推荐系统_各种方法的损失计算过程
如何构造一个更好的语义特征向量是各个推荐算法的核心。
除了用户购买商品的记录文件,我们还有两类文件,即用户属性文件(性别,年龄,职业等),商品属性文件(发行日期,种类等),一个商品属性中的种类可以有多个值,即商品及属于这一种类也属于另一种类。
1:BPR
最基本的推荐算法是基于朴素贝叶斯思想(BPR)的协同过滤算法,在这个算法里面用到两种数据,即用户和购买商品矩阵。根据每个用户及其购买的商品,我们可以构造正样本,即用户购买过的商品为正样本,用户未购买的样本为负样本。
首先将用户(944维)和商品(1683维)(都为整型)用nn.embeddind()模块表示成向量(94464,168364)。只有通过转换成高维的向量,这样才能更好的拥有语义信息,通过计算损失,反向传播,不断更新其中的语义信息。
如何构建负样本?在这里我们为每一个正样本构建一个负样本,即每一个用户和其购买的一个商品构成正样本,那么这个用户和其未购买的商品就构成了负样本。在这里,我们首先将每个用户购买的所有的商品聚集到一起,这样我们就得到了944个集合,每个集合代表的是用户所购买的所有商品。之后我们采用批量采样的模型,每次采样2048个。在这2048个样本中包括用户ID以及其对应的正样本,之后我们根据用户ID集合拷贝一份,对每个ID进行负采样,首先随机生成2048个从1到1683之间的数字,然后打乱顺序。这些生成的数字暂时假定为“负样本”,我们根据数组ID以此判断所生成的“负样本”是否合法,对于每个用户ID我们判断生成的“负样本”是否在正样本集合中,如果在正样本集合中,我们保存用户ID所对应的数组ID,统计数量,对于这些在正样本集合的“负样本”,我们在随机生成一批次。重复上面过程,只到统计数量为0。表明所有生成的负样本符合条件。
通过上面的操作我们就得到了2048条数据,每条数据包括用户ID,正商品ID,负商品ID。我们将用户ID正商品ID,就得到了正样本评分,我们将用户ID负商品ID,就得到了负样本评分。我们将正样本评分和负样本评分放入BPRLoss()函数中,BPRLoss()函数工作原理,正样本评分-负样本评分,然后取sigmoid,之后取log,然后再取均值,然后再去负号。这样就得到了损失,之后我们将损失方向传播,利用优化器,就完成了一次参数的更新。这样我们经过N次批次操作将所有训练数据训练完成,参数也更新完成。
2:XdeepFM
根据用到的数据类别不同,我们可以将用到用户购买商品的记录文件,用户属性文件,商品属性文件的推荐算法记为XdeepFM, 此算法也是因子分解机算法。
对于上面的三个文件,数据分为三类,整型,浮点型,和序列型。
对于整型数据可以直接利用nn.embedding()变成64维度,可以对应行号索引,对于序列型,比如电影种类,如何进行embedding(), 首先我们获取每个商品的种类,取最大种类为每个商品种类的长度,将种类长度不足的商品padding成最大种类的商品长度,以方便下面的计算。之后我们我们创造一个masking矩阵,矩阵的长为最大商品种类数量,宽为商品数。之后我们将总的商品种类embedding()成64维。根据每个商品所对应的种类,获取embedding()后的向量,然后将这个向量和masking向量相乘。之后在对相乘之后的向量相加求均值,最大值,最小值,总和。这样我们就表示出了序列型所对应的embedding()。对于浮点型数据,比如时间戳,一个批次2048个,我们先同时初始化相同的64位矩阵,即这2048个时间戳表示的一样,我们拿初始化后的时间戳乘上原始的时间戳即可得到表征后的时间戳。

xDeepFM的数据输入:
xdeepfm_input = torch.Size([2048, 8, 10])
8代表着种属性,10表示每种属性表示成10维度。
框架介绍:
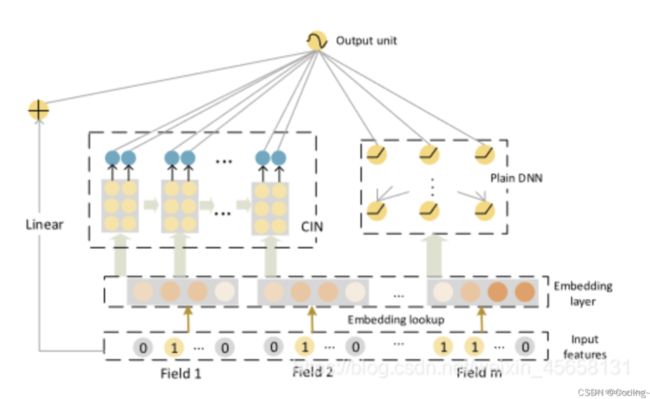
对于XDeepFM系统
主要分为3个部分
1:Linear层
将经过变换的input数据经过线性层输出,
Linear(in_features=200, out_features=1, bias=False)
线性层的结构:y= W*x + b;
输出为(2048,1)
2:DNN层
[80, 128, 128, 128, 1]
输入是80维度,经过三层MPL输出1维。
首先对80的输入进行dropout,然后输入变为128维度的输出进行relu().relu()函数表达式为Y(x) = Max(0,x)。使得输出的128维度的值都大于等于0。之后对128维的输入进行dropout,然后输入变为128维度的输出进行relu().relu()函数表达式为Y(x) = Max(0,x)。使得输出的128维度的值都大于等于0。之后对128维的输入进行dropout,然后输入变为128维度的输出进行relu().relu()函数表达式为Y(x) = Max(0,x)。使得输出的128维度的值都大于等于0。之后对128维的输入进行dropout,然后输入变为1维度的输出。输出为(2048,1)
3:CIN层
CIN层是压缩交互网络,是结合了RNN和CNN思想。
首先CIN网络是self.cin_layer_size =[100, 100, 100]三层。
数据的输入是xdeepfm_input=[2048, 8, 10]即:2048批次数据,每一个数据[8,10]维度。
输出特征的通道数等于卷积核的个数,卷积核的通道数等于输入数据的通道数,即卷积核的通道数等于10。
第一个Conv1d,输入是88=64通道,输出100通道。即我们用100个卷积核每个卷积核的通道数为64的卷积。输出的100通道被spilt()成resualt=50通道,nextinput = 50通道,
第二个Conv1d,输入通道是850通道(上一次的输入),输出是100通道,即我们用100个卷积核每个卷积核的通道数为400的卷积。输出的100通道被spilt()成resualt=50通道,nextinput = 50通道,
第二个Conv1d,输入通道是8*100/2,输出是100通道,即我们用100个卷积核每个卷积核的通道数为400的卷积。输出的100通道成resualt=100通道。
之后将三次的输出50,50,100通道cat()起来变成200通道。
对整个批次的输出(2048,200)接一个线性层输入是2048通道,输出是1。结果变成(2048,1)
之后将3次的输出结果(2048,1),(2048,1),(2048,1)对应相加。变成(2048,1),之后对值取sigmord()使得取值变为(0~1)之间。现在求出来2048批次数据所对应的得分。
损失计算
首先我们对三部分模型参数值进行L2正则,算出所有的模型参数的损失即为L2Loss。之后根据2048批次得分和2048批次标签值算出BCELoss()损失。BCELoss()+W*L2Loss()即为总的损失。
3:LightGCN
根据用户购买商品的记录文件,以及轻量级的图卷积神经网络(GCN),该推荐算法记录为LightGCN,根据图卷积网络知识将用户和商品信息嵌入到语义特征向量中。
LightGCN用到的数据如下所示:

用torch.nn.Embedding(num_embeddings=self.n_users, embedding_dim=self.latent_dim)方式随机初始化user和item 矩阵(944,64)和(1683,64)。之后用cat函数将数据cat到一起结果为all_embeddings。之后利用torch.sparse.mm(self.norm_adj_matrix, all_embeddings)方式将带图关系的embedding的self.norm_adj_matrix([2627, 2627])和all_embeddings向结合,以使得all_embeddings带有图的更好的语义向量信息。设置n_layer为2即我们需要将self.norm_adj_matrix和all_embeddings乘三次,每次获取乘操作后的all_embeddings,将all_embeddings进行append()到list中,然后用这次的all_embeddings再进行和self.norm_adj_matrix相乘的操作,重复3次,使得list的长度为3,之后对这个list进行torch.stack(embeddings_list, dim=1)操作,使得结果为torch.Size([2627, 3, 64])的形式。之后对其进行下面的操作,在1维度上进行求均值。结果输出为:[2627, 64]。即我们最后获取了嵌入了图语义信息的向量。
之后我们对其求BPRloss()即将正样本和负样本分别成商品,然后将得分放入到BPR损失函数中,求出损失。求reg_loss()损失,self.reg_loss(u_ego_embeddings, pos_ego_embeddings, neg_ego_embeddings) 对参数求regularation 损失。之后将上面两种损失加权求和即为kg_calculate_loss。
4:RippleNet
根据用户购买商品的记录文件,知识图谱文件,以及链接文件,该算法记录为RippleNet。
RippleNet用到的数据如下所示:

每次传入2048个用户,我们根据self.ripple_set()分别获取用户所对应的两级关系,关系包括第一层(头memories_h[0],关系memories_r[0],尾memories_t[0])和第二层(头memories_h[1],关系memories_r[1],尾memories_t[1])。之后分别将这两层进行embedding。结果为:h_emb_list为2*[32768, 64]。r_emb_list为2*[32768, 64],t_emb_list为2*[32768, 64]。
5:KGAT
根据用户购买商品的记录文件,知识图谱文件,链接文件,以及图卷积神经网络,该算法记录为KGAT。
用ego_embeddings = nn.Embedding(self.n_users, self.embedding_size)方式获取随机初始化的矩阵,将获取的矩阵ego_embeddings传入aggregator(self.A_in, ego_embeddings),获取输出 ego_embeddings1,然后将获取的输出进行normalize,传入F.normalize(ego_embeddings, p=2, dim=1)。将进行完正则化的数据进行输出user_all_embeddings, entity_all_embeddings。这个过程相当于对数据加上了可以学习的W。
数据主要用到知识图谱文件,购买商品的记录文件。
对于calculate_loss 用到购买商品的记录文件,但是嵌入embedding的时候用到了kg。

之后我们根据user_id,item_id,neg_item_id以及含有知识图谱信息的user_all_embeddings, entity_all_embeddings获取对应的语义向量。
之后根据u_embeddings,pos_embeddings,neg_embeddings进行lose计算。一个损失是BPR()损失,另一个为regularization正则化损失。之后将两者损失加权相加。便得到了calculate_loss。
对于kg_calculate_loss 用到知识图谱文件,并且用到了attention机制。

如何获取更好的特征向量。
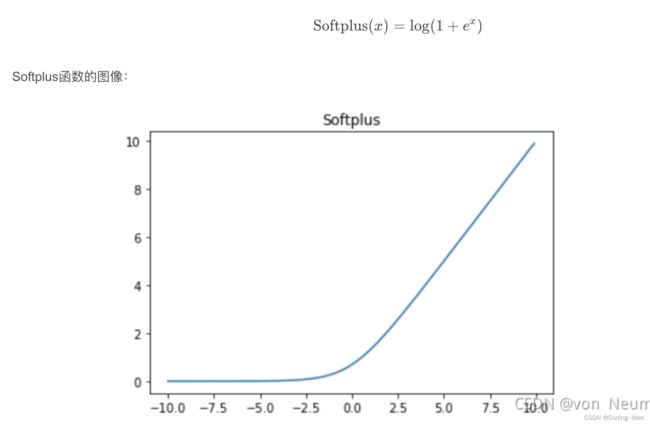
首先我们将 h_e,pos_t_e,neg_t_e添加一个维度unsqueeze(1)。利用self.trans_w®.view(r.size(0), self.embedding_size, self.kg_embedding_size)获取r_e的特征向量torch.Size([2048, 64, 64])。这一步有点attention的意思,及在r_e特征维度中中加入了attention机制。之后用torch.bmm(h_e, r_trans_w).squeeze() 方式分别获取嵌入了关系特征的语义特征向量。即h_e,pos_t_e,neg_t_e,r_e。之后计算正负样本的得分,即pos_tail_score= (h_e + r_e - pos_t_e) ** 2,neg_tail_score = (h_e + r_e - neg_t_e) ** 2。之后对正负样本得分求softpuls()损失。softpuls()函数为:
之后再对参数求regularation 损失。之后将上面两种损失加权求和即为kg_calculate_loss。
6:GRU
根据用户购买商品的记录文件,加入序列模型RNN,即(GRU),该算法记录为GRU。序列模型还有一个好处,不需要用户的信息,即不需要用户属性文件,以及用户ID。之与用户的行为有关,比如用户浏览,收藏,某个文章,我们可以在规定的时间内收藏用户的相关的文件。根据相同的行为推荐相关的产品。
GRU模型用到用户购买商品的记录文件。

item_seq_len=50,即在一定的时间内每一个用户购买了50个商品,对于用户数不足的padding成50个,对于用户购买超过50个的取出前50个。这样我们便得到item_seq,形式为(2048,50)。利用self.item_embedding(item_seq)函数将item_seq随机初始化为64维的数据(2048,50,64)即名字为item_seq_emb 。数据的形式为torch.Size([2048, 50, 64])。
将数据torch.Size([2048, 50, 64])分别用两个类型的GRU进行特征的抽取。
第一个GRU提取item之间的特征信息。然后我们对item_seq_emb进行dropout处理,即将item_seq_emb中的数据以概率随机将输入张量的一些元素归nn.Dropout(self.dropout_prob)。输出的数据为:torch.Size([2048, 50, 64])。之后将传入的数据放入GRU中提取信息,item_gru_output = self.item_gru_layers(item_seq_emb_dropout) 。item_gru_output为[2048, 50, 128]。
第二个GRU提取item内部之间属性的特征信息,而属性中含有序列信息的为class。也就是说,我们的第二个GRU是提取每个商品的class的序列信息。将torch.Size([2048, 50])输入放入self.feature_embed_layer(None, item_seq)函数中,提取出来class属性的序列信息,输出为torch.Size([2048, 50, 1, 64]),将数据传入feature_table.view(table_shape[:-2] + (feat_num * embedding_size,))函数得到feature_emb输出,格式为[2048, 50, 64]。之后将输出传入self.feature_gru_layers(feature_emb) 类型的GRU特征提取函数,提取特征内部关于class的序列特征向量,输出为feature_gru_output,输出的形状为[2048, 50, 128]。
然后按照输出将上面两个GRU的输出cat起来。torch.cat((item_gru_output, feature_gru_output), -1),output_concat的形状为[2048, 50, 256]。将输出output_concat接一个线性层input为256输出为64。经过线性输出的形状变为[2048, 50, 64]。输出GRU的最后一层作为整个批次的输出seq_output,格式为[2048, 64]。将seq_output[2048, 64]和all_item_emb[64,1683]相乘得出来logits为[2048, 1683]。即我们可以得到这一次数据中每一个输出的数字和1683商品中那个最相似。最后算损失logits[2048, 1683]和pos_items[2048]交叉熵相乘计算损失。loss = tensor(7.4245, grad_fn=)。
7:Bert
根据用户购买商品的记录文件,利用另外一个特征抽取工具Transformer中的Encoder方式,即我们所熟知的序列模型(Bert),该算法记录为Bert4Rec。
Encoding阶段:
 训练数据是item。sequence=50,也就是说我们每批次数据要选择下面形式的数据[2048,50]
训练数据是item。sequence=50,也就是说我们每批次数据要选择下面形式的数据[2048,50]
因为MASK率是20%,因此每批次数据遮蔽了下面形式的数据[2048,10]的数据,我们需要计算的就是[2048,10]数据所对应的损失,我们取出对应遮蔽模型数据计算损失。首先我我们将item 序列对传入reconstruct_train_data函数,获取重构后的数据,添加遮蔽模型后的masked_item_seq [2048, 50]。被遮蔽的模型的序列数据pos_items[2048, 10],以及被遮蔽的模型的序列在长度50的数组中的索引masked_index[2048, 10]。将遮蔽模型数据masked_item_seq [2048, 50]传入bert模型中输出为seq_output [2048, 50, 64]。将遮蔽索引masked_index[2048, 10]和遮蔽序列masked_item_seq [2048, 50]传入multi_hot_embed函数获取遮蔽模型的0,1索引pred_index_map[20480, 50],采用one-hot方式实现。在进行变换获取索引pred_index_map[2048, 10, 50]。将seq_output[2048, 50, 64]和pred_index_map[2048, 10, 50]相乘获得最后的seq_output[2048, 10, 64]输出。这个seq_output[2048, 10, 64]表示经过bert模型和遮蔽模型后的输出。
接下来就是损失的计算,损失计算还是采用交叉熵损失。获取item 的embedding test_item_emb[1683, 64]。将seq_output[2048, 10, 64]和经过变换后的embedding test_item_emb[64,1683]相乘torch.matmul。输出结果为logits[2048, 10, 1683] 。将logits经过变换[20480,1683],和pos_items经过变换[20480]传入交叉熵函数中计算损失,在计算完损失后反向传播。更新参数。
对于masked_item_seq [2048, 50]数据传入bert模型中的数据流通过程。获取数据的position_embedding[2048, 50, 64]。获取数据item_seq的item_emb[2048, 50, 64]。然后将position_embedding和item_emb相加这样我们便获取了嵌入位置信息的item_emb也就是input_emb。之后我们对input_emb取LayerNorm()。再去取dropout()获得最后input数据[2048, 50, 64]。之后我们根据item_seq获取padding成0的位置的数字制为-10000数组extended_attention_mask。之后将经过处理后的input_emb和extended_attention_mask传入trm_encoder()中。输出为每次层的output我们将每一层的输出append到list中,将最后的一个输出作为bert的输出。