论文笔记:《Weakly Supervised Image Classification through Noise Regularization》
一、研究背景
弱监督学习在计算机视觉领域中是一个至关重要的任务。因为在视觉应用场景中,难以获取大量的clean label(需要经过人验证),但是我们可以通过一些预训练好的model去获得大量的noisy label(不精确或有错误)。所以如何利用大量noisy label数据去提高model的准确度和鲁棒性就显得十分重要。
当前在图像分类领域的弱监督学习方法大都会对noisy label的类型有一定的假设,即single-label noise或multi-label noise。单标签噪声可以在训练过程中引入类似聚类相似图像的方法[14],而多标签噪声可以使用标签与标签的关系来使算法更健壮[33](如下图)。这些方法虽然可以提高model的表现,但是单标签噪声学习方法不适用于多标签噪声的问题,多标签噪声的方法在单标签数据集上的效果未知。也就是在single-label和multi-label之间存在gap。
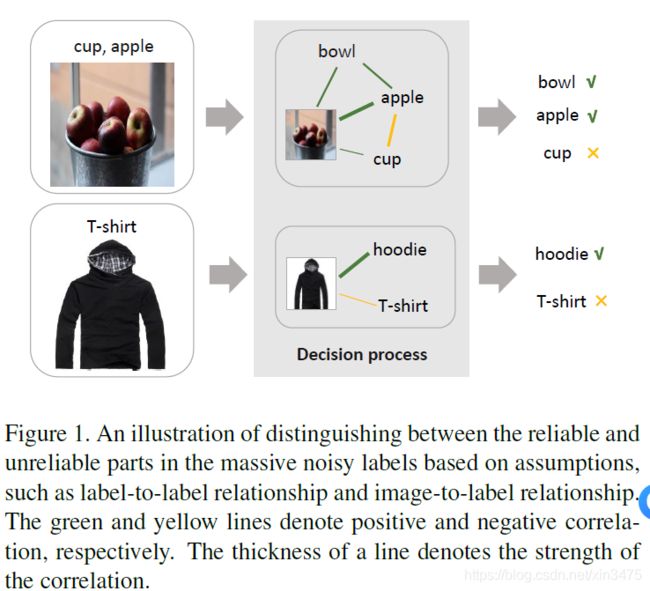
大多数弱监督图像分类方法试图只通过带有noisy label的数据去进行学习。主要为以下两类:
1、从全部的数据中去分辨出噪声数据,这些方法一般将焦点集中于去发现噪声数据和clean数据的不同。
2、从损失函数和网络结构上去实现noise robust learning。
本文的方法属于另一个支流,在有少量clean label已知的情况下。此类方法旨在利用带有少量的clean label的大量noisy label数据来学习鲁棒性强的图像分类器。与仅从带有noisy label的数据中学习相比,clean label可以在某种程度上将模型导向正确的方向。 此类方法的实验结果表明,即使是少量带有clean label的数据也对性能改善有积极的影响。本文的方法通过利用带有noisy label的数据去减少model对clean label数据的过拟合,以此来提高model的泛化能力。
除此之外一些研究还介绍了辅助信息(例如,知识图)以帮助提高模型对噪声标签的鲁棒性。但是,辅助信息有时与标签数据高度相关,这在某种程度上也限制了模型的泛化能力。
二、研究动机
利用大量的noisy label数据和少量的clean label数据(5%左右),去实现一个鲁棒性强的图片分类算法。
两个目的:
1、利用大量noisy label数据去增强分类算法的鲁棒性;
2、能在单类别和多类别分类问题中都有效果。
三、实现方法
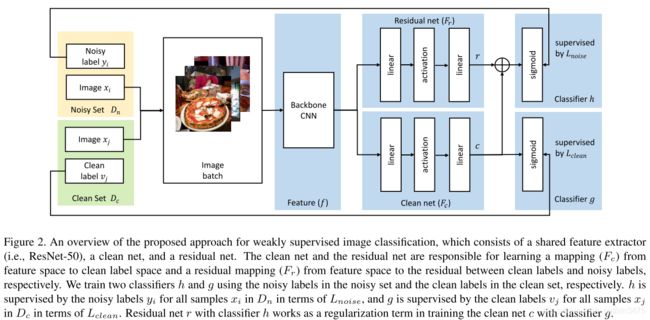
![]() 代表整个训练数据集,带有噪声标签的数据集
代表整个训练数据集,带有噪声标签的数据集![]() ,带有clean标签的数据集
,带有clean标签的数据集![]() ,且
,且![]() 。
。
