AutoGluon-windows学习笔记(1)
提示:文章写完后,目录可以自动生成,如何生成可参考右边的帮助文档
文章目录
- 一、windows安装
- 二、表格预测
-
- 1.快速入门
-
- 导入表格预测库
- 导入数据(数据为.CSV,pd.DataFrame类型)
- 训练模型
- 测试模型
- 各个算法的测试精度
- .fit() 的preset参数:
- 2.深入了解
-
- 超参数
- staking/begging模型优化
- 模型预测
- 对预测结果评价
- 模型可解释性
- 模型加速
- 用约束提高模型速度
- 使用更小或者更快的模型训练
- 删除模型
- 模型蒸馏
- 预设和超参数
- 内存问题
- 硬盘空间不足问题
- 总结
提示:以下是本篇文章正文内容,下面案例可供参考
一、windows安装
AutoGluon官网
github
pip3 install autogluon
测试是否安装成功
from autogluon.tabular import TabularDataset, TabularPredictor
train_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv')
test_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv')
predictor = TabularPredictor(label='class').fit(train_data=train_data)
predictions = predictor.predict(test_data)
运行结束会出现跑的几个模型的参数,以及效果最好的模型
二、表格预测
1.快速入门
导入表格预测库
from autogluon.tabular import TabularDataset, TabularPredictor
导入数据(数据为.CSV,pd.DataFrame类型)
train_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/train.csv')
subsample_size = 500 # 样本大小
train_data = train_data.sample(n=subsample_size, random_state=0)
#pandas对表格的操作均适用
训练模型
save_path = 'agModels-predictClass' # specifies folder to store trained models
predictor = TabularPredictor(label=label, path=save_path).fit(train_data)
测试模型
test_data = TabularDataset('https://autogluon.s3.amazonaws.com/datasets/Inc/test.csv')
y_test = test_data[label] #正确的标签值
test_data_nolab = test_data.drop(columns=[label]) # 删除标签列,再用ML预测
predictor = TabularPredictor.load(save_path) # 加载之前训练好的模型
y_pred = predictor.predict(test_data_nolab)# 预测
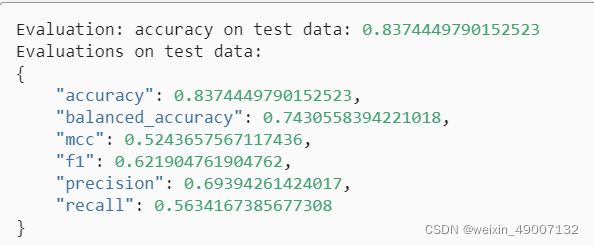
perf = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred, auxiliary_metrics=True)# 结果评估
直接输出6种评估指标,以及预测结果
各个算法的测试精度
predictor.leaderboard(test_data, silent=True)

返回各个类别预测概率
pred_probs = predictor.predict_proba(test_data_nolab)
返回拟合过程中的各个指标:时间、精度等
results = predictor.fit_summary(show_plot=True)
predictor.problem_type# 查看预测类型,即回归还是分类
predictor.feature_metadata# 数据标签列的数据类型
.fit() 的preset参数:
默认是medium_quality,可以按medium_quality good_quality high_quality best_quality的顺序测试,找到适合的模型。
presets=‘best_quality’:利用bagging/staking,准确度高但是运行时间长。
presets=‘medium_quality’:选择的算法运行时间较短,但准确率会差一点。
折中的办法就是:presets=[‘good_quality’, ‘optimize_for_deployment’]
time_limit = 60 # 设置模型最多等待时间60s
metric = 'roc_auc' # 评定指标
predictor = TabularPredictor(label, eval_metric=metric).fit(train_data, time_limit=time_limit, presets='best_quality')
predictor.leaderboard(test_data, silent=True)
