WeightedRandomSampler 理解了吧
WeightedRandomSampler
sampler = WeightedRandomSampler(samples_weight, samples_num)
train_loader = DataLoader( train_dataset, batch_size=bs, num_workers=1, sampler=sampler)
我的数据不平衡,使用pytorch,发现WeightedRandomSampler这个东西,网上找了一圈,有点会用了,就是上面这个用法,但是理解了很久才知道为什么这么用。
最大的问题就是不能理解WeightedRandomSampler是怎么运作的。除了官方解释,其他也没有找到更有用的信息了。
现在我觉得是有点理解了。
官方解释是:

还给了例子:
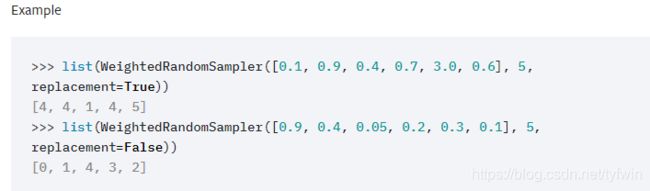
然后不是很懂,还是不知道怎么用。感觉这个例子却是不是很好说明问题,也是我理解能力太差,多试几次才懂了。
我换一个例子如下:
list(WeightedRandomSampler([1, 9], 5, replacement=True))
上面这句话反复运行,你猜怎么着?
我每次运行的结果如下:(你的结果肯定不一样)
[1, 0, 1, 1, 1]
[1, 1, 1, 1, 1]
[1, 1, 1, 0, 1]
[1, 1, 1, 1, 1]
[1, 1, 1, 1, 1]
[1, 1, 0, 1, 1]有点理解了吧?
这个5代表要生成5个数,这5个数是谁呢? 取决于前面【】内的数的数量,上面【】内有2个数,根据上面[0,..,len(weights)-1],即生成的数是0-1之间的任意数。
那这5个数到底是几,有10%的概率是0,有90%的概率是1。
理解了吧?其他参数不解释了。
使用
有一种通常的用法是:(不限于此)
假设分类问题,分为3类。
sampler = WeightedRandomSampler(samples_weight,samples_num)
samples_weight的数量等于我们训练集总样本的数量,假设为1000。
samples_weight的每一项代表该样本种类占总样本的比例的倒数。
samples_num 为我们想采集多少个样本,可以重复采集。假设为2000。
假设3类样本分布比例为 猫,狗,猪 = 0.1,0.2,0.7
Count = [0.1,0.2,0.7]
Weight = 1/Count = [10,5,1.43] 约等于[0.7,0.2,0.1]
samples_weight内全是 10或5或1.43,是10代表该样本是猫...
假设samples_weight内样子是:
[10,5,5,1.43,1.43,1.43,1.43.......,10]
10的数量最少,但是权重最大,所以达到了样本平衡的效果。
所以结合上面的WeightedRandomSampler的使用:
会生成样本总数个数即2000个数,
每个数可能是0-999之间的某个数,
每个数:(和samples_weight内数值对应)
是0的概率为 10/sum(samples_weight)
是1的概率为5/sum(samples_weight)
是2的概率为1.43/sum(samples_weight)
是3的概率为1.43/sum(samples_weight)
是4的概率为1.43/sum(samples_weight)
......
是999的概率为 10/sum(samples_weight)
把取出来的数字作为index,DataLoader就取用了。
end
目前的理解,难免有疏漏错误,还望大佬们多多指正。