Spring Cloud微服务实战之客户端负载均衡-Spring Cloud Ribbon
客户端负载均衡
RestTemplate详解
看一点源码
负载均衡的客户端接口:LoadBalancerClient
public interface LoadBalancerClient {
//根据传入的服务名serviceId,从负载均衡器中挑选一个对应服务的实例
ServiceInstance choose(String var1);
//使用从负载均衡器中挑选出的服务实例来执行请求内容
<T> T execute(String var1, LoadBalancerRequest<T> var2) throws IOException;
//构建合适的host:port形式的URI,参数1,是带有host与port的具体服务实例,参数2,是使用逻辑服务名
//定义为host的URI,返回的是,根据具体服务实例,拼接出的具体的host:post形式的请求地址
URI reconstructURI(ServiceInstance var1, URI var2);
}
客户端负载均衡器的自动化配置类:LoadBalancerAutoConfiguration
@Configuration
//需满足,RestTemplate类必须存在于当前工程环境中
@ConditionalOnClass({RestTemplate.class})
//需满足,在Spring的Bean工程中必须有LoadBalancerClient的实现Bean
@ConditionalOnBean({LoadBalancerClient.class})
public class LoadBalancerAutoConfiguration {
@LoadBalanced
@Autowired(
required = false
)
private List<RestTemplate> restTemplates = Collections.emptyList();
public LoadBalancerAutoConfiguration() {
}
//初始化器:维护被@LoadBalanced注解修饰的RestTemplate对象列表,初始化.
//用restTemplateCustomizer的实例来为每个RestTemplate,加拦截器
@Bean
public SmartInitializingSingleton loadBalancedRestTemplateInitializer(final List<RestTemplateCustomizer> customizers) {
return new SmartInitializingSingleton() {
public void afterSingletonsInstantiated() {
//...
}
};
}
//定制化器:为RestTemplate增加LoadBalancerInterceptor拦截器
@Bean
@ConditionalOnMissingBean
public RestTemplateCustomizer restTemplateCustomizer(final LoadBalancerInterceptor loadBalancerInterceptor) {
return new RestTemplateCustomizer() {
public void customize(RestTemplate restTemplate) {
List<ClientHttpRequestInterceptor> list = new ArrayList(restTemplate.getInterceptors());
list.add(loadBalancerInterceptor);
restTemplate.setInterceptors(list);
}
};
}
//拦截器,在客户端发起请求时,拦截,以实现客户端负载均衡,LoadBalancerInterceptor
//中有个intercept函数拦截请求
@Bean
public LoadBalancerInterceptor ribbonInterceptor(LoadBalancerClient loadBalancerClient) {
return new LoadBalancerInterceptor(loadBalancerClient);
}
}
负载均衡的实现:RibbonLoadBalancerClient
其中在execute函数中,通过getServer传入服务名,serviceId来获取具体的服务实例,可发现,并没有使用LoadBalancerClient中的choose接口,而是用的Netflix Ribbon 自身地 ILoadBanlencer接口中的chooseServer函数,
protected Server getServer(ILoadBalancer loadBalancer) {
return loadBalancer == null ? null : loadBalancer.chooseServer("default");
}
ILoadBanlencer:定义了一个客户端负载均衡器需要的一系列抽象操作(未列举过期函数):
addServers:向负载均衡器中维护的实例列表增加服务实例。
chooseServer:通过某种策略,从负载均衡器中挑选出一个具体的服务实例。
