python量化——利用python构建Fama-French三因子模型
工具介绍
在构建模型之前,首先介绍所需的工具。
import pandas as pd
import tushare as ts
pro = ts.pro_api()
import statsmodels.api as sm
这里需要用到的是python中的pandas和statsmodels模块,分别用于数据处理和做多元回归。
另外,还需要获取股票和指数的各项数据,这里所用到的是tushare,tushare拥有丰富的数据内容,如股票、基金等行情数据,公司财务理等基本面数据。通过tushare平台赚取一定的积分可以免费获取平台提供的数据。(个人ID:419382)
Fama-French理论介绍
Fama-French是从1993年提出来的模型,该模型建立了三个因子来解释股票的回报率。这三个因子分别是:市场组合(Rm-Rf),市值因子(SMB)以及账面市值比因子(HML)。
具体公式如下:
E(Rit) −Rft= βi[E(Rmt−Rft)] +siE(SMBt) +hiE(HMLt)
其中SMB的计算公式为:
(SL+SM+SH)/ 3 - (BL+BM+BH)/ 3
HML的计算公式为:
(SH+BH)/ 2 - (SL+BL)/ 2
利用python构建模型
获取进行选股的指数
这里使用上证50作为选择股票的指数。
#获取进行选股的股票池
#获取进行选股的股票池
def get_SZ50_stocks(start,end):
#获取上证50成分股
df1 = pro.index_weight(index_code="000016.SH",start_date=start,end_date=end)
SZ50_codes = df1["con_code"].tolist()
#剔除最近一年上市和st股票
df2 = pro.stock_basic(exchange="",list_status="L")
df2 = df2[df2["list_date"].apply(int).values<20200101]
df2 = df2[-df2["name"].apply(lambda x:x.startswith("*ST"))]
all_codes = df2["ts_code"].tolist()
stocks_codes = []
for i in SZ50_codes:
if i in all_codes:
stocks_codes.append(i)
return stocks_codes
将股票进行分组
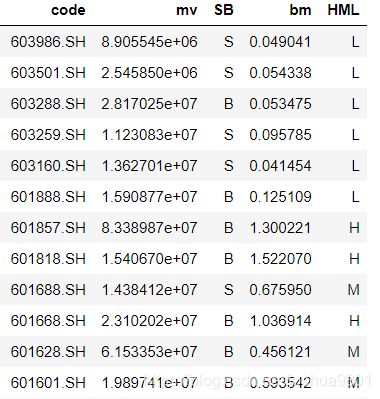
从上证50中选择出来的股票需要按照市值和账面市值比(PB ratio 的倒数)进行分组,其中市值划分为2组,账面市值比划分为3组,所以一共由2*3=6组。在进行市值和账面市值比划分时,需要选定一个基准日期。在构建模型时,这里使用了2020-03-10作为基准日期。
#将股票分为六个组
def group_stocks(stocks,date):
#划分大小市值
list_mv = []
df_stocks = pd.DataFrame()
count = 0
for i in stocks:
count += 1
a = pro.daily_basic(ts_code=i,trade_date=date)
a = a["circ_mv"].values
list_mv.append(float(a))
print("第%d支股票市值计算完成"%count)
df_stocks["code"] = stocks_codes
df_stocks["mv"] = list_mv
df_stocks["SB"] = df_stocks["mv"].map(lambda x:"B" if x>df_stocks["mv"].median() else "S")
#划分高中低账面市值比
list_bm = []
count = 0
for i in stocks_codes:
count += 1
b = pro.daily_basic(ts_code=i,trade_date=date)
b = 1/b["pb"].values
list_bm.append(float(b))
print("第%d支股票账面市值比计算完成"%count)
df_stocks["bm"] = list_bm
df_stocks["HML"] = df_stocks["bm"].apply(lambda x:"H" if x>=df_stocks["bm"].quantile(0.7)
else ("L" if x<=df_stocks["bm"].quantile(0.3) else "M"))
return df_stocks
分组之后的结果如图:
计算SMB和HML
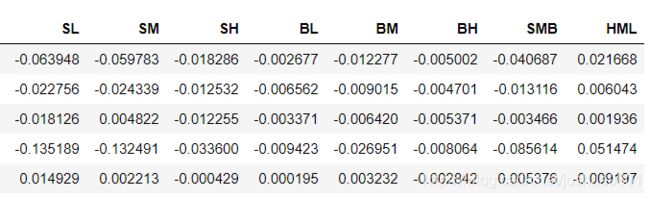
这里先算出六组股票的收益率,由基准日期往后一天计算一年内的日收益率。之后利用公式算出每日的SMB和HML。
#分别计算六个组的日收益率
def groups_return(stocks,start,end):
SL = stocks[stocks["SB"].isin(["S"])&stocks["HML"].isin(["L"])].code.tolist()
sum_SL = df_stocks[df_stocks["SB"].isin(["S"])&df_stocks["HML"].isin(["L"])]["mv"].sum()
SM = stocks[stocks["SB"].isin(["S"])&stocks["HML"].isin(["M"])].code.tolist()
sum_SM = df_stocks[df_stocks["SB"].isin(["S"])&df_stocks["HML"].isin(["M"])]["mv"].sum()
SH = stocks[stocks["SB"].isin(["S"])&stocks["HML"].isin(["H"])].code.tolist()
sum_SH = df_stocks[df_stocks["SB"].isin(["S"])&df_stocks["HML"].isin(["H"])]["mv"].sum()
BL = stocks[stocks["SB"].isin(["B"])&stocks["HML"].isin(["L"])].code.tolist()
sum_BL = df_stocks[df_stocks["SB"].isin(["B"])&df_stocks["HML"].isin(["L"])]["mv"].sum()
BM = stocks[stocks["SB"].isin(["B"])&stocks["HML"].isin(["M"])].code.tolist()
sum_BM = df_stocks[df_stocks["SB"].isin(["B"])&df_stocks["HML"].isin(["M"])]["mv"].sum()
BH = stocks[stocks["SB"].isin(["B"])&stocks["HML"].isin(["H"])].code.tolist()
sum_BH = df_stocks[df_stocks["SB"].isin(["B"])&df_stocks["HML"].isin(["H"])]["mv"].sum()
groups = [SL,SM,SH,BL,BM,BH]
sums = [sum_SL,sum_SM,sum_SH,sum_BL,sum_BM,sum_BH]
groups_names = ["SL","SM","SH","BL","BM","BH"]
df_groups = pd.DataFrame(columns=groups_names)
count=0
for group in groups:
df1 = pd.DataFrame()
for i in range(len(group)):
data = pro.daily(ts_code=group[i],start_date=start,end_date=end)
data.sort_values(by="trade_date",inplace=True)
data = data["pct_chg"]*df_stocks["mv"][i]
df1[group[i]] = data
df_groups[groups_names[count]] = df1.apply(lambda x:x.sum()/sums[count],axis=1)/100
print("%s组计算完成"%groups_names[count])
count += 1
return df_groups
#计算每日SMB,HML
def SMB_HML(data):
data["SMB"] = (data["SL"]+data["SM"]+data["SH"])/3-(data["BL"]+data["BM"]+data["BH"])/3
data["HML"] = (data["SH"]+data["BH"])/2-(data["SL"]+data["BL"])/2
return data
两个因子的计算结果如图:
加入市场组合收益和股票收益
#加入市场因子和股票收益率
def selection(data,start,end,stocks_codes):
MKT = pro.index_daily(ts_code="000016.SH",start_date=start,end_date=end)
MKT.sort_values(by="trade_date",ascending=True,inplace=True)
MKT = (MKT["pct_chg"]/100-0.035).tolist()
data["MKT"] = MKT
data.drop(data.columns[0:6],axis=1,inplace=True)
for i in range(len(stocks_codes)):
a = pro.daily(ts_code=stocks_codes[i],start_date=20200311,end_date=20210311)
if len(a) == 244:
a.sort_values(by="trade_date",ascending=True,inplace=True)
a = (a["pct_chg"]/100-0.035).tolist()
data["%s"%stocks_codes[i]] = a
return data
将如图表格用于多元回归:

对每支股票收益率和三个因子进行多元回归
这里回归之后选择返回阿尔法值最大的前十支股票。
#回归找出阿尔法最大的股票组合
def OLS(df_final):
results = pd.DataFrame()
stocks_return = df_final.iloc[:,3:50]
for i in range(len(stocks_return.columns)):
x = df_final.iloc[:,0:3]
y = stocks_return.iloc[:,i]
X = sm.add_constant(x)
model = sm.OLS(y,X)
result = model.fit()
results[i] = result.params
results.columns = stocks_return.columns
results.rename(index={"const":"Alpha"},inplace=True)
z =results.sort_values(by="Alpha",axis=1,ascending=False)
stocks_lists = z.columns.values.tolist()
top_stocks = stocks_lists[:10]
return top_stocks
最终返回的股票组合如图:
