任务,对于下游密集预测任务泛化性也更好。
2.1.2 模型方面改进
模型改进方面按照模块分成 6 个部分:
- Token 模块,即如何将 Image 转 Token 以及 Token 如何传递给下一个模块
- 位置编码模块
- 注意力模块,这里一般都是自注意力模块
- Fead Forward (FFN) 模块
- Norm 模块位置
- 分类预测模块
2.1.2.1 Token 模块
Token 模块包括两个部分:
- Image to Token 模块即如何将图片转化为 Token,一般来说分成有重叠和无重叠的 Patch Embedding 模块。
- Token to Token 模块即如何在多个 Transformer 编码器间传递 Token,通常也可以分成固定窗口 Token 化过程和动态窗口 Token 化两个过程 。

(1) Image to Token
ViT 和目前主流模型例如 PVT 和 Swin Transformer 等都是采用了非重叠 Patch Embedding,即将图片切分为不重叠的块,每个块单独进行 Embedding,最终输出 token 序列。
重叠 Patch Embedding 和非重叠 Patch Embedding 的主要差异在于窗口是否有重叠,直接将非重叠 Patch Embedding 通过修改 Unfold 或者 Conv 参数来实现重叠 Patch Embedding 功能的典型算法包括 T2T-ViT 和 PVTv2,这两个算法的出发点都是重叠 Patch Embedding 可以加强图片 Patch 之间的连续性,不至于出现信息断层,性能应该会比非重叠 Patch Embedding 高。
参考 ResNet 等网络的重叠渐进下采样策略,也有很多学者考虑引入 Conv Stem 结构来代替重叠 Patch Embedding,典型的如 Early Convolutions Help Transformers See Better 和 Token Learner 的作者,特别是 Early Convolutions Help Transformers See Better 的作者,他从优化稳定性角度入手,进行了深度分析,通过大量的实验验证了上述做法的有效性。作者指出 Patch Embedding 之所以不稳定,是因为该模块是用一个大型卷积核以及步长等于卷积核的卷积层来实现的,往往这个卷积核大小为 16*16,这样的卷积核参数量很大,而且随机性很高,从某种程度上造成了 Transformer 的不稳定,如果用多个小的卷积来代替则可以有效缓解。

(2) Token to Token
大部分模型的 Token to Token 方案和 Image to Token 做法相同,但是也有些算法进行了相应改造。经过整理,将其分成两种做法:
- 固定窗口 Token 化
- 动态窗口 Token 化
固定窗口是指 Token 化过程是固定或者预定义的规则,典型的重叠和非重叠 Patch Embedding 就是固定窗口,因为其窗口划分都是提前订好的规则,不会随着输入图片的不同而不同,而动态窗口是指窗口划分和输入图片语义相关,不同图片不一样,是一个动态过程,动态窗口 Token 化过程典型代表是 PS-ViT 和 TokenLearner。
PS-ViT 作者认为 ViT 采用固定窗口划分机制,然后对每个窗口进行 Token 化,这种做法首先不够灵活,而且因为图片本身就是密集像素,冗余度非常高,采用固定划分方法对于分类来说可能就某几个窗口内的 Token 实际上才是有意义的,假设物体居中,那么物体四周的 Token 可能是没有作用的,只会增加无效计算而已。基于此,作者设计了一个自适应采样的 Token 机制,不再是固定的窗口采样,而是先初始化固定采样点,如下图红色点所示,然后通过 refine 机制不断调整这些采样点位置,最终得到的采样点所对应的 Token 就是最有代表力的。其完整分类网络结构图如下所示:

基于类似出发点,TokenLearner 提出可以基于空间注意力自适应地学习出更具有代表性的 token,从而可以将 ViT 的 1024 个 token 缩减到 8-16 个 token,计算量减少了一倍,性能依然可以保持一致。
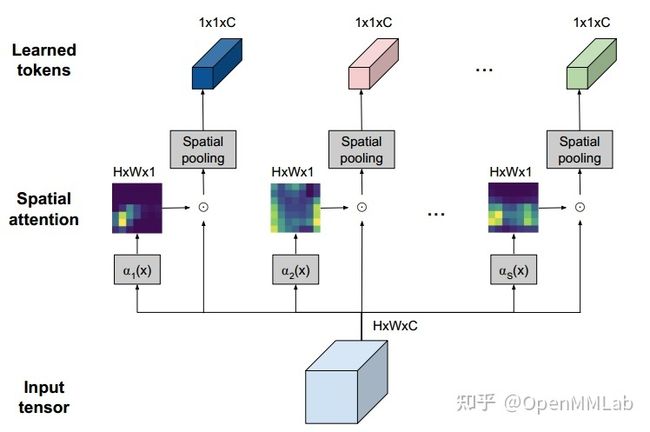
2.1.2.2 位置编码模块