markServerDown:用来通知和标识负载均衡器中某个具体实例已经停止服务,防止之后被认为是正常服务的。
getReachableServers:获取当前正常服务的实例列表
getAllServers:获取所有已知的服务实例列表,包括正常服务与通知服务的实例
以上的server对象定义是一个传统的服务端节点,在该类中存储了服务端节点的一些元数据,包括host,port以及一些部署信息等。
所以,实际的负载均衡策略是在这ILoadBanlencer的实现类中产生的(懒得画了。。)
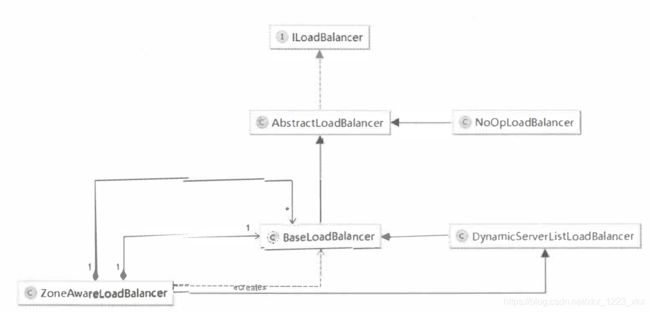
回头再看下,针对RibbonLoadBalancerClient,也有个自动化配置类–
RibbonClientConfiguration:
@Bean
@ConditionalOnMissingBean
public ILoadBalancer ribbonLoadBalancer(IClientConfig config, ServerList<Server> serverList, ServerListFilter<Server> serverListFilter, IRule rule, IPing ping) {
//默认是采用了ZoneAwareLoadBalancer实现负载均衡器
ZoneAwareLoadBalancer<Server> balancer = LoadBalancerBuilder.newBuilder().withClientConfig(config).withRule(rule).withPing(ping).withServerListFilter(serverListFilter).withDynamicServerList(serverList).buildDynamicServerListLoadBalancer();
return balancer;
}
继续看:RibbonLoadBalancerClient–execute,通过某种方式获取到server后,再包装成RibbonServer对象,实际上这就是ServiceInstance接口的实现,此对象中除Server对象外还有服务名,是否使用HTTPS标识以及一个Map类型的元数据集合。然后使用该对象回调LoadBalancerInterceptor请求拦截器中的LoadBalancerRequest的apply(ServiceInstance var1)函数,以此,向一个实际的具体服务实例发起请求。
public <T> T execute(String serviceId, LoadBalancerRequest<T> request) throws IOException {
ILoadBalancer loadBalancer = this.getLoadBalancer(serviceId);
Server server = this.getServer(loadBalancer);
if (server == null) {
throw new IllegalStateException("No instances available for " + serviceId);
} else {
RibbonLoadBalancerClient.RibbonServer ribbonServer = new RibbonLoadBalancerClient.RibbonServer(serviceId, server, this.isSecure(server, serviceId), this.serverIntrospector(serviceId).getMetadata(server));
RibbonLoadBalancerContext context = this.clientFactory.getLoadBalancerContext(serviceId);
RibbonStatsRecorder statsRecorder = new RibbonStatsRecorder(context, server);
try {
T returnVal = request.apply(ribbonServer);
statsRecorder.recordStats(returnVal);
return returnVal;
} catch (IOException var9) {
statsRecorder.recordStats(var9);
throw var9;
} catch (Exception var10) {
statsRecorder.recordStats(var10);
ReflectionUtils.rethrowRuntimeException(var10);
return null;
}
}
}
这里还有个问题:
apply函数在接受到具体的ServiceInstance实例后,是如何组织具体请求地址的呢?
负载均衡器:
由上结论之一,具体实现客户端负载均衡时,是通过Ribbon的ILoadBalancer接口实现的,因此,再来看看ILoadBalancer接口的实现类,是如何实现客户端负载均衡的。
AbstractLoadBalancer:ILoadBalancer接口的抽象实现
public abstract class AbstractLoadBalancer implements ILoadBalancer {
public AbstractLoadBalancer() {
}