TabularPredictor() : eval_metric可以指定评价指标例如:‘f1’ (for binary classification), ‘roc_auc’ (for binary classification), ‘log_loss’ (for classification), ‘mean_absolute_error’ (for regression), ‘median_absolute_error’ (for regression)
2.深入了解
超参数
import autogluon.core as ag#用来生成数组空间
nn_options = { # 神经网络超参数
'num_epochs': 10,
'learning_rate': ag.space.Real(1e-4, 1e-2, default=5e-4, log=True),
'activation': ag.space.Categorical('relu', 'softrelu', 'tanh'),
'dropout_prob': ag.space.Real(0.0, 0.5, default=0.1),
}
gbm_options = { # lightGBM超参数
'num_boost_round': 100, # number of boosting rounds (controls training time of GBM models)
'num_leaves': ag.space.Int(lower=26, upper=66, default=36), # number of leaves in trees (integer hyperparameter)
}
hyperparameters = { 'GBM': gbm_options,
'NN_TORCH': nn_options,
} # 生成字典
metric = 'accuracy'
time_limit = 2*60 # train various models for ~2 min
num_trials = 5 # try at most 5 different hyperparameter configurations for each type of model
search_strategy = 'auto' # to tune hyperparameters using random search routine with a local scheduler
hyperparameter_tune_kwargs = { # HPO is not performed unless hyperparameter_tune_kwargs is specified
'num_trials': num_trials,
'scheduler' : 'local',
'searcher': search_strategy,
}
predictor = TabularPredictor(label=label, eval_metric=metric).fit(
train_data, tuning_data=val_data, time_limit=time_limit,
hyperparameters=hyperparameters, hyperparameter_tune_kwargs=hyperparameter_tune_kwargs,
)
staking/begging模型优化
为了提高模型表现将num_bag_folds = 5到10, num_stack_levels = 1到3
predictor = TabularPredictor(label=label, eval_metric=metric).fit(train_data,
num_bag_folds=5, num_bag_sets=1, num_stack_levels=1,
hyperparameters = {'NN_TORCH': {'num_epochs': 2}, 'GBM': {'num_boost_round': 20}},
)
num_bag_folds控制k-fold,令auto_stack=True,autogluon可以自动选值。
tip:在 fit() 中指定 presets=‘best_quality’ 并且令 auto_stack=True
模型预测
predictor = TabularPredictor.load(save_path)#加载训练好的模型
predictor.features()#特征
#可以预测个体而不是一个dataset
datapoint = test_data_nolabel.iloc[[0]] # Note: .iloc[0] 不可以用,他输出的是pd.serier而不是pd.frame
predictor.predict(datapoint)#通过第1列预测
predictor.predict_proba(datapoint) # 输出预测类概率
predictor.get_model_best()#输出表现最好的模型
predictor.leaderboard(test_data, silent=True)#输出排行榜
predictor.leaderboard(extra_info=True, silent=True)#输出拓展的每个算法运行数据的排行榜
输出其他指标
predictor.leaderboard(test_data, extra_metrics=['accuracy', 'balanced_accuracy', 'log_loss'], silent=True)#指定产生的数据,其中log_loss如果是-inf,则可能是0类的预测概率(KNN),所以尽量不要把log_loss当作首要指标。
可选参数:[‘accuracy’, ‘acc’, ‘balanced_accuracy’, ‘mcc’, ‘roc_auc’, ‘roc_auc_ovo_macro’, ‘average_precision’, ‘log_loss’, ‘nll’, ‘pac_score’, ‘precision’, ‘precision_macro’, ‘precision_micro’, ‘precision_samples’, ‘precision_weighted’, ‘recall’, ‘recall_macro’, ‘recall_micro’, ‘recall_samples’, ‘recall_weighted’, ‘f1’, ‘f1_macro’, ‘f1_micro’, ‘f1_samples’, ‘f1_weighted’, ‘r2’, ‘mean_squared_error’, ‘mse’, ‘root_mean_squared_error’, ‘rmse’, ‘mean_absolute_error’, ‘mae’, ‘median_absolute_error’, ‘spearmanr’, ‘pearsonr’, ‘pinball_loss’, ‘pinball’, ‘soft_log_loss’]
'''指定模型使用'''
i = 0 # 模型索引
model_to_use = predictor.get_model_names()[i]
model_pred = predictor.predict(datapoint, model=model_to_use)
'''获取指定分类器参数'''
all_models = predictor.get_model_names()
model_to_use = all_models[i]
specific_model = predictor._trainer.load_model(model_to_use)
model_info = specific_model.get_info()
predictor_information = predictor.info()
对预测结果评价
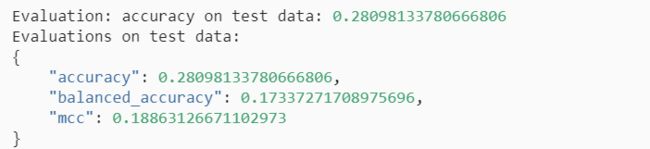
y_pred_proba = predictor.predict_proba(test_data_nolabel)
perf = predictor.evaluate_predictions(y_true=y_test, y_pred=y_pred_proba)
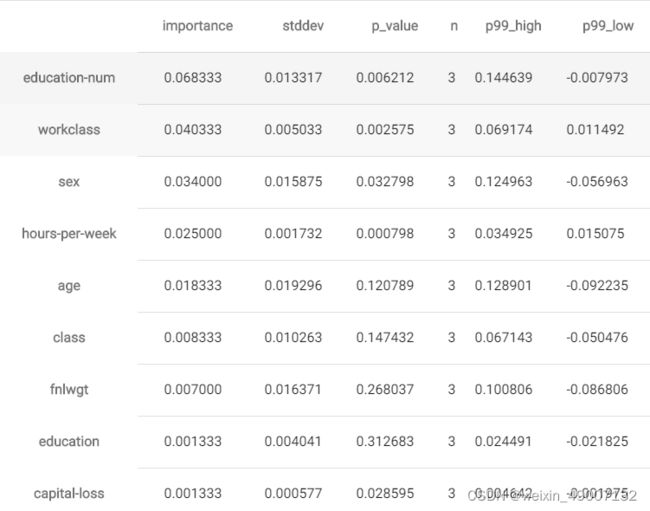
模型可解释性
predictor.feature_importance(test_data)#特征重要性
模型加速
AutoGluon一次只加载一个模型,这对begging/staking效果比较好,但是用时比较多。可以先将所有模型加载到内存中解决这个问题。
#启用模型
predictor.persist_models()
num_test = 20
preds = np.array(['']*num_test, dtype='object')
for i in range(num_test):
datapoint = test_data_nolabel.iloc[[i]]
pred_numpy = predictor.predict(datapoint, as_pandas=False)
preds[i] = pred_numpy[0]
perf = predictor.evaluate_predictions(y_test[:num_test], preds, auxiliary_metrics=True)
#释放内存
predictor.unpersist_models()
用约束提高模型速度
通过设置infer_limit 和 infer_limit_batch_size来分别限制预测一行所用时间和batchsize,如果你的数据量很大,infer_limit_batch_size选择10000。当infer_limit_batch_size=1时,infer_limit<0.02 很难满足。
predictor_infer_limit = TabularPredictor(label=label, eval_metric=metric).fit(
train_data=train_data,
time_limit=30,
infer_limit= 0.00005,
infer_limit_batch_size=10000,
)
predictor_infer_limit.refit_full()#使用begging模型时可以提高运算速度
#为了模型快速运行设置persist
predictor_infer_limit.persist_models()
使用更小或者更快的模型训练
predictor.fit_weighted_ensemble:结合先前训练模型的预测拟合新的加权集成模型。
additional_ensembles = predictor.fit_weighted_ensemble(expand_pareto_frontier=True)#expand_pareto_frontier=True时,将会依托帕累托边界,构建许多不同的加权集成。
print("Alternative ensembles you can use for prediction:", additional_ensembles)
#返回新训练的加权集成模型名称列表
![]()
删除模型