如上图所示,这是一个多任务学习,分别训练了两个分类器g和h分别去拟合clean set和noisy set。Backbone CNN用来计算图像x的特征图f,特征被residual net和clean net共享。residual net和clean net为一个由两个线性层和一个激活函数构成的非线性变换。激活函数选择非线性的,如ReLU、tanh和sigmoid。此非线性转换用于学习从特征空间到clean label空间或noisy label空间的映射。 非线性激活比线性激活更好的原因是,共享特征空间f可能无法同时为带有clean label和noisy label的抽样提供判别能力。
3.1 Residual Net for Noise Regularization
g是最终得到的分类器。计算公式为:
![]()
![]()
如果仅用clean set去训练g的话,当clean set数据量比较少时,g很容易过拟合。因此引入分类器h去作为分类器g的一个正则化项。h被用于去学习特征空间向clean label和noisy label之间的映射。
![]()
![]()
在实验中,我们发现在应用Sigmoid函数之前将r和c的值相加有助于网络具有更好的收敛性。 因此,我们在进行Sigmoid运算之前先进行求和运算。 我们不需要明确地区分多标签和单标签数据。
可以将h视为g的正则项的原因与为什么在网络训练中使用权重衰减,dropout等正则化方法的原因相同。 它们都有助于缓解过度拟合的问题。 通过以上讨论,我们可以看到,residual网络可以对海量噪声数据中的不可靠部分建模,然后可以使分类器g利用海量噪声数据中的可靠部分来获得更鲁棒的图像 分类。 这样,residual网络就可以作为正则项来消除分类器g的过拟合问题。
3.2 Network Training
h和g的损失函数都采用二元交叉熵,h通过Dn中的所有样本进行监督训练,g通过Dc中的所有样本进行监督训练。
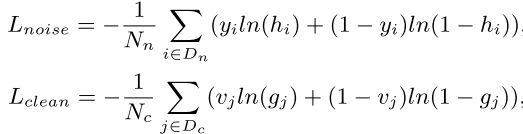
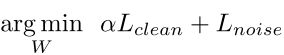
训练时联合利用noisy labeled data和clean labeled data,每个batch从Dc和Da中的抽样比例为1:9。backbone CNN的初始权重使用ImageNet与训练好的权重。在多标签分类时,用noisy labeled data去fine-tune CNN,然后只训练residual net和clean net。在单标签分类时,直接fine-tune整个网络。
四、实验
4.1 数据集
使用了COCO 2014和OpenImage作为多标签分类的数据集,使用Clothing1M作为单标签分类的数据集。
使用COCO数据集时,首先必须移除出现在COCO中但是不在ImageNet中的类别,剩余56类,其映射的标签为clean label。然后使用ImageNet pre-trained Inception V3 model去生成所有图片的前8个预测,并将它们映射到56个标签类。这些自动生成的标签可以视为有噪声的标签。我们删除了未标记的图像,最后获得了三套用于训练,验证和测试的图像。
OpenImage数据集是用于图像分类的公共多标签数据集。 它包含超过9M张图像,这些图像带有来自6,012个唯一类的带有机器注释的标签。 自提出以来,此数据集有许多版本。 我们采用第一个版本来评估我们的方法。 它在训练集中包含9,011,219张图像(带有噪音标签的数据),在验证集中包含167,056张图像(带有噪音标签和干净标签的数据)。 按照中的划分,我们使用整个训练集和四分之一的验证集(约40K图像)来训练模型,并使用验证集中的剩余图像进行测试。
Clothing1M数据集是用于单标签噪声学习的广泛使用的数据集。 它是在2015年提出的。它包含带有14个类别的带有噪声标签的1亿个衣服图像。 与OpenImage中的嘈杂标签类型和MS-COCO的编译(由预训练模型进行注释)不同,Clothing1M中的标签会被现实中的噪声破坏。 该数据集中每个图像的嘈杂标签由其周围文本的关键字分配。 对于带有清晰标签的图像,将其分为训练,验证和测试,大小分别为50K,14K和10K。
4.2 指标
多标签分类:mAP(AP的平均)和APall()
单标签:AP

4.3 多标签图像分类结果
与其它方法对比(本文优秀)
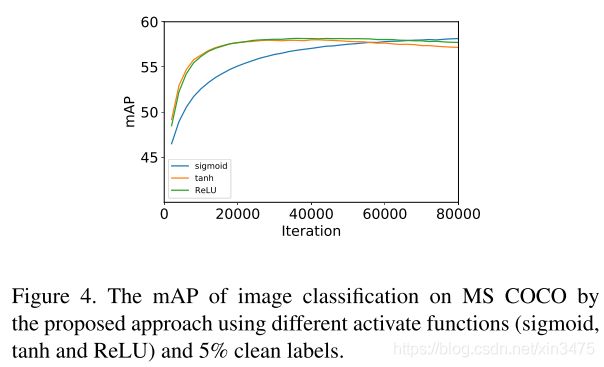
不同的激活函数对比(最终结果近似,收敛速度不同)
clean label所占比例不同对比(当然比例越高越好)
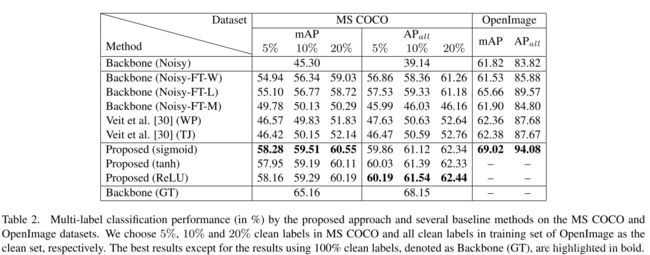

Backbone(Noisy):使用数据集中的所有嘈杂标签对骨干网络进行多标签分类训练。 可以将其视为所有使用干净标签的方法的下限。
Backbone(GT):使用数据集中的所有干净标签对骨干网络进行多标签分类训练。 可以将其视为所有使用干净标签的方法的上限。 应该注意的是,由于缺少整个OpenImage数据集的干净标签,仅对MS(COCO)进行了背景(GT)训练。
Backbone(Noisy-FT-W):使用干净集中的干净标签微调整个主干网(嘈杂)。 这种方法直接使用干净的标签来训练大型网络,当干净的标签很少时,该网络很可能会过拟合。
Backbone(Noisy-FT-M):在干净的集中用混合标签微调骨干网的最后一层(嘈杂)。 混合标签由干净组的干净标签和嘈杂组的嘈杂标签组成(比例为1:9)。
Backbone(Noisy-FT-L):使用干净的标签清洁微调骨干网的最后一层(嘈杂)。 这种方法通过减少训练中的参数来缓解过度拟合的问题。
Table2分析:
1、所有的弱监督学习都能提高Backbone(Noisy)的表现,哪怕只用5%。随着clean label所占比例的增高,效果更好。
2、本文的方法效果比之前好。从Table3可以看出本文的方法可以使用更小比例的clean label去实现其它方法的最优结果。
验证了本文方法的有效性。可视化结果如下图。

4.4 单标签图像分类
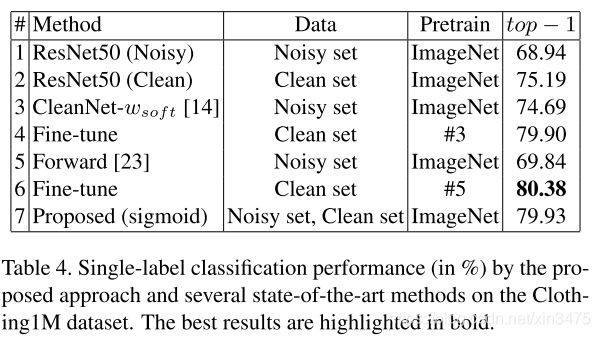
Baseline:CleanNet 、 Forward(only use noisy data)->Fine-tune(use clean data),ResNet50(Noisy)、ResNet50(clean)
本文方法与其它方法比较的特点:
1、可以在多标签和单标签通用。
2、noisy label和clean label是同时使用的,不是分别使用。

4.5 Residual Net的影响
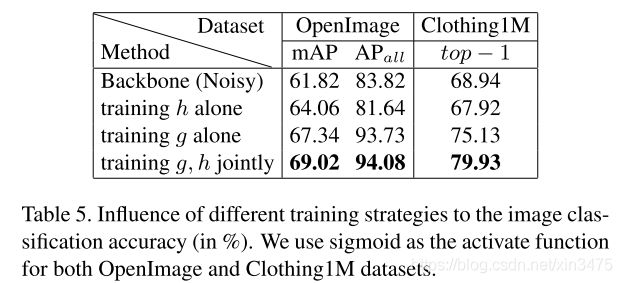
结果表明,由Residual Net从大量带噪标签数据中识别出的可靠信息可以改善分类器g在单标签和多标签图像分类任务中的性能。
补一张个人理解的训练流程图:
