fama-french五因子模型的python实现
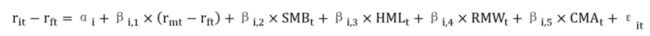
Rmt - Rft :市场风险溢价因子。
SMB(Small minus Big):当SMB增加,即小市值公司股票收益率相对大市值公司股票收益率较好,则若因子暴露βi2>0,投资组合收益率将会更高。从市值的角度解释股票收益率。
HML(High minus Low):BM(账面市值比,市净率的倒数)越低估值越高,若BM高(低估值)的股票相对于BM低(高估值)的股票收益率提升,则HML变大,若若因子暴露βi3>0 ,股票收率会上升。从估值的角度用该因子解释股票收益率。
RMW(盈利好和盈利差的投资组合收益率差异,用息税前利润与与股东权益之比衡量)和CMA(投资高和投资低的投资组合收益率差异,用新增总资产除以上财年末的总资产衡量)通过盈利能力和投资角度来解释股票的收益率。如果因子暴露均反应了预期回报的所有变化,超额收益率阿尔法为0。
导入需要的包和数据:
import pandas as pd
import numpy as np
import datetime
import matplotlib.pyplot as plt
import matplotlib.ticker as ticker
from WindPy import w
w.start()
w.isconnected()
import statsmodels.api as sm
#沪深300成分股代码和财报数据
code=pd.read_csv('./code.csv')
code = code['code']
code = list(code)
通过wind接口获取沪深300成分股的日频数据,数据期间:2020.1.1----2021.12.28
date_list=w.tdays("2020-01-01", "2021-12-28"," ")
close = np.zeros(shape=(len(date_list.Times),0))
close=pd.DataFrame(close)
close.index = pd.to_datetime(date_list.Times)
close = pd.DataFrame(close)
for i in code:
history=w.wsd(i,"close","2020-01-01", "2021-12-28","Fill=Previous")
df=pd.DataFrame(history.Data,index=history.Fields).T #转置数据表
df.index = pd.to_datetime(date_list.Times)
df = pd.DataFrame(df)
df =df.sort_index(ascending=True)
df =df[['CLOSE']]
close[i]=df
#close.to_csv('./close.csv')
cap = np.zeros(shape=(len(date_list.Times),0))
cap =pd.DataFrame(cap)
cap.index = pd.to_datetime(date_list.Times)
for i in code:
history=w.wsd(i,"mkt_cap_ard","2020-01-01", "2021-12-28","Fill=Previous")
df=pd.DataFrame(history.Data,index=history.Fields).T #转置数据表
df.index = pd.to_datetime(date_list.Times)
df = pd.DataFrame(df)
df =df.sort_index(ascending=True)
df =df[['MKT_CAP_ARD']]/100000000
cap[i]=df
#cap.to_csv('./cap.csv')
bm = np.zeros(shape=(len(date_list.Times),0))
bm=pd.DataFrame(bm)
bm.index = pd.to_datetime(date_list.Times)
for i in code:
history=w.wsd(i,"pb_lf","2020-01-01", "2021-12-28","Fill=Previous")
df=pd.DataFrame(history.Data,index=history.Fields).T #转置数据表
df.index = pd.to_datetime(date_list.Times)
df = pd.DataFrame(df)
df =df.sort_index(ascending=True)
df =1/df[['PB_LF']]
bm[i]=df
#bm.to_csv('./bm.csv')半年报数据整合
import math
a=pd.read_csv('./code.csv')
e = a['equity']
e1 = a['equity-1']
equity = np.zeros(shape=(len(date_list.Times),len(code)))
equity=pd.DataFrame(equity)
equity.index = pd.to_datetime(date_list.Times)
equity.columns=code
for i in range(len(code)):
equity.iloc[0:math.ceil(len(date_list.Times)/2+1),i]= e1[i]
equity.iloc[math.ceil(len(date_list.Times)/2+1):len(date_list.Times),i]= e[i]
#equity.to_csv('./equity.csv')
eb = a['ebit']
eb1 = a['ebit-1']
ebit = np.zeros(shape=(len(date_list.Times),len(code)))
ebit=pd.DataFrame(ebit)
ebit.index = pd.to_datetime(date_list.Times)
ebit.columns=code
for i in range(len(code)):
ebit.iloc[0:math.ceil(len(date_list.Times)/2+1),i]= eb1[i]
ebit.iloc[math.ceil(len(date_list.Times)/2+1):len(date_list.Times),i]= eb[i]
#ebit.to_csv('./ebit.csv')
t = a['totasset']
t1 = a['totasset-1']
totasset = np.zeros(shape=(len(date_list.Times),len(code)))
totasset=pd.DataFrame(totasset)
totasset.index = pd.to_datetime(date_list.Times)
totasset.columns=code
for i in range(len(code)):
totasset.iloc[0:math.ceil(len(date_list.Times)/2+1),i]= t1[i]
totasset.iloc[math.ceil(len(date_list.Times)/2+1):len(date_list.Times),i]= t[i]
#totasset.to_csv('./totasset.csv')有效股票池构造
floatlist=cap.index
datelist=pd.to_datetime(floatlist)
#构造ALLapool可交易股票池
allapool=pd.DataFrame(index=floatlist,columns=cap.columns)
allapool[close>0]=1
allapool=allapool.fillna(0)
#allapool为构建的有效股票池(沪深300中可以交易的股票
pro=(ebit/equity)*allapool #构造盈利能力指标、将盈利能力中不可交易的股票去除
cap=cap*allapool#将市值中不可交易的股票去除
bm=bm*allapool#将bm中不可交易的股票去除
totasset=totasset*allapool
构造五因子
cap_d=cap.set_index(datelist)
cap_m=cap_d.groupby([cap_d.index.year,cap_d.index.month]).tail(1)
cap_may=cap_m[cap_m.index.month==5]
bm_d=bm.set_index(datelist)
bm_m=bm_d.groupby([bm_d.index.year,bm_d.index.month]).tail(1)
bm_may=bm_m[bm_m.index.month==5]
pro_d=pro.set_index(datelist)
pro_m=pro_d.groupby([pro_d.index.year,pro_d.index.month]).tail(1)
pro_may=pro_m[pro_m.index.month==5]
totasset_d=totasset.set_index(datelist)
totasset_m=totasset_d.groupby([totasset_d.index.year,totasset_d.index.month]).tail(1)
totasset_dec =totasset_m[totasset_m.index.month==12]
inv = (totasset_dec.shift(-1)-totasset_dec)/totasset_dec
inv = pd.DataFrame(inv,index=totasset_d.index,columns=totasset.columns)
inv = inv.fillna(method='ffill')
inv_may = inv.groupby([inv.index.year,inv.index.month]).tail(1)
inv_may = inv_may[inv_may.index.month==5]
H=bm_may.apply(lambda x:x>= x.quantile(0.7),axis=1)
M=bm_may.apply(lambda x:(x>=x.quantile(0.3))&(x=x.quantile(0.5),axis=1)
S=cap_may.apply(lambda x:x=x.quantile(0.7),axis=1)
W=pro_may.apply(lambda x:x=x.quantile(0.7),axis=1)
C=inv_may.apply(lambda x:x #市值加权持仓函数,计算日频持仓
def get_score(stocklist):
pos=pd.DataFrame(stocklist,index=cap_d.index,columns=cap.columns)
pos=pos.fillna(method="ffill")
pos=pos.set_index(floatlist)
pos=pos*allapool
score=((pos*cap).T/(pos*cap).sum(axis=1)).T#该步为根据市值加权计算持股比例
return score
#构建不同的股票组合,计算各组合的持仓,其他组合同理构造
score_BH=get_score(B&H)
score_BH=score_BH.loc[~score_BH.isna().all(axis=1)]
score_BM=get_score(B&M)
score_BM=score_BM.loc[~score_BM.isna().all(axis=1)]
#........................
#........................
#........................
#........................
#........................
#累计收益,其他组合同理
ret_BM=(close.loc[score_BM.index].pct_change().shift(-1)*score_BM).sum(axis=1)
ret_BM=(ret_BM+1).cumprod()
ret_BH=(close.loc[score_BH.index].pct_change().shift(-1)*score_BH).sum(axis=1)
ret_BH=(ret_BH+1).cumprod()
#........................
#........................
#........................
#........................
#计算因子,市值加权
SMB=(ret_SH+ret_SM+ret_SL)/3-(ret_BH+ret_BM+ret_BL)/3
HML=(ret_SH+ret_BH)/2-(ret_SL+ret_BL)/2
RMW=(ret_SR+ret_BR)/2-(ret_SW+ret_BW)/2
CMA=(ret_SC+ret_BC)/2-(ret_SA+ret_BA)/2不同股票组合收益率与基准收益率比较
#导入沪深300指数作为benchmark
history=w.wsd('000300.SH',"close","2020-01-01", "2021-12-28","Fill=Previous")
df300=pd.DataFrame(history.Data,index=history.Fields).T #转置数据表
df300.index = pd.to_datetime(date_list.Times)
df300 = pd.DataFrame(df300)
df300 =df300.sort_index(ascending=True)
def bmk(df):
df=df["CLOSE"].pct_change()
df=(df+1).cumprod()
return df
bmk_300 = bmk(df300)以SH,BH,SR,BR为例

构建五因子矩阵,回归计算因子暴露。
#选取上证指数和无风险利率的差作为市场溢价因子
history=w.wsd('000001.SH',"close","2021-05-28", "2021-12-28","Fill=Previous")
df=pd.DataFrame(history.Data,index=history.Fields).T #转置数据表
date_list1=w.tdays("2021-05-28", "2021-12-28"," ")
df.index = pd.to_datetime(date_list1.Times)
df =df.sort_index(ascending=True)
mkt = bmk(df) - (1.03**(1/360)-1)
#因子矩阵
X= np.zeros(shape=(len(pd.DataFrame(CMA.values)),5))
X=pd.DataFrame(X)
X.columns=["MKT","SMB","HML","RMW","CMA"]
X["MKT"]=pd.DataFrame(mkt.values[1:])
X["SMB"]=pd.DataFrame(SMB.values[len(SMB)-len(CMA):len(SMB)])
X["HML"]=pd.DataFrame(HML.values[len(HML)-len(CMA):len(HML)])
X["RMW"]=pd.DataFrame(RMW.values[len(RMW)-len(CMA):len(RMW)])
X["CMA"]=pd.DataFrame(CMA.values)
X.index = CMA.index因子正交化处理,可以排除不同因子之间的相互影响。在多元线性回归中,如果某个解释变量和其他解释变量高度相关,则回归系数会有很大的估计误差。
def standardize_z(dt):
mean = dt.mean() # 截面数据均值
std = dt.std() # 截面数据标准差
return (dt - mean)/std
factors_standardize = standardize_z(X) # 标准化
M = (factors_standardize.shape[0]-1)* np.cov(factors_standardize.T.astype(float))
D,U = np.linalg.eig(M) # 获取特征值和特征向量
U = np.mat(U) # 转换为np中的矩阵
d = np.mat(np.diag(D**(-0.5))) # 对特征根元素开(-0.5)指数
S = U * d * U.T # 获取过度矩阵S
factors_orthogonal_mat = np.mat(factors_standardize) * S # 获取对称正交矩阵
factors_orthogonal= pd.DataFrame(factors_orthogonal_mat,columns = X.columns,index=factors_standardize.index)
F_o = factors_orthogonal.fillna(0).corr() # 正交化后的因子相关性
F = X.fillna(0).corr() # 正交化前的因子相关性
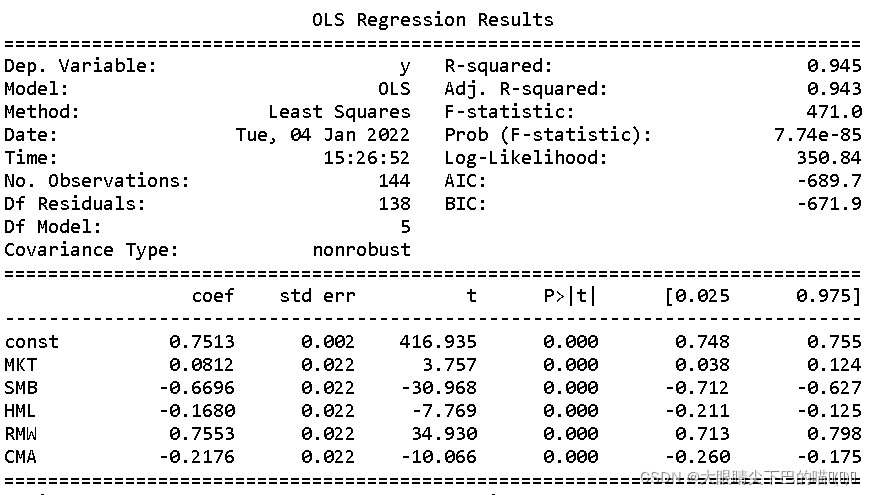
#以中国平安601318.SH为例进行回归计算因子暴露,检验模型效果
import statsmodels.api as sm
history=w.wsd('601318.SH',"close","2021-05-28", "2021-12-28","Fill=Previous")
df=pd.DataFrame(history.Data,index=history.Fields).T #转置数据表
df.index = pd.to_datetime(date_list1.Times)
df = pd.DataFrame(df)
df =df.sort_index(ascending=True)
floatlist1=df.index
datelist1=pd.to_datetime(floatlist1)
bmk1 = bmk(df)
bmk1 = bmk1[1:]
bmk1
X=sm.add_constant(factors_orthogonal)
model = sm.OLS(bmk1.values,X)
result = model.fit()
result.summary()回归结果:因子全部显著,符合预期