predictor.delete_models(models_to_delete=additional_ensembles, dry_run=False)
通过refit_full将几个begging模型融合成一个单个模型,可以减低内存使用和时间,但是准确率可能会下降。
refit_model_map = predictor.refit_full()
print("Name of each refit-full model corresponding to a previous bagged ensemble:")
print(refit_model_map)
其结果也添加到了leaderboard里面了,refit_full是使用所有数据进行训练的,所以他没有score_val。还可以使用non-begged模型调用 refit_full() 以将相同的模型重新训练(在这种情况下不会有内存/延迟增益,但测试准确性可能会提高)
模型蒸馏
单个模型的精度一般低于weighted/stacked/bagged集成,模型蒸馏提供了一种方法来保留单个模型的计算优势,同时享受集成带来的一些准确性提升。与 refit_full() 一样, distill() 函数将生成我们可以选择用于预测的其他模型。
student_models = predictor.distill(time_limit=30) # specify much longer time limit in real applications
preds_student = predictor.predict(test_data_nolabel, model=student_models[0])
print(f"predictions from {student_models[0]}:", list(preds_student)[:5])
预设和超参数
presets:
presets = ['good_quality', 'optimize_for_deployment']
predictor_light = TabularPredictor(label=label, eval_metric=metric).fit(train_data, presets=presets, time_limit=30)
要获得最准确的整体预测器(无论其效率如何),请设置 presets=‘best_quality’。要以最少的磁盘使用量获得良好的质量,请设置 presets=[‘good_quality’, ‘optimize_for_deployment’]。可用预设:[‘best_quality’, ‘high_quality’, ‘good_quality’, ‘medium_quality’, ‘optimize_for_deployment’, ‘ignore_text’] 建议在给定的 fit() 调用中仅使用一个基于质量的预设。
轻量级超参数:
predictor_light = TabularPredictor(label=label, eval_metric=metric).fit(train_data, hyperparameters='very_light', time_limit=30)
可以将hyperparameters设置为“light”、“very_light”或“toy”,以获得逐渐变小(精度会变低)的模型和预测器。
去掉一些比较笨重的模型。
excluded_model_types = ['KNN', 'NN_TORCH', 'custom']
predictor_light = TabularPredictor(label=label, eval_metric=metric).fit(train_data, excluded_model_types=excluded_model_types, time_limit=30)
内存问题
1.设置num_bag_sets = 1,也可以设置大点的值,但是精度会降低
2.excluded_model_types = [‘KNN’, ‘XT’ ,‘RF’]
3.在fit()中设置不同的presets,hyperparameters
4.如果尝试为大型测试数据集生成预测,请将测试数据分成更小的块
5.如果模型先前已保存在内存中,模型运行速度不是主要问题,请调用 predictor.unpersist_models()
6.如果模型先前已保存在内存中,在 fit() 中使用了 bagging,并且运行速度是一个问题:调用 predictor.refit_full() 并使用 refit-full 模型之一进行预测(确保这是唯一在内存中保存的模型)
硬盘空间不足问题
1.确保从以前的fit() 运行中删除所有 predictor.path 文件夹!如果您多次调用 fit(),这些可能会占用您的可用空间。 如果您没有指定路径,AutoGluon 仍会自动将其模型保存到名为“AutogluonModels/ag-[TIMESTAMP]”的文件夹中,其中 TIMESTAMP 记录了何时调用 fit(),因此请确保在运行时也删除这些文件夹。
2.调用 predictor.save_space() 删除 fit() 期间产生的辅助文件
3.如果这个模型只用来预测的话,使用predictor.delete_models(models_to_keep=‘best’, dry_run=False)删除非预测相关的文件。
4.在 fit() 中,可以将 ‘optimize_for_deployment’ 添加到预设列表中,这将在训练后自动调用前两个策略。
上述大多数减少内存使用的策略也会减少磁盘使用(但可能会损害准确性)。
总结
自己留着复习用的,有错误大家帮忙指正,谢谢啦!