生成对抗网络(GAN)的数学原理全解

©PaperWeekly 原创 · 作者|孙裕道
学校|北京邮电大学博士生
研究方向|GAN图像生成、情绪对抗样本生成

论文标题:
A Mathematical Introduction to Generative Adversarial Nets
论文链接:
https://arxiv.org/abs/2009.00169

引言
Goodfellow 大神的开创性工作 GAN 自 2014 年诞生以来,GAN 就受到了极大的关注,并且这种关注导致了 GANs 的新思想、新技术和新应用的爆炸式增长。
GAN 的原论文中的证明会有一些不严谨的地方,并且在算法中为了训练效率更高,也有很多简化,其实这也是这个领域的一个常见现象,在北大的深度学习的数学原理的暑期课上,老师就提到过深度学习中数学严谨证明占 6 成。
言外之意就是该领域的证明过程并没有纯数学的那么严谨,当从计算机科学工程师角度去推导证明的时候,往往会有跟实际相悖的前提假设,但是从该假设推导出来的结论却是与实验结果相符或者该结论会对解决实际问题中有一定的指导意义。
该作者是一个数学底蕴很强的 AI 研究者,该论文的目的是试图从数学的角度对 GANs 进行概述,是一篇不可多得好有关 GAN 数学原理的理论性文章,论文中涉及到大量的数学原理和很多让人眼花缭乱的数学符号,可以把它当成一个 GAN 的理论手册,对哪一块感兴趣就可以认真研读一番。

GAN背景介绍
荣获图灵奖品有深度学习三剑客之称的 Yann LeCun 称曾表示“GAN 的提出是最近 10 年在深度学习中最有趣的想法”。
下图表示这 2014 到 2018 年以来有关 GAN 的论文的每个月发表数量,可以看出在 2014 年提出后到 2016 年相关的论文是比较少的,但是从 2016 年,或者是 2017 年到今年这两年的时间,相关的论文是真的呈现井喷式增长。
GAN 的应用十分广泛,它的应用包括图像合成、图像编辑、风格迁移、图像超分辨率以及图像转换,数据增强等。

在这篇论文中,作者将尝试从一个更数学的角度为初学者介绍 GAN,要完全理解 GANs,还必须研究其算法和应用,但理解数学原理是理解 GANs 的关键的第一步,有了它,GANs 的其他变种将更容易掌握。
GAN 的目标是解决以下问题:假设有一组对象数据集,例如,一组猫的图像,或者手写的汉字,或者梵高的绘画等等,GAN 可以通过噪声生成相似的对象,原理是神经网络通过使用训练数据集对网络参数进行适当调整,并且深度神经网络可以用来近似任何函数。
对于 GAN 判别器函数 D 和生成函数 G 建模为神经网络,其中具体 GAN 的模型如下图所示,GAN 网络实际上包含了 2 个网络,一个是生成网络 G 用于生成假样本,另一个是判别网络 D 用于判别样本的真假,并且为了引入对抗损失,通过对抗训练的方式让生成器能够生成高质量的图片。

具体的,对抗学习可以通过判别函数 和生成函数 之间的目标函数的极大极小值来实现。生成器 G 将来自于 分布随机样本 转化为生成样本 。判别器 试图将它们与来自分布 的训练真实样本区分开来,而 G 试图使生成的样本在分布上与训练样本相似。

GAN的数学公式
GAN的对抗博弈可以通过判别函数 和生成函数 之间的目标函数的极大极小值来进行数学化的表示。生成器 将随机样本 分布 转化为生成样本 。判别器 试图将它们与来自分布 的训练样本区分开来,而 试图使生成的样本在分布上与训练样本相似。对抗的目标损失函数如下所示为:

其中公式中, 表示关于下标中指定分布的期望值。GAN 解决的极小极大值的描述如下所示:
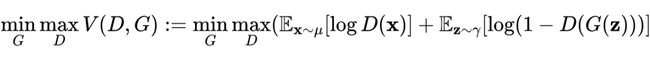
直观上,对于给定的生成器 , 优化判别器 以区分生成的样本 ,其原理是尝试将高值分配给来自分布 的真实样本,并将低值分配给生成的样本 。
相反,对于给定的鉴别器 , 优化 ,使得生成的样本 将试图“愚弄”判别器 以分配高值。设 ,其分布为 ,可以用 和 重写 为:
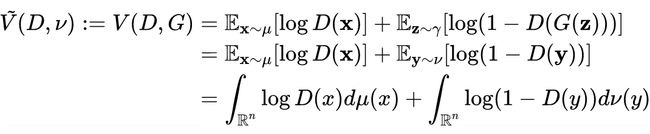
将上面的极大极小问题变为如下公式:
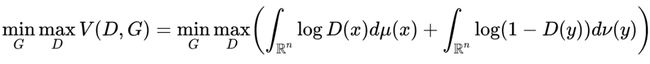
假设 具有密度 , 具有密度函数 (需要注意的是只有当 时才会发生)。综上所述最终可以写成:

可以观察到,在某些 的 的约束下,上述值与 等效。
论文中有大量公式和证明,会看的让人很头大,而且不同的命题和不同的定理交错出现,为了读者能够减少阅读障碍,我从中挑选了一些自认为比较重要的定理和命题,并且给它们重新进行了排序整理。
命题1:给定在 上的概率分布 和 ,其中它们的概率密度函数为 和 ,则有如下:

其中,, 的取值范围为 (sup表示上确界)。
定理1:设 是 上的概率密度函数。对于密度函数为 和 的概率分布 ,其极大极小值问题可以描述为:

对所有 ,可以解得 and 。
定理 1 说极大极小问题的解就是 Ian Goodfellow 在 2014 年那篇论文中推导出的 GAN 的优化解。
定理2:设 为 上给定的概率分布。对于概率分布 和函数 ,则有:

其中, and 对于 来说几乎处处存在。
命题2:如果在每个训练周期中,允许鉴别器 达到其最佳给定 ,然后更新 ,根据最小化准则有:

其中,分布 是收敛于分布 。
从纯数学的角度来看,这个命题 2 并不严谨。然而,它为解决 GAN 极小极大问题提供了一个实用的框架。
综上命题和定理可以将其归纳为如下的 GAN 算法框架,为了表达清晰,重新整理了一下该算法框架。


f-散度和f-GAN
4.1 f-散度
GAN 的核心本质是通过对抗训练将随机噪声的分布拉近到真实的数据分布,那么就需要一个度量概率分布的指标—散度。我们熟知的散度有 KL 散度公式如下(KL 散度有一个缺点就是距离不对称性,所以说它不是传统真正意义上的距离度量方法)。

和 JS 散度公式如下(JS 散度是改进了 KL 散度的距离不对称性):

但是其实能将所有我们熟知散度归结到一个大类那就是 f- 散度,具体的定义如下所示:
定义1:设 和 是 上的两个概率密度函数。则 和 的 f- 散度定义为:

其中,如果 时,会有 。
需要搞清楚一点事的 f- 散度依据所选函数不一样,距离的不对称也不一样。
命题3:设 是域 上的严格凸函数,使得 。假设 (相当于 )或 ,其中 。则有 , 当且仅当 。
4.2 凸函数和凸共轭
凸函数 的凸共轭也被称为 的 Fenchel 变换或 Fenchel-Legendre 变换,它是著名的 Legendre 变换的推广。设 是定义在区间 上的凸函数,则其凸共轭 定义为:

引理1:假设 是严格凸的,且在其域 上连续可微,其中 与 。则有:

命题4:设 是 上的凸函数,其值域在 内。那么 是凸的并且是下半连续的。此外,如果 是下半连续的,则满足 Fenchel 对偶 。
下表列出了一些常见凸函数的凸对偶,如下表所示:

4.3 用凸对偶估计f-散度
为了估计样本的 f- 散度可以使用 f 的凸对偶,具体的推导公式如下所示:
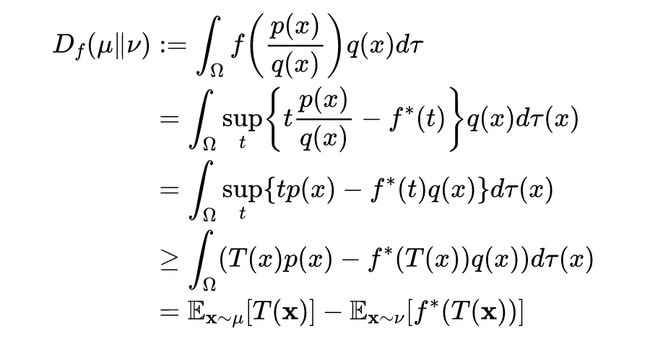
其中 是任何 Borel 函数,这样就得到了所有的 Borel 函数如下所示:

命题5:设 是严格凸的且在 上连续可微的,设 , 是 上的 Borel 概率测度,使得 ,则有:

其中 是一个优化器。
定理3:设 是凸的,使得 的域对某些 包含 ,设 是 上的 Borel 概率测度,则有:

其中对于所有的 Borel 函数有 。
定理4:设 是下半连续凸函数,使得 的域 具有 。设 为 上的 Borel 概率测度,使得 ,其中 和 。那么:

其中对于所有的 Borel 函数有 。
4.4 f-GAN和VDM
用 f- 散度来表示 GAN 的推广。对于给定的概率分布 ,f-GAN 的目标是最小化相对于概率分布 的 f- 散度 。在样本空间中,f-GAN 解决了下面的极大极小问题:

可以将如上的优化问题称为变分散度最小化(VDM)。注意 VDM 看起来类似于 GAN 中的极大极小值问题,其中 Borel 函数 被称为评判函数。
定理5:设 是一个下半连续严格凸函数,使得 的域 。进一步假定 在其域上是连续可微的,且 并且 。设 上的 Borel 概率测度,则 有如下公式:
其中对于所有的 Borel 函数有 。
综上所述,下面为 f-GAN 的算法流程框架。

4.4.1 Example1:
当函数 ,这里的f-散度就是为我们熟知的 KL 散度。则它的共轭函数为 ,其中 ,其相应的目标函数为:
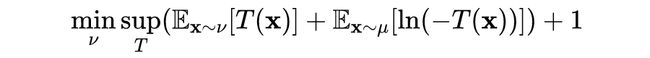
其中 ,忽略掉常数 +1 的常数项,并且 ,然后会有我们最原始的那种 GAN 的形式:

4.4.2 Example2:
这就是詹森-香农散度,该函数的共轭函数为 ,域 。相应的 f-GAN 的目标函数为:

其中 , , ,所以进一步可以化简为:

其中在这个公式中忽略掉常数项 。
4.4.3 Example3: ,
该函数的共轭函数为 ,域 。当 不是严格凸的连续可微时,相应的 f-GAN 目标函数如下所示:
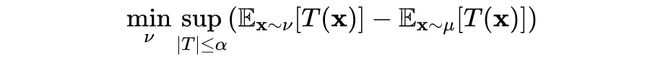
上面这个目标函数的形式就是 Wasserstein GAN 的目标函数。
4.4.4 Example4:
已知 ,所以该函数为严格凸函数。相应的 f-GAN 的目标函数为:

对上公式进一步求解可得:

其中里面有原始 GAN 论文中使用的“logD”技巧,用于 GAN 解决梯度饱和问题。

GAN的具体实例
对于 GAN 的应用实例,我没有按照论文中给出的实例进行介绍,我介绍了在自己的感官上觉得不错的 GAN。
5.1 WGAN
训练一个 GAN 可能很困难,它经常会遇到各种问题,其中最主要的问题有以下三点:
消失梯度:这种情况经常发生,特别是当判别器太好时,这会阻碍生辰器的改进。使用最佳的判别器时,由于梯度的消失,训练可能失败,因此无法提供足够的信息给生成器改进。
模式塌缩:这是指生成器开始反复产生相同的输出(或一小组输出)的现象。如果判别器陷入局部最小值,那么下一个生成器迭代就很容易找到判别器最合理的输出。判别器永远无法学会走出陷阱。
收敛失败:由于许多因素(已知和未知),GANs 经常无法收敛。
WGAN 做了一个简单的修改,用 Wasserstein 距离(也称为推土机(EM)距离)代替 GAN 中的 Jensen-Shannon 散度损失函数。不要忽视这一修改的意义:这是自 GAN 诞生以来本课题最重要的进展之一,因为 EM 距离的使用有效地解决了基于散度的 GAN 的一些突出缺点,从而可以减轻 GANs 训练中常见的故障模式。
5.2 DCGAN
DCGAN 是将卷积引入到 GAN 的训练过程中,使得参数量和训练效果更好,它实际训练 GANs 中提供了很多的指导方向,具体有如下五点:
用跨步卷积替换生成器和判别器中的任何池化层。
在生成器和鉴别器中使用批处理规范化。
移除完全连接的隐藏层以获得更深层的架构。
除了使用 Tanh 的输出之外,在生成器中对所有层使用 ReLU 激活,。
在所有层的判别器中使用 LeakyReLU 激活。
需要注意的是判别器是从高维向量到低维向量是卷积过程,如下图所示:

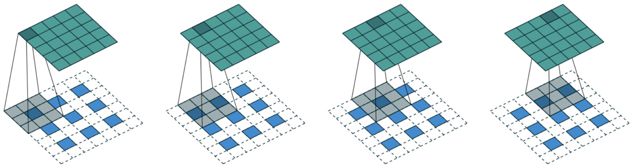
生成器是低维向量到高维向量是一个反卷积过程,反卷积又名转置卷积和微步卷积,卷积和反卷积两者的区别在于 padding 的方式不同,看看下面这张图片就可以明白了:
DCGAN 还有一个重要的创新之处在于将矢量加法引入到图像生成中,如下图所示:

5.3 StyleGAN
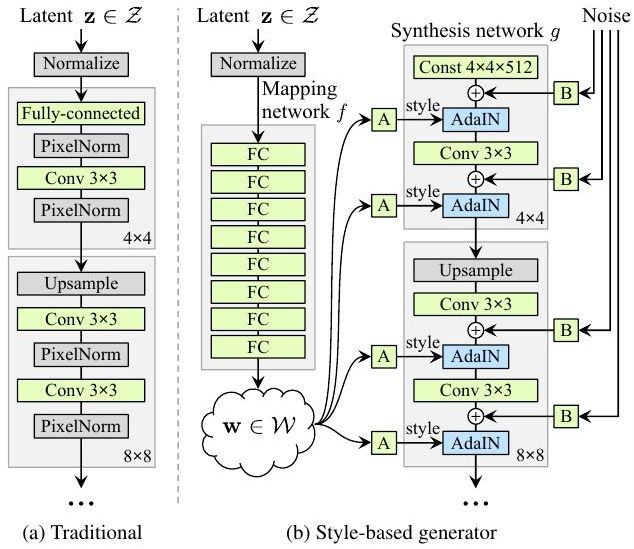
StyleGAN 提出了一个新的生成器框架,号称能够控制所生成图像的高层级属性,如发型、雀斑等;并且生成的图像在一些评价标准上得分更好,作为无监督学习的一种 GAN,它能够从噪声生成高分辨率的高清图像。具体的算法框架原理图如下所示:
StyleGAN 中生成的图像之清晰,细节之丰富由下图可见一斑,当然训练的成本也是很高的。

5.4 zi2zi
zi2zi 是我最喜欢的 GAN 的一种应用,它是利用 GAN 来对字体风格进行转换,以前的工作是处理类似的中文字体转化问题,结果不是很理想,纠其原因有生成的图片通常很模糊,对更多的有风格的字体处理时效果不好,每次只能有限地学习和输出一种目标字体风格,GAN 能很好的解决以上问题,其模型框架如下图所示:

中文字符,不论简体还是繁体,或者日本文,都用相同的原理构建并有着一系列相同的根基,其中具体的实现结果如下图所示:

更多阅读




#投 稿 通 道#
让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
???? 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
???? 投稿邮箱:
• 投稿邮箱:[email protected]
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
????
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

