Mask R-CNN论文解析
一、论文相关信息
1.论文题目:Mask-RCNN
2.发表时间:2017
3.文献地址:https://arxiv.org/abs/1703.06870
4.论文源码: https://github.com/facebookresearch/Detectron.
二、论文背景与简介
视觉社区在短时间内已经在目标检测和语义分割上取得了迅速的提高,这些提高很大部分是基于一些强大的框架,例如目标检测的Fast、Faster R-CNN和实力分割的FCN,这些框架具有直观的概念、灵活与鲁棒性,并且训练与测试迅速。本篇论文的目标就是设计一个用于实例分割的类似框架。
实力分割是非常困难的,因为它不止需要正确的检测一张图片中的所有物体,还要精准的分割每个实例,因此它结合了目标检测和语义分割这两个经典的计算机视觉任务。
目标检测(Object detection)要求分类并用一个边界框定位每个物体。
语义分割(semantic segmentation)要求将每个像素点都划分到一个对应的种类中而不需要区分具体的物体实例。
根据通用的术语,我们使用Object detection 来指代通过边框盒子(bounding box)方式实现的检测,而不是掩膜(mask)方式;并且使用semantic segmentation 来指代不区分实例的像素级分类。
这样的任务似乎需要一个极为复杂的方法来完成,但是通过本文提出的一个新的模型,可以简单、灵活、快速地完成。我们叫这个模型Mask R-CNN。Mask R-CNN在Faster R-CNN基础上增加了一个用于预测每个RoI分割掩膜的分支,该分支与用于分类和边框回归的分支平行,是一个小型FCN并应用到每个RoI上,实现像素点到点的分割蒙版预测。
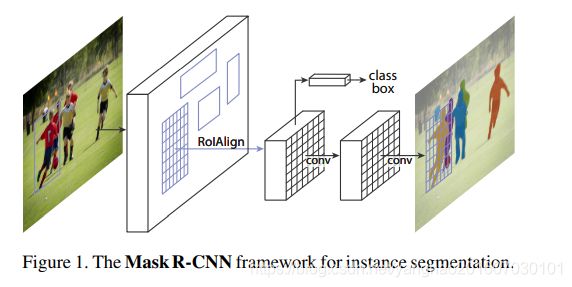
Faser R-CNN的RoIPool层是通过粗空间量化的方式实现特征提取,因此没有做到输入输出点到点的对准,为了弥补这点,我们设计了一个简单的、无量化的层来保留精确的空间位置信息——RoIAlign layer。RoIAlign layer 具有重要的作用,它能大幅提高掩膜准确率(mask accuracy)并且实现分割和分类的解耦(decouple mask and class prediction)。与FCN相比,他是为每个类提供一个独立的binary mask,并且类间没有比较,通过RoI分支实现类别预测。FCN则通常在每个像素上做多类别分类,分割与分类一起进行,实验证明这种方式实力分割的效果不好。在COCO实例分割任务(COCO instance segmentation task)的表现上,Mask R-CNN超过所有之前最先进(state-of -the-art)单模型,并且在COCO目标检测任务上也表现出色。该模型在GPU上能够实现200ms/frame,即5fps,在一个单独的8—GPU机器上训练需要一到两天(COCO),因此模型不仅训练快速,还有很高的精确性与灵活性,将该框架应用到人类姿势预测上的表现优于2016年的COCO keypoint competition,同时速度达到5fps,这也体现了该框架的通用性,Mask R-CNN可以被看做一个实例层次的灵活的框架,容易扩展到更复杂的任务。
三、相关知识
stage:不改变feature map大小的层可以归为一个stage。
RoI指的是候选框再特征图上的映射即特征图上的框。Fast RCNN中指的是通过Selective Search得到的候选框(Region Proposals)在特征图上的映射。在Faster R-CNN中指的是通过RPN产生的候选框在特征图上的映射。
RoIPooling:对不同大小的RoI中的feature做采样,得到一个固定大小(m*n)的特征图 。具体操作是把RoI划分为m×n个bin,然后每个bin里面分别做pooling得到一个value,最后得到固定的m×n大小的特征图。这样的过程中存在两个量化(quantization)的过程。
第一次是对候选框映射在特征图上的RoI的边界框做量化,将边界值可能出现的浮点数变为整数值。
第二次是上一步得到的RoI边界区域分割为m×n个bin时,对每个bin的边界做量化,取整数。