位置编码模块是为 Transformer 模块提供 Patch 和 Patch 之间的相对关系,非常关键。按照是否显式的设置位置编码向量,可以分成:
- 显式位置编码,其中可以分成绝对位置编码和相对位置编码。
- 隐式位置编码,即不再直接设置绝对和相对位置编码,而是基于图片语义利用模型自动生成能够区分位置信息的编码向量。
其中显式位置编码,可以分成绝对位置编码和相对位置编码,并且每一种位置编码原则上都可以分成固定编码和可学习位置编码两种,而隐式位置编码是基于图片语义利用模型自动生成能够区分位置信息的编码向量,一般来说隐式位置编码对于图片长度改变场景更加有效,因为其是自适应图片语义而生成。
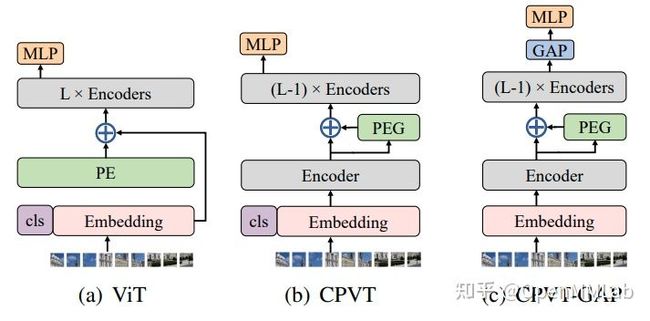
在论文 How much position information do convolutional neural networks encode? 中已经证明 CNN 不仅可以编码位置信息,而且越深的层所包含的位置信息越多,而位置信息是通过 zero-padding 透露的。既然 Conv 自带位置信息,那么可以利用这个特性来隐式的编码位置向量。大部分算法都直接借鉴了这一结论来增强位置编码,典型代表有 CPVT、PVTv2 和 CSWin Transformer 等。
基于此,CPVT 作者认为在视觉任务中一个好的位置编码应满足如下条件:
- 模型应该具有 permutation-variant 和 translation-equivariance 特性,即对位置敏感但同时具有平移不变性
- 能够自然地处理变长的图片序列
- 能够一定程度上编码绝对位置信息
基于这三个原则,CPVT 引入了一个带有 zero-padding 的卷积 ( kernel size k ≥ 3) 来隐式地编码位置信息,并提出了 Positional Encoding Generator (PEG) 模块,如下图所示:
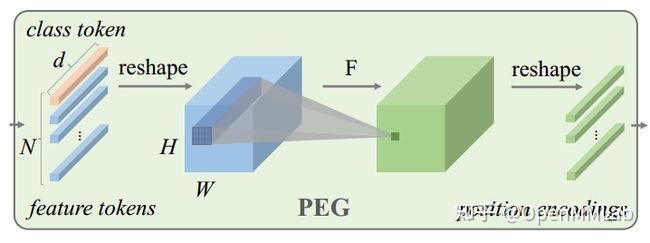
算法的整体结构图如下所示:
除了上述分析的加法隐式位置编码改进, ResT 提出了另一个非常相似的,但是是乘法的改进策略,结构图如下所示 :

对 Patch Embedding 后的序列应用先恢复空间结构,然后应用一个 3×3 depth-wise padding 1的卷积来提供位置注意力信息,然后通过 sigmoid 操作变成注意力权重和原始输入相乘。
2.1.2.3 自注意力模块
Transformer 的最核心模块是自注意力模块,也就是我们常说的多头注意力模块,如下图所示:
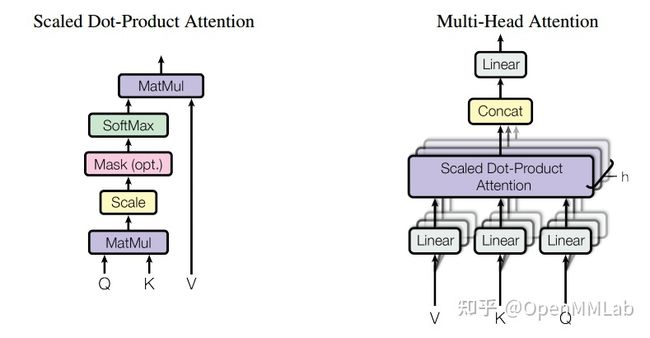
注意力机制的最大优势是没有任何先验偏置,只要输入足够的数据就可以利用全局注意力学到泛化性能不错的特征。当数据量足够大的时候,注意力机制是 Transformer 模型的最大优势,但是一旦数据量不够就会变成逆势,后续很多算法改进方向都是希望能够引入部分先验偏置辅助模块,在减少对数据量依赖的情况下加快收敛,并进一步提升性能。同时注意力机制还有一个比较大的缺点:因为其全局注意力计算,当输入高分辨率图时候计算量非常巨大,这也是目前一大改进方向。
简单总结,可以将目前自注意力模块分成 2 个大方向:
- 仅仅包括全局注意力,例如 ViT、PVT 等
- 引入额外的局部注意力,例如 Swin Transformer

(1) 仅仅包括全局注意力
标准的多头注意力就是典型的空间全局注意力模块,当输入图片比较大的时候,会导致序列个数非常多,此时注意力计算就会消耗大量计算量和显存。以常规的 COCO 目标检测下游任务为例,输入图片大小一般是 800x1333,此时 Transformer 中的自注意力模块计算量和内存占用会难以承受。其改进方向可以归纳为两类:减少全局注意力计算量以及采用广义线性注意力计算方式。
全局注意力计算量主要体现在 QK 矩阵相似性计算和输出经过 Softmax 后和 V 相乘部分,想减少这部分计算量,那自然可以采用如下策略:
- 降低 KV 维度,QK 计算量和 Softmax 后和 V 相乘部分计算量自然会减少,典型的如 PVT 。
- 减低 QKV 维度,主要如果 Q 长度下降了,那么代表序列输出长度改变了,在减少计算量的同时也实现了下采样功能,典型的如 MViT 。
PVT 核心是通过 Spatial Reduction 模块缩减 KV 的输入序列长度,KV 是空间图片转化为 Token 后的序列,可以考虑先还原出空间结构,然后通过卷积缩减维度,再次转化为序列结构,最后再算注意力,如下图所示:

MViT 是为视频任务所设计,其核心思想和 PVT 类似 。
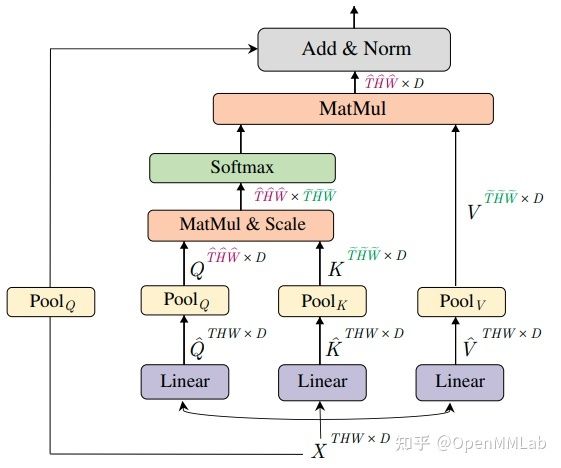
其在缩减 KV 空间尺寸的同时,也缩减了 Q 的尺寸,这意味着同时进行了输出下采样功能,而且后续提出的 Imporved MViT 在不同的下游任务提升也显著。
(2) 引入额外的局部注意力
局部注意力是指仅仅计算局部窗口的注意力,而并非全局,可以有效地减少计算量。需要特别注意的是:
- 引入局部窗口注意力后依然要提供跨窗口信息交互模块,不可能只存在局部注意力模块,因为这样就没有局部窗口间的信息交互,性能会出现不同程度的下降,也不符合 Transformer 设计思想( Patch 内和 Patch 间信息交互),这个跨窗口信息模块可以是全局注意力模块,也可以是任何可以实现这个功能的模块。
- 局部窗口计算模式和引入卷积局部归纳偏置增强的划分依据是其核心出发点和作用,而不是从是否包括 Conv 模块来区分。
引入额外局部注意力的典型代表是 Swin Transformer。其将自注意力计算过程限制在每个提前划分的窗口内部,称为窗口注意力 Window based Self-Attention (W-MSA),相比全局计算自注意力,明显可以减少计算量,但是这种做法没法让不同窗口进行交互,此时就退化成了 CNN,所以作者又提出移位窗口注意力模块 Shifted window based Self-Attention (SW-MSA),示意图如下所示,具体是将窗口进行右下移位,此时窗口数和窗口的空间切分方式就不一样了,然后将 W-MSA 和 SW-MSA 在不同 stage 之间交替使用,即可实现窗口内局部注意力计算和跨窗口的局部注意力计算,同时其要求 stage 个数必须是偶数。

Swin Transformer 算法在解决图片尺度增加带来的巨大计算量问题上有不错的解决方案,但是 SW-MSA 这个结构被后续诸多文章吐槽,主要包括:
- 为了能够高效计算,SW-MSA 实现过于复杂
- SW-MSA 对 CPU 设备不友好,难以部署
- 或许有更简单更优雅的跨窗口交互机制
基于这三个问题,后续学者提出了大量的针对性改进,可以归纳为:
- 抛弃 SW-MSA,依然需要全局注意力计算模块,意思是不再需要 SW-MSA,跨窗口交互功能由全局注意力计算模块代替,当然这个全局注意力模块是带有减少计算量功能的,典型的如 Twin 和 Imporved MViT。
- 抛弃 SW-MSA,跨窗口信息交互由特定模块提供,这个特定模块就是改进论文所提出的模块,典型的如 Shuffle Transformer 和 MSG-Transformer 等。
- CSWin Transformer 提出一种新的十字形局部窗口划分方式,具备跨窗口局部注意力计算能力,而不再需要分成 W-MSA 和 SW-MSA 两个模块,性能优于 Swin Transformer。
从引入 Conv 归纳偏置角度,也有不少高效的改进,典型的例如 ViTAE 和 ELSA: Enhanced Local Self-Attention for Vision Transformer 。
ViTAE 包括两个核心模块:Reduction Cell (RC) 和 Normal Cell (NC)。RC 用于对输入图像进行下采样并将其嵌入到具有丰富多尺度上下文的 token 中,而 NC 旨在对 token 序列中的局部性和全局依赖性进行联合建模,可以看到这两种类型的结构共享一个简单的基本结构。
对于 RC 模块,分成两个分支,第一条分支首先将特征图输入到不同空洞率并行的卷积中,提取多尺度特征的同时也减少分辨率,输出特征图拼接+ GeLU 激活,然后输入到注意力模块中,第二条分支是纯粹的 Conv 局部特征提取,用于加强局部归纳偏置,两个分支内容相加,然后输入到 FFN 模块中。
对于 NC 模块,类似分成两个分支,第一条是注意力分支,第二条是 Conv 局部特征提取,用于加强局部归纳偏置,两个分支内容相加,然后输入到 FFN 模块中。

而 ELSA 基于一个现状:Swin Transformer 种所提的局部自注意力(LSA)的性能与卷积不相上下,甚至不如动态过滤器。如果是这样,那么 LSA 的重要性就值得怀疑了。
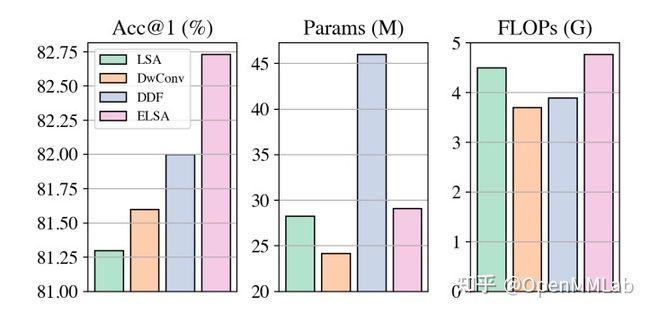
作者以 Swin Tiny 版本为例,将其中的局部窗口注意力模块 LSA 替换为 DW Conv、decoupled dynamic filter (DDF),从上图可以看出 DWConv 和 DDF 性能都比 LSA 强的,特别是 DW Conv,在参数量和 FLOPs 更小的情况下性能会比 Swin Transformer 高。
作者试图从两个角度来统一分析 LSA、DWConv 和 DDF,分别是通道数设置和空间处理方式 spatial processing,并进行了详细的对比分析,基于最终发现提出了改进的增强型 LSA 模块。
2.1.2.4 FFN 模块
FFN 模块比较简单,主要是进行通道维度的特征变换,主要改进是在引入 Conv 增强局部信息特征信息提取方面。

如下 (b) 和 (c) 所示,引入 1x1 卷积和带 padding 的 3x3 DW 卷积来增强局部特征提取能力,实验结果能够带来不少的性能提升。

2.1.2.5 Norm 位置改动
Norm 通常是 Layer Norm,按照该模型放在自注意力和 FFN 模块的前面还是后面,可以分成 pre norm 和 post norm 方式,至于应该选择 pre norm 还是 post norm,可能需要根据实验来选择。

2.1.2.6 分类预测模块
在 ViT 中通过追加额外一个 Class Token,将该 Token 对应的编码器输出输入到 MLP 分类头(实际上是一个线性投影层)进行分类。为何不能和我们常规的图像分类一样,直接聚合所有特征,而需要单独引入一个 Class Token ?这个问题自然有人进一步探索,经过简单总结,可以归纳为如下结构图:

2.1.2.7 其他
目前,其他包括两个内容部分,如下图所示:

主要探讨如何输出多尺度特征图以及如何训练更深的 Transformer。
(1) 如何输出多尺度特征图
在 CNN 时代的各种下游任务例如目标检测、语义分割中已经被广泛证明多分辨率多尺度特征非常重要,不同尺度特征可以提供不同的感受野,适合提取不同物体尺度的特征,然而 ViT 仅仅是为图像分类而设计,无法很好地应用于下游任务,这严重制约了视觉 Transformer 的广泛应用,故迫切需要一种能够类似 ResNet 在不同 stage 输出不同尺度的金字塔特征做法。
ViT 要输出多尺度特征图,最常见做法是 Patch Merging,其含义是对不同窗口的 Patch 进行合并,在目前主流的 PVT、Twins、Swin Transformer 和 ResT 中都有广泛的应用,以 PVT 为例详细说明,结构图如下所示:

假设图片大小是 (H, W, 3),暂时不考虑 batch 。
- 考虑将图片切割为 HW/(4X4) 个块,每个块像素大小是 4x4x3, 此处 stride=4。
- 将每个 4x4x3 像素块展开,变成一维向量,然后经过线性投影层,输出维度变成 C1,此时特征图 shape 是 (HW/(4X4), C1) 即每个像素块现在变成了长度为 C1 的向量,这两个步骤合并称为 Patch Embedding。
- 将上一步输出序列和位置编码相加,输入到编码器中,输出序列长度不变。
- 将这个输出序列恢复成空间结构,其 shape 是 (H/4, W/4, C1),此时特征图相比原始图片就下采样了 4x4 倍。
- 在下一个 stage 中改变 stride 数目,然后重复 1-4 步骤就又可以缩减对应 sxs 倍,假设设置 4 个 stage 的 stride 为 [4, 2, 2, 2],那么 4 个 stage 输出的 stride 就是 [4, 8, 16, 32],这个就和 ResNet 输出 stride 完全对齐。
除了上述这种相对朴素的做法,还有一些其他做法。例如 MViT ,其不存在专门的 Patch Merging 模块,而是在注意力模块中同时嵌入下采样功能,如下图所示:

只要在每个 stage 中改进 Pool 模块的 stride 就可以控制实现 ResNet 一样的多尺度输出,从而实现多分辨率金字塔特征输出。
(2) 如何训练更深的 Transformer
前述诸多论文都是在 6 层编码器的 Transformer 中进行改进,不过也有学者探讨如何训练更深的 Transformer,典型算法是 CaiT 和 DeepViT。
在 CaiT 算法中,作者从 Transformer 架构和优化关系会相互影响相互作用的角度出发进行探讨,而 DeepViT 不一样,他通过分析得出深层 Transformer 性能饱和的原因是:注意力崩塌,即深层的Transformer 学到的 attention 非常相似,这意味着随着 ViT 的层次加深,self-attention 模块在生成不同注意力以捕获多样性特征方面变得低效。
CaiT 主要从架构细节着手 :
- 提出 LayerScale,更合理的 Norm 策略使深层 Transformer 易于收敛,并提高精度。
- 提出 class-attention layers,class token 和 patch embedding 在最后融合,并且通过 CA 模块来更加高效地将patch embedding 信息融合到 class embedding 中,从而提升性能。
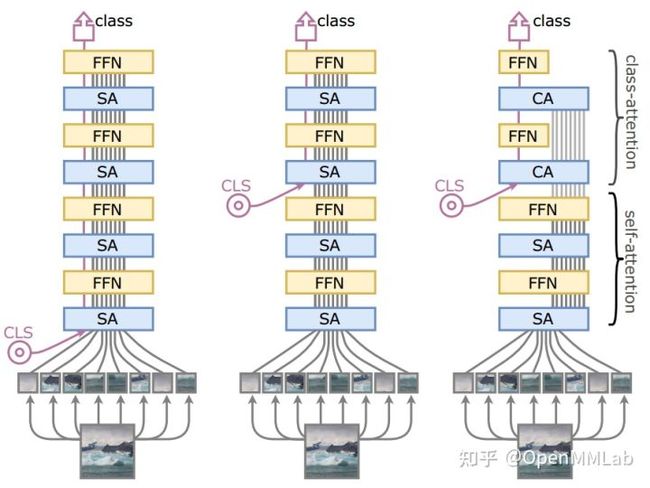
DeepViT 从注意力崩塌方面着手,提出了 Re-Attention 层来增加注意力层的多样性。

其结构图如下右图所示:

CaiT 和 DeepViT 都是关注深层 Transformer 出现的过早饱和问题,不过关注的地方不一样,解决办法也完全不同,但是效果类似,这或许说明还有很大的改进空间。
2.2 MLP-based

在视觉 Transformer 大行其道碾压万物的同时,也有人在尝试非注意力的 Transformer 架构(如果没有注意力模块,那还能称为 Transformer 吗)。相比 Attention-based 结构,MLP-based 顾名思义就是不需要注意力了,将 Transformer 内部的注意力计算模块简单替换为 MLP 全连接结构,也可以达到同样性能。典型代表是 MLP-Mixer 和后续的 ResMLP。

Mixer Layer 中整体结构和 Transformer 编码器类似,只不过内部不存在自注意力模块,而是使用两个不同类型的 MLP 代替,其分别是 channel-mixing MLPs 和 token-mixing MLPs,channel-mixing MLPs 用于在通道 C 方向特征混合,从上图中的 Channels (每个通道颜色一样)变成了 Patches (每个通道颜色不一样)可以明显看出其做法,而 token-mixing MLPs 用于在不同 patch 块间进行特征混合,其作用于 patch 方向。
2.3 ConvMixer-based

ConvMixer 的含义是:
- 不包括自注意力层
- 不包括 Spatial Mixer MLP 层
- 包括 Channel Mixer 层,这个层可以是 1x1 的点卷积,或者 MLP 层
因为 Channel Mixer MLP 层和 1x1 卷积完全等价,所以这里所说的 ConvMixer-based 是强调 Spatial Mixer 层模块可以替换为 DW 卷积。
ConvMixer-based 的典型代表是 ConvMixer,其结构图如下所示:

从 MLP-based 和 ConvMixer-based 中可以看出: ViT 这种架构的成功不在于是使用了自注意力模块还是 Spatial Mixer MLP,只要有相应的代替结构性能其实都差不多,我们可能要关注整个 Transformer 架构而不仅仅是注意力等模块,后续很多论文也慢慢发现了这点。
2.4 通用架构分析
前面所提出的 MLP-Mixer 和 ResMLP 已经证明了 ViT 成功的关键可能并不是注意力机制,而是来自其他地方或者说整体架构。基于这个出发点,有大量学者对整个架构进行深入研究,试图从更高维度的角度来理解 Transformer,如下所示:

以 MetaFormer 为例,结构图如下所示:

其核心观点和 ResMLP 一致,即 Transformer 模型中自注意力模块不是最核心的(并不是说可以直接去掉),Transformer 的成功来源其整体架构,同时可以将 Transformer 的 Attention 模块和 ResMLP 的 Spatial MLP 层统称为 Token Mixer,进而提出了 MetaFormer 通用结构,Meta 的含义代表 Token Mixer 是一种统称,只要能够实现 Token Mixer 功能的模型都属于 MetaFormer 范畴,例如你也可以将 Token Mixer 换成 3x3 DW 卷积。为了验证这个架构的可行性,作者将 Token Mixer 替换为最简单的无参数的 Pooling 算子,发现效果也是类似的。
如果说 MetaFormer 还有 Transformer 的影子,那么 ConvNeXt 就是一个更彻底的去 Transformer 的例子了。其核心出发点是纯粹的 Conv 堆叠性能能不能超过 Transformer? ConvNeXt 对 Swin Transformer 进行了逐模块分解,并且将其应用于 ResNet 上,通过不断对比两者差异,作者将 ResNet 改造为 ConvNeXt,性能最终超越 Swin Transformer,证明了纯粹的 Conv 堆叠性能能够超过 Transformer,这也间接说明 Transformer 架构和优化策略的优异性,而不是所谓的 Attention。

3 总结
ViT 的核心在于 Attention,但是整个架构也包括多个组件,每个组件都比较关键,有诸多学者对多个组件进行了改进。我们可以简单将 ViT 结构分成 6 个部分:
- Token 模块,其中可以分成 Image to Token 模块 和 Token to Token 模块, Image to Token 将图片转化为 Token,通常可以分成非重叠 Patch Embedding 和重叠 Patch Embedding,而 Token to Token 用于各个 Transformer 模块间传递 Token,大部分方案都和 Image to Token 做法一样即 Patch Embedding,后续也有论文提出动态窗口划分方式,本质上是利用了图片级别的语义自动生成最有代表性的采样窗口。
- 位置编码模块,其中可以分成显式位置编码和隐式位置编码,显式位置编码表示需要手动设置位置编码,包括绝对位置编码和相对位置编码,而隐式位置编码一般是指的利用网络生成自适应内容的位置编码向量,其提出的主要目的是为了解决显式位置编码中所遇到的当图片尺寸变化时候位置编码插值带来的性能下降的问题。
- 注意力模块,早期的自注意力模块都是全局注意力,计算量巨大,因此在图片领域会针对性设计减少全局注意力,典型做法是降低 KV 空间维度,但是这种做法没有解决根本问题,因此 Swin Transformer 中提出了局部窗口自注意力层,自注意力计算仅仅在每个窗口内单独计算,不再存在上述问题。
- FFN 模块,其改进方向大部分是引入 DW 卷积增强局部特征提取能力,实验也证明了其高效性。
- Normalization 模块位置,一般是 pre norm。
- 分类预测模块,通常有两种做法,额外引入 Class Token 和采用常规分类做法引入全局池化模块进行信息聚合。
随着研究的不断深入,大家发现 Attention 可能不是最重要的,进而提出了 MLP-based 和 ConvMixer-based 类算法,这些算法都是为了说明自注意力模块可以采用 MLP 或者 Conv 层代替,这说明 Transformer 的成功可能来自整个架构设计。
MetaFormer、An Empirical Study of CNN, Transformer, and MLP 和 Demystifying Local Vision Transformer 等论文都进一步详细说明和验证了上面的说法,并都提出了自己各自的看法。
从视觉 Transformer 进展来看,目前 CNN 和 Transformer 的边界已经越来越模糊了,相互可以等价替换,也可以相互增强,特别是 ConvNeXt 的提出更是验证了这一点。
下一篇文章会对 Attention-based 进行更加全面深入的总结,敬请期待!
对 Vision Transformer 系列内容感兴趣的朋友,不要忘记 star 啦~
https://github.com/open-mmlab/awesome-vitgithub.com/open-mmlab/awesome-vit