public Server chooseServer() {
return this.chooseServer((Object)null);
}
//定义了根据分组类型来获取不同实例的列表
public abstract List<Server> getServerList(AbstractLoadBalancer.ServerGroup var1);
//LoadBalancerStats被用来存储负载均衡器中各个服务实例当前的属性和统计信息,
//可以利用这些信息来观察负载均衡器的运行情况,制定负载均衡策略
public abstract LoadBalancerStats getLoadBalancerStats();
//枚举类
public static enum ServerGroup {
ALL,//所有服务实例
STATUS_UP,//正常服务的实例
STATUS_NOT_UP;//停止服务的实例
private ServerGroup() {
}
}
}
BaseLoadBalancer:类,Ribbon负载均衡器的基础实现类,定义很多关于负载均衡器的基础内容。
@Monitor(
name = "LoadBalancer_AllServerList",
type = DataSourceType.INFORMATIONAL
)
//用于存储所有服务实例的清单
protected volatile List<Server> allServerList;
@Monitor(
name = "LoadBalancer_UpServerList",
type = DataSourceType.INFORMATIONAL
)
//勇士存储所有正常服务的清单
protected volatile List<Server> upServerList;
LoadBalancerStats:定义了用于存储负载均衡器各服务实例属性和统计信息的对象。
IPing:检查服务实例是否正常服务的对象,在BaseLoadBalancer中默认null,需要构造时注入具体实现。
IPingStrategy:检查服务实例操作的执行策略对象,使用静态内部类SerialPingStrategy实现,其默认是采用线性遍历ping服务实例的方式进行检查,有个问题,如果IPing的速度不理想,或者server列表很大,就会影响系统性能,这时候就要重写。
private static class SerialPingStrategy implements IPingStrategy {
private SerialPingStrategy() {
}
public boolean[] pingServers(IPing ping, Server[] servers) {
int numCandidates = servers.length;
boolean[] results = new boolean[numCandidates];
if (BaseLoadBalancer.logger.isDebugEnabled()) {
BaseLoadBalancer.logger.debug("LoadBalancer: PingTask executing [" + numCandidates + "] servers configured");
}
for(int i = 0; i < numCandidates; ++i) {
results[i] = false;
try {
if (ping != null) {
results[i] = ping.isAlive(servers[i]);
}
} catch (Throwable var7) {
BaseLoadBalancer.logger.error("Exception while pinging Server:" + servers[i], var7);
}
}
return results;
}
}
IRule:负载均衡的处理规则对象,负载均衡器实际将服务实例选择任务交给了IRule实例中的choose函数来实现。
默认初始化了RoundRobinRule为IRule 的实现对象,实现了基本且最常用的线性负载均衡规则。
private static final IRule DEFAULT_RULE = new RoundRobinRule();
//...
public Server chooseServer(Object key) {
if (this.counter == null) {
this.counter = this.createCounter();
}
this.counter.increment();
if (this.rule == null) {
return null;
} else {
try {
return this.rule.choose(key);
} catch (Throwable var3) {
return null;
}
}
}
pingIntervalSeconds:在BaseLoadBalancer构造函数中,直接 启动一个用户定时检查server是否健康的任务,默认初始化10s
this.pingIntervalSeconds = 10;
实现了ILoadBalance接口定义的负载均衡器应具备以下一系列基本操作:
a : addServers(List newServers): 向负载均衡器中增加新的服务实例列表,将实现将原本已经维护着的所有服务实例清单allServerList和新传入的服务实例清单newServers都加入到newList中,然后通过调用setServersList函数对newList进行处理,在BaseLoadBalancer中实现的时候会使用新的列表覆盖旧的列表。之后的几个拓展实现类,对于服务实例清单的优化都是通过对setServiceList函数的重写实现的。
b : chooseServer(Object key):IRule中讲过了。
c :markServerDown(Server server):标记某个服务实例暂停服务
d : getReachableServers() : 获取可用的服务实例列表,由于BaseLoadBalancer中有,所以直接返回即可。
e :getAllServers() : 获取所有的服务实例列表,由于BaseLoadBalancer中有,所以直接返回即可。
DynamicServerListLoadBalancer:类,继承于 BaseLoadBalancer类,是对基础负载均衡器的拓展。该均衡器中实现了服务实例清单在运行期的动态更新能力;同时,还具备了对服务实例清单的过滤功能,也就是说可以通过过滤器来选择性地获取一批服务实例清单。
ServerList:新增了此成员,一个具体的服务实例的拓展类(Server)【Ribbon与Eureka整合后,实现从Eureka server中获取服务实例清单】ServerList下的实现类具体实现的。
public interface ServerList<T extends Server> {
//获取初始化的服务实例清单
List<T> getInitialListOfServers();
//获取更新的服务实例清单
List<T> getUpdatedListOfServers();
}
既然是实现服务实例的动态更新,那就应该是Ribbon具备了访问Eureka来获取服务实例的能力。然后往下看看看,最终是依靠EurekaClient从服务注册中心中获取到具体的服务实例InstanceInfo列表,然后对这些服务进行遍历。最终实现,将服务实例从注册中心到本地的目的。
ServerListUpdater:服务更新器,【如何触发向Eureka server去获取服务实例清单以及如何在获取到服务实例清单后更新本地的服务实例清单】
public interface ServerListUpdater {
//启动服务更新器,传入的UpdateAction对象为更新操作的具体实现
void start(ServerListUpdater.UpdateAction var1);
//停止服务更新器
void stop();
//获取最近的更新时间戳
String getLastUpdate();
//获取上一次更新到现在的时间间隔,单位毫秒
long getDurationSinceLastUpdateMs();
//获取错过的更新周期数
int getNumberMissedCycles();
//获取核心线程数
int getCoreThreads();
public interface UpdateAction {
//对于ServerList的具体更新操作
void doUpdate();
}
}
对于ServerListUpdate的实现类:
PollingServerListUpdater:动态服务列表更新的默认策略,DynamicServerListLoadBalancer负载均衡器中的默认实现类就是这个,通过定时任务的方式进行服务列表的更新。
EurekaNotificationServerListUpdater:该更新器也可以服务于DynamicServerListLoadBalancer负载均衡器,但是它的触发机制与PollingServerListUpdate不同,它需要Eureka的事件监听器来驱动服务列表的更新操作。
重点看下:PollingServerListUpdate:
Start:以定时任务的方式进行服务列表的更新,创建Runnable的线程,调用updateAction.doUpdate(),然后启动定时任务。
另外两个关键参数:更新服务实例在初始化以后延迟1s后开始执行,并以30秒为周期重复执行。
private static long LISTOFSERVERS_CACHE_UPDATE_DELAY = 1000L;
private static int LISTOFSERVERS_CACHE_REPEAT_INTERVAL = 30000;
//初始化 1000毫秒
private final long initialDelayMs;
//更新 30*1000 毫秒
private final long refreshIntervalMs;
ServerListFilter:服务过滤器,主要用于对服务实例列表的过滤,通过传入的服务实例清单,根据一些规则返回过滤后的服务实例清单。
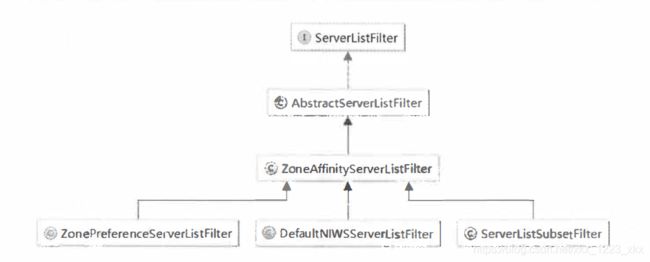
关键看下默认实现,其余的有机会再看。。
ZonePreferenceServerListFilter:
此过滤器是在Spring Cloud 整合时新增的过滤器。它实现了通过配置或者Eureka实例元数据的所属区域(Zone)来过滤出同区域的服务实例:首先通过父类ZoneAffinityServerListFilter的过滤器来获取,“区域感知”的服务实例列表,然后遍历这个结果,取出根据消费者配置预设的区域Zone来进行过滤,如果过滤的结果为空,就直接返回父类获取的结果,如果不为空就返回通过消费者配置的Zone过滤后的结果。