经过以上两次量化,最终提取出来的特征与原候选框位置上已经有了很大的偏差。由于从原图到feature map经过多次卷积,相当于stride=32(VGG),即特征图上的RoI的每个单位映射回原图是32个单位,所以最后的一点点偏差映射回原图也是非常大的偏差。这样的位置偏差在分类中能够接受,但是在需要精确到像素的的实例分割中却会造成很大的影响。
RoIAlign:为了克服RoIPooling的上述缺点,作者提出一个RoIAlign layer来取代RoIPooling中的量化操作,转而使用双线性内插来获得某点的值,从而将原来离散的采样变为了连续的采样操作。其步骤如下:
遍历每个RoI,而不对其边界做量化
将RoI分割为m×n个bin,每个bin的边界也不做量化。在每个bin中通过双线性内插计算k(作者使用的4)个采样点的值,然后再这k个采样点中做pooling操作得到该bin的值,最后得到固定大小的m×n大小的特征图。
RoIAlign 取样点数量没有RoIPooling多,却有更好的性能,这要归功于他解决了misalignment问题。实验时RoIAlign再VOC2007上的提升效果不如COCO大,分析后得知是因为COCO小目标更多,小目标受misalignment影响更大,因为同样大小的偏差,会对小目标起更大影响。
每个bin中的采样点若为k个,则将bin分为k份,每份取起中心点位置,该位置的像素采用双线性内插计算,得到k个采样点值。
image-centric training:以图象为中心,每次从N张图片中每张采样R/N个RoI,总共R个RoI作为输入来训练,能够共享计算,也减少存储。
RoI-centric training:每个batch的RoI来自从许多图片中采样得到的RoI,即先采样每张图片RoI,再从RoI中选择R个作为输入,开销大。
Feature Pyramid Network(FPN):FPN使用具有横向连接的自上而下的体系结构,可以根据单尺度的输入图像构建网络内特征金字塔。其结构如下图(这部分FPN介绍和图片来自博客),顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。
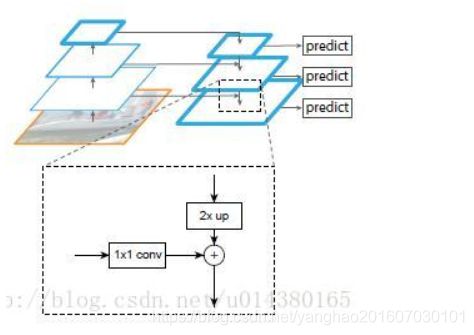
一个自底向上的线路,一个自顶向下的线路,横向连接(lateral connection)。图中放大的区域就是横向连接,这里1*1的卷积核的主要作用是减少卷积核的个数,也就是减少了feature map的个数,并不改变feature map的尺寸大小。
自底向上其实就是网络的前向过程。在前向过程中,feature map的大小在经过某些层后会改变,而在经过其他一些层的时候不会改变,作者将不改变feature map大小的层归为一个stage,因此每次抽取的特征都是每个stage的最后一个层输出,这样就能构成特征金字塔。
自顶向下的过程采用上采样(upsampling)进行,而横向连接则是将上采样的结果和自底向上生成的相同大小的feature map进行融合(merge)。在融合之后还会再采用3*3的卷积核对每个融合结果进行卷积,目的是消除上采样的混叠效应(aliasing effect)。并假设生成的feature map结果是P2,P3,P4,P5,和原来自底向上的卷积结果C2,C3,C4,C5一一对应。
原来多数的object detection算法都是只采用顶层特征做预测,但我们知道低层的特征语义信息比较少,但是目标位置准确;高层的特征语义信息比较丰富,但是目标位置比较粗略。另外虽然也有些算法采用多尺度特征融合的方式,但是一般是采用融合后的特征做预测,而本FPN不一样的地方在于预测是在不同特征层独立进行的。
FPN算法详细讲解
论文链接:https://arxiv.org/abs/1612.03144
四、网络训练
网络架构:
为了清楚起见,将网络分为两大部分:backbone和network head
backbone :用于从整张照片提取特征的卷积层结构,也即原Faster R-CNN里RPN和Fast RCNN共享那部分卷积层。
network head:分别应用于每个RoI的边界框识别(分类和回归)和掩码预测的网络头。
backbone部分:可以使用ResNets-50-C4或FPN。
使用ResNets-50-C4作为backbone提取特征时使用的时ResNets-50第4个stage的最后一个卷积层提取的特征。
以FPN为backbone的Faster-R-CNN可根据RoI的尺寸从不同层级的特征金字塔中提取RoI特征,但其他方法与普通ResNet类似。
network head部分:在Faster-RCNN的基础上加一个用于mask预测的全卷积分支(fully convolutional mask prediction branch)
两种backbone结合network head组成的两种架构见下图:
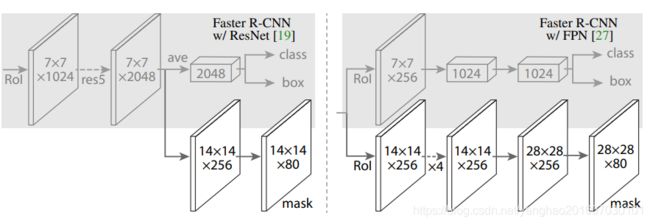
左图展示的是加上第5个stage后的ResNets-50-C4(C4) backbone加上Faster R-CNN head;右图是FPN的backbone,FPN可视为在ResNets的基础上加了入了各层特征图的融合,也包含resnet 的第5个stage,然后就是用了一个more efficient head that uses fewer filters。
损失函数
使用一个应用在每个RoI上的多任务损失:L = Lcls + Lbox + Lmask,Lcls , Lbox 和Faster R-CNN一样,增加了的Lmask对应增加的mask分支.
mask预测网络的输出结果是K×m×m维向量,其中K为类别数量,m*m是mask的最终输出长宽。计算每个像素的sigmoid结果,最终Mask 损失就是二维交叉熵损失的平均值(average binary cross-entropy loss)。对于一个与k类别的groundtruth关联的RoI,Lmask只考虑第k个mask。(还没搞清楚)
参数细节:
- 每个GPU同时训练两张图片(作者用了8GPU,所以batch size是16),输入图片尺寸为800*800。
- 训练时,每张图片的RoI数量为64/512(根据基础网络不同而改变);测试时每张图片RoI数量为300/1000。
- 正反例比例为1:3。
- anchors使用 5 scales 和 3 aspect ratios。
- weight decay为0.0001。
- 学习率:0.02,到120k iteration后为除以10。
五、inference阶段
测试时,对于输入的图片,经过backbone architecture提取特征图,然后使用RPN产生特定数量的proposal(C4作backbone则每张图片产生300proposal,FPN方式则产生1000个proposal/图片),之后经过RoIAlign在每个proposal映射到feature map上提取出固定大小的特征图,将这个特征图传入Faster R-CNN的bounding recognition中,包含(classification和bounding box regression),然后将mask branch应用到得分最高的100个边框区域,对于每个RoI,mask branch可以预测K种mask,但是我们只使用第k个mask(对应分类分支得到的那一类)。
六、实验结果
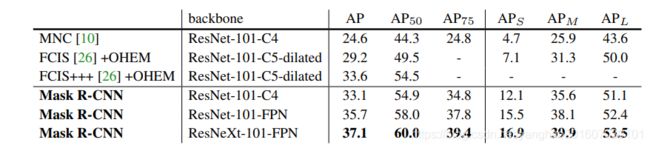
compare Mask R-CNN to the state-of-the-art methods in instance segmentation , All instantiations of our model outperform baseline variants of previous state-of-the-art models.
七、论文优缺点
优点:将RoIPooling用RoIAlign替代,解决了misalignment的问题,采用了FPN做特征提取,在Faster R-CNN上加了一个mask分支。
state-of-the-art models.
七、论文优缺点
优点:将RoIPooling用RoIAlign替代,解决了misalignment的问题,采用了FPN做特征提取,在Faster R-CNN上加了一个mask分支。