ZoneAwareLoadBalancer:是对 DynamicServerListLoadBalancer的拓展,在Dy…中,它并没有选择重写选择具体服务实例的chooseServer函数,所以它依然会采用BaseLoadBalancer中实现的算法,也就是RoundRobinRule规则,线性轮询访问服务实例,此算法中没有区域(Zone)的概念,因此所有的实例都在轮询之列,这样会产生周期性地跨区域访问的情况,产生更高的延迟,因为这些其他区域的服务实例节点主要是为了防止区域性故障,以实现整体高可用的,并不应该作为常规实例来访问,所以在多区域部署的情况下,会有一定的性能问题,而ZoneAwareLoadBalancer则可以避免这样的问题。
阅读源码,ZoneAwareLoadBalancer重写了,setServerListForZones函数,根据按区域Zone分组的实例列表,为负载均衡器中的LoadBalancerStats对象创建ZoneStats并放入Map zoneStatsMap集合中,每一个区域Zone对应一个ZoneStats,用于存储每个Zone的一些状态和统计信息。
就不贴代码了;个人理解:创建一个ConcurrentHashMap,用来存储每个Zone区域对应的负载均衡器,创建时同时创建规则,创建完成后,调用setServersList函数为其设置对应Zone区域的实例清单,之后再跑一遍遍历,对Zone区域的实例清单进行检查,没有就清理掉,防止因为过时的统计信息干扰算法。(setServerListForZones就是为之后的具体的选择算法 准备基础数据结构)。然后,当负载均衡器中维护中实例所属的Zone区域的个数大于1时,进入选择策略:
1、为当前负载均衡器中所有的Zone区域分别创建快照,保存下来,用于算法。
2、用快照数据实现可用区筛选,筛选的时候
a 剔除以下Zone区域:所属实例数为0;Zone区域内实例的平均负载小于0,或者实例故障率(断路器断开次数/实例数)大于等于阈值(默认0.99999)
b 根据每个Zone中的实例的平均负载 ,算出平均负载最高(最差)的Zone区域。
c 如果a中没有可剔除,并且b的最差的平均负载也小于阈值(20%),就直接返回所有Zone为可用区域。
否则,从平均负载的Zone区域集合中随机选择删除一个。
3、如果返回的可用区不为空,并且数量小于原Zone总量,就随机选择一个Zone区域
4、对于3中选择到的Zone区域,也就获得了该区域的负载均衡器。具体的选择哪个实例,还是使用IRule接口的choose函数选择,此处,IRule接口的实现会使用ZoneAvoidanceRule来选择具体server实例。
负载均衡策略
详细看下Ribbon中提供了哪些负载均衡的策略实现。
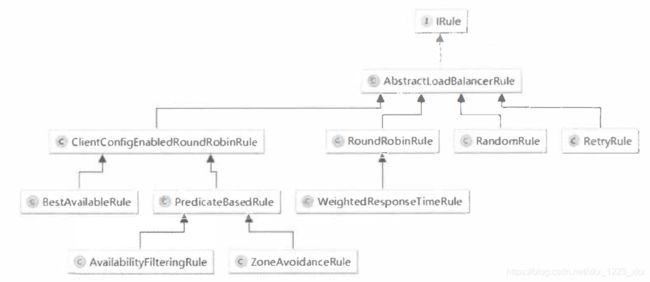
AbstractLoadBalancerRule:负载均衡策略抽象类,定义了负载均衡器ILoadBalancer对象,此对象能够再具体实现选择服务策略时,获取到一些负载均衡器中维护的信息来作为分配依据,并以此涉及一些算法来实现来针对特定场景的高效策略。
RandomRule:实现从服务实例清单中随机选择一个服务实例的功能。
RoundRobinRule:按照线性轮询的方式以此选择每个服务实例的功能。
RetryRule:实现具备充实机制的实例选择功能,内部是RoundRobinRule实例,反复尝试,如果得到了具体的服务实例则返回,否则,根据社会组的尝试结束时间为阈值(maxRteryMillis参数定义的值 + choose方法开始执行的时间戳),当超过该时间阈值就返回null。
WeightedResponseTimeRule:对RoundRobinRule的拓展,增加了根据实例的运行情况来计算权重,并根据权重来挑选实例,已达到最有的分配效果。三个核心内容:1、定时任务 2、权重计算 (可再展开研究)3、实例选择
ClientConfigEnabledRoundRobinRule:内部定义了RoundRobinRule策略,使用性线性轮询。虽然不会直接使用该策略,但是可以通过继承该策略,默认的choose作为备选,在高级策略中某情况无法实施就以父类的作为备选。
BestAvailableRule:继承自ClientConfigEnabledRoundRobinRule,以统计对象LoadBalancerStats为依据,可以选择出最空闲的实例,如果LoadBalancerStats为空,就默认了父类的线性轮询。
PredicateBasedRule:继承自ClientConfigEnabledRoundRobinRule,先过滤清单,再轮询选择。对于如何过滤,需要我们再AbstractServerPredicate的子类中实现apply方法来具体确定过滤策略。下面两个策略就是基于次抽象策略的实现,只是它们使用了不同的Predicate实现来完成过滤逻辑达到不同的实例选择效果。
AvailabilityFilteringRule:继承PredicateBasedRule,主要判断两项内容:1、是否故障 2、实例的并发请求数大于阈值(可配置),两者满足任一就会被过滤掉。策略:先以线性的方式选择一个实例,再用过滤条件判断,满足就使用,不满足就再获取一个。重复10次,没有找到就采用父类的实现方案。(线性抽样的方式直接尝试寻找可用且比较空闲的实例来使用),优化了父类每次都要遍历所有实例的开销。
ZoneAvoidanceRule:继承PredicateBasedRule,具体实现类。
public ZoneAvoidanceRule() {
//主过滤条件
ZoneAvoidancePredicate zonePredicate = new ZoneAvoidancePredicate(this);
//次过滤条件
AvailabilityPredicate availabilityPredicate = new AvailabilityPredicate(this);
this.compositePredicate = this.createCompositePredicate(zonePredicate, availabilityPredicate);
}
处理逻辑:
1、使用主过滤条件对所有实例过滤并返回过滤后的实例清单
2、以次使用次过滤条件列表中的过滤条件对主过滤条件的结果进行过滤
3、每次过滤之后(包括主过滤和次过滤),判断下面两个条件,只要有一个符合就不再进行过滤,将当前结果返回供线性轮询算法选择:
a 过滤后的实例总数 >= 最小过滤实例数(minimalFilteredServers,默认1)
b 过滤后的实例比例 > 最小过滤百分百 (minimalFilteredPercentage,默认0)
配置详解
自动化配置
在没有引入Spring Cloud Eureka等服务治理框架时,会自动有配置,也可以自行替换默认实现。只需在Spring Boot应用中创建对应的实现实例就能覆盖这些默认的配置实现。
Camden版本对RibbonClient配置的优化
在Camden版本中我们可以通过配置的方式,更加方便地为RibbonClient指定ILoadBalancer、IPing、IRule、ServerList和ServerListFilter的定制化实现
参数配置
全局配置:
ribbon.= 格式进行配置。做配置则覆盖默认值。
eg:ribbon.ConnectTimeout=250
指定客户端配置:.ribbon.= :其中client是客户端名称
与Eureka结合
当在Spring Cloud的应用中同时引入SpringCloud Ribbon 与 Eureka依赖,会触发Eureka中实现的对Ribbon的自动化配置,这是ServerList的维护机制发生覆盖,会将服务清单列表交给Eureka的服务治理机制来维护;IPing的实现也被覆盖,实例检查的任务交给了服务治理框架来进行维护。
配置也会更简单,不再需要hello-service.ribbon.listOfServers的参数来指定具体的服务实例清单,因为Eureka将会为我们维护所有服务的实例清单。对于Ribbon的配置依然可以按上面说到的全局配置与指定客户端配置进行,只是指定客户端时,可以直接使用Eureka中的服务名。
因为Ribbon默认实现了区域亲和策略,因为可以通过Eureka实例的元数据配置来实现区域化的实例配置方式。比如,将不同机房的实例配置成不同的区域值,以作为跨区域的容错机制实现。只需要在服务实例中增加Zone参数,指定自己所在区域即可。
eureka.instance.metadataMap.zone=hangzhou
也可以禁用Eureka对服务实例的维护,这样就回归到了Ribbon中来。
ribbon.eureka.enabled=false
重试机制
Spring Cloud Eureka 实现的服务治理机制更强调,CAP原理中的AP,即可用性与可靠性,ZooKeeper这类强调CP(一致性,可靠性)的服务治理框架的最大区别在于,Eureka为了实现更高的服务可用性,牺牲了一定的一致性,在极端的情况下,宁愿接受故障实例,也不丢掉“健康”实例。比如Eureka的保护机制,服务剔除延迟。因此,当服务调用到故障实例的时候,希望能够增强对这类问题的容错—>重试机制。
Brixt on版本中,需要自己拓展。从Camden SR2版本开始,Spring Cloud整合了Spring Retry来增强RestTemplate的充实能力,简单配置就可以自动根据配置实现重试策略。
#开启重试机制,默认关闭
spring.cloud.loadbalancer.retry.enabled=true
#断路器的超时时间需要大于Ribbon的超时时间,不然不会触发重试
hystrix.command.default.execution.isolation.thread.timeoutinMilliseconds=10000
#请求连接的超时时间
hello-service.ribbon.ConnectTimeout=250
#请求处理的超时时间
hello-service.ribbon.ReadTimeout= lOOO
#对所有操作请求都进行重试
hello-service.ribbon.OkToRetryOnAllOperations=true
#切换实例的重试次数
hello-service.ribbon.MaxAutoRetriesNextServer=2
#对当前实例的重试次数
hello-service.ribbon.MaxAutoRetries=l
如上配置,当访问到故障请求的时候,它会在尝试访问一次当前实例,(重复次数:MaxAutoRetries),如果不行就换一个访问,如果还是不行,就再换一个(更换次数:MaxAutoRetriesNextServer),如果还是不行,就返回失败信息。
客户端负载均衡与RestTemplate详解 ,下次单独看,感觉关联性没有那